This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big DataStorage with HDFS appeared first on Analytics Vidhya.
Datasets are the repository of information that is required to solve a particular type of problem. Also called datastorage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
I found the blog to be a fresh take on the skill in demand by layoff datasets. DeepSeek’s smallpond Takes on Big Data. DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. link] Mehdio: DuckDB goes distributed?
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
A prime example of such patterns is orphaned datasets. These are datasets that exist in a database or datastorage system but no longer have a relevant link or relationship to other data, to any of the analytics, or to the main application — making them a deceptively challenging issue to tackle.
Distributed Data Processing Frameworks Another key consideration is the use of distributed data processing frameworks and data planes like Databricks , Snowflake , Azure Synapse , and BigQuery. These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets.
Kovid wrote an article that tries to explain what are the ingredients of a data warehouse. A data warehouse is a piece of technology that acts on 3 ideas: the data modeling, the datastorage and processing engine. The end-game dataset. And he does it well. In the post Kovid details every idea.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. It stores all the metadata created within a ThoughtSpot instance to enable efficient querying, retrieval, and management of data objects.
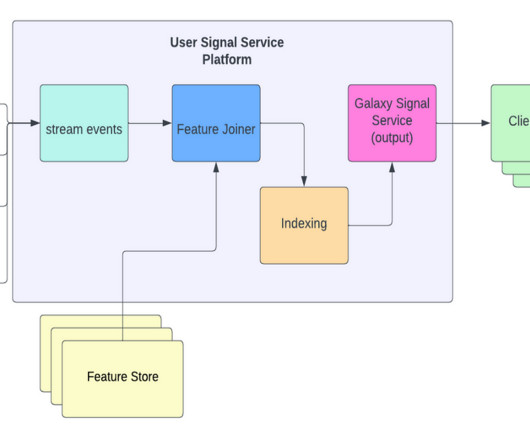
While it is blessed with an abundance of data for training, it is also crucial to maintain a high datastorage efficiency. Therefore, we adopted a hybrid data logging approach, with which the data is logged through both the backend service and the frontend clients. The process is captured in Figure 1.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
Summary Building clean datasets with reliable and reproducible ingestion pipelines is completely useless if it’s not possible to find them and understand their provenance. The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform.
High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies. Data quality can be influenced by various factors, such as data collection methods, data entry processes, datastorage, and data integration.
But, in the majority of cases, Hadoop is the best fit as Spark’s datastorage layer. Fault Tolerance: Apache Spark achieves fault tolerance using a spark abstraction layer called RDD (Resilient Distributed Datasets), which is designed to handle worker node failure. count(): Return the number of elements in the dataset.
The power of pre-commit and SQLFluff —SQL is a query programming language used to retrieve information from datastorages, and like any other programming language, you need to enforce checks at all times. We don't need spaces ( credits ) Data Economy 🤖 Graphext raises $4.6m This is neat. Telmai raises $5.5m
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
These servers are primarily responsible for datastorage, management, and processing. Cloud Computing addresses this by offering scalable storage solutions, enabling Data Scientists to store and access vast datasets effortlessly. The term cloud is referred to as a metaphor for the internet.
Legacy SIEM cost factors to keep in mind Data ingestion: Traditional SIEMs often impose limits to data ingestion and data retention. Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud datastorage capacity.
What is your approach to integrating with the broader ecosystem of datastorage and processing utilities? How is the built in data versioning implemented? What is the user experience for interacting with different versions of datasets? How do you manage the lifecycle of versioned data to allow garbage collection?
Your host is Tobias Macey and today I’m interviewing Davit Buniatyan about Activeloop, a platform for hosting and delivering datasets optimized for machine learning Interview Introduction How did you get involved in the area of data management? Can you describe what Activeloop is and the story behind it?
In order to achieve our targets, we’ll use pre-built connectors available in Confluent Hub to source data from RSS and Twitter feeds, KSQL to apply the necessary transformations and analytics, Google’s Natural Language API for sentiment scoring, Google BigQuery for datastorage, and Google Data Studio for visual analytics.
