This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
Datasets are the repository of information that is required to solve a particular type of problem. Also called datastorage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. Can you describe what Activeloop is and the story behind it?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
Vector Search and UnstructuredData Processing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful Big Data tool, Apache Hadoop alone is far from being almighty.
Linear Algebra Linear Algebra is a mathematical subject that is very useful in data science and machine learning. A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence.
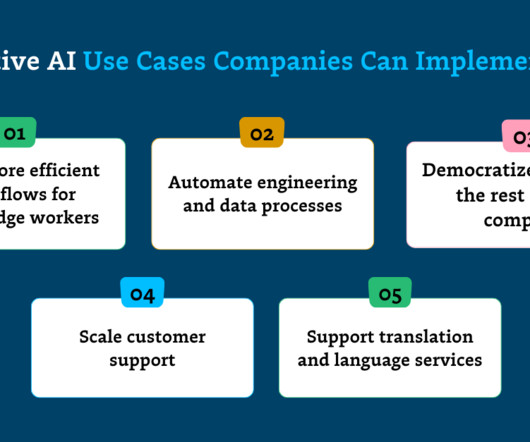
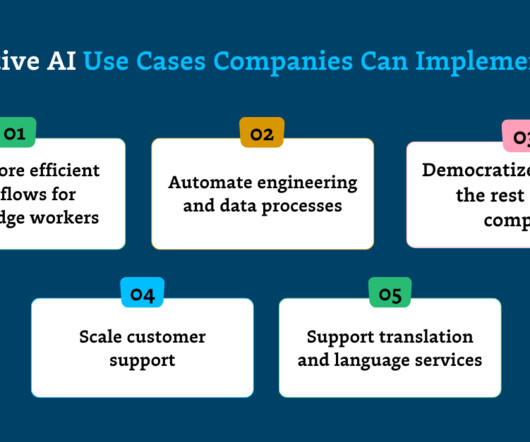
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. DatastorageDatastorage follows.
For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task. Amazon S3 : Highly scalable, durable object storage designed for storing backups, data lakes, logs, and static content. Data is accessed over the network and is persistent, making it ideal for unstructureddatastorage.
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.)
Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. It is also compatible with other popular datastorage that may be deployed on Amazon EC2 instances.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. What is Big Data analytics? Big Data analytics processes and tools.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Data lakehouse architecture is an increasingly popular choice for many businesses because it supports interoperability between data lake formats.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Data lakehouse architecture is an increasingly popular choice for many businesses because it supports interoperability between data lake formats.
View A broader view of data Narrower view of dataDataData is gleaned from diverse sources. Results Broader and exploratory results Targeted results Big Data vs Data Mining Here is a more detailed illustration of the difference between big data and data mining:- 1.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Big data offers several advantages.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
If we look at history, the data that was generated earlier was primarily structured and small in its outlook. A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured.
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. Data Extraction : Begin extraction using methods such as API calls or SQL queries. Batch processing gathers large datasets at scheduled intervals, ideal for operations like end-of-day reports.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
The maximum value of big data can be extracted by integrating the in-memory processing capabilities of SAP HANA (High Performance Analytic Appliance) and the ability of Hadoop to store large unstructureddatasets. “With Big Data, you’re getting into streaming data and Hadoop. .
This approach enables deeper insights into complex datasets that LLMs have not been trained on, demonstrating substantial improvements in data understanding and thematic discovery. link] Nvidia: What Is Sovereign AI?
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection? It’s the first and essential stage of data-related activities and projects, including business intelligence , machine learning , and big data analytics. Find sources of relevant data.
ELT (Extract, Load, Transform) ELT flips the orderstoring raw data first and applying transformations later. Cloud data warehouses like Snowflake , BigQuery , and Redshift have made ELT the go-to choice for massive, messy datasets since they offer scalable compute for on-the-fly transformations. Which One Should You Choose?
RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructureddata. As data processing requirements grow exponentially, NoSQL is a dynamic and cloud friendly approach to dynamically process unstructureddata with ease.IT
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Notice how Snowflake dutifully avoids (what may be a false) dichotomy by simply calling themselves a “data cloud.” With strong G2 scores (4.7
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Unstructureddata sources.
The datasets are usually present in Hadoop Distributed File Systems and other databases integrated with the platform. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data. Apache Hive Architecture Apache Hive has a simple architecture with a Hive interface, and it uses HDFS for datastorage.
For query processing, BigQuery charges $5 per TB of data processed by each query, with the first TB of data per month free. For storage, BigQuery offers up to 10GB of free datastorage per month and $0.02 per additional GB of active storage, making it very economical for storing large amounts of historical data.
Organizations must focus on breaking down silos and integrating all relevant, critical data into on-premises or cloud storage for AI model training and inference. These more complete datasets will both reduce bias and increase accuracy.
BigQuery is a highly scalable data warehouse platform with a built-in query engine offered by Google Cloud Platform. It provides a powerful and easy-to-use interface for large-scale data analysis, allowing users to store, query, analyze, and visualize massive datasets quickly and efficiently. What