Iceberg delivers the open table format so that enterprises can put AI to work on their data all in an on-premises setting. This approach brings new compute engines into the fold, adding Spark, Flink, Impala, and NiFi, enabling concurrent access and processing of datasets within Iceberg.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. DatastorageDatastorage follows.
Linear Algebra Linear Algebra is a mathematical subject that is very useful in data science and machine learning. A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence.
It’s not just about having data; it’s about having the right data at the right time in the right context. . Bernard highlighted a number of compelling examples and use cases and also reinforced the fact that with the pandemic at play, datasets that were relevant in January 2020 are totally useless in August.
We set up a separate dataset for each event type indexed by our system, because we want to have the flexibility to scale these datasets independently. In particular, we wanted our KV store datasets to have the following properties: Allows inserts. We need each dataset to store the last N events for a user.
Network operating systems let computers communicate with each other; and datastorage grew—a 5MB hard drive was considered limitless in 1983 (when compared to a magnetic drum with memory capacity of 10 kB from the 1960s). The amount of data being collected grew, and the first data warehouses were developed.
While Parquet based data lake storage, offered by different cloud providers, gave us the immense flexibilities during the initial days of data lake implementations, the evolution of business and technology requirements in current days are posing challenges around those implementations.
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.)
It can provide a complete solution for data exploration, data analysis, data visualization, viz applications, and model deployment at scale. Impala works best for analytical performance with properly designed datasets (well-partitioned, compacted). Monitoring: should I use WXM or Cloudera Manager?
Big Data Technologies: Familiarize yourself with distributed computing frameworks like Apache Hadoop and Apache Spark. Learn how to work with big data technologies to process and analyze large datasets. Data Management: Understand databases, SQL, and data querying languages. Who can Become Data Scientist?
Examples MySQL, PostgreSQL, MongoDB Arrays, Linked Lists, Trees, Hash Tables Scaling Challenges Scales well for handling large datasets and complex queries. Scales efficiently for specific operations within algorithms but may face challenges with large-scale datastorage.
One of ClickHouse’s standout factors is its high performance—due to a combination of factors such as column-based datastorage & processing, data compression, and indexing. This is primarily used to export our marketplace health derived datasets for quick slice and dice in determining marketplace health.
For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task. Amazon S3 : Highly scalable, durable object storage designed for storing backups, data lakes, logs, and static content. Data is accessed over the network and is persistent, making it ideal for unstructured datastorage.
Apache Iceberg is a high-performance open table format developed for modern data lakes. It was designed for large-scale datasets, and within the project, there are many ways to interact with it. It’s something we wanted to fix, but people should be able to not pay attention and just work with their data.
The Key-Value Service The KV data abstraction service was introduced to solve the persistent challenges we faced with data access patterns in our distributed databases. This approach balances the need to retrieve large volumes of data while meeting stringent Service Level Objectives (SLOs) for performance and reliability.
Regardless of the structure they eventually build, it’s usually composed of two types of specialists: builders, who use data in production, and analysts, who know how to make sense of data. Distinction between data scientists and engineers is similar. Data scientist’s responsibilities — Datasets and Models.
As businesses continue to generate massive amounts of data, the need for efficient and scalable datastorage and analysis solutions becomes increasingly important. Two popular options for data warehousing are Google BigQuery and Azure Synapse Analytics, both of which offer powerful features for processing large datasets.
The Role of Big Data Analytics in the Industrial Internet of Things ScienceDirect.com Datasets can have answers to most of your questions. With good research and approach, analyzing this data can bring magical results. Welcome to the world of data-driven insights!
The history of big data takes people on an astonishing journey of big data evolution, tracing the timeline of big data. The Emergence of DataStorage and Processing Technologies A datastorage facility first appeared in the form of punch cards, developed by Basile Bouchon to facilitate pattern printing on textiles in looms.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. What is Big Data analytics? Big Data analytics processes and tools.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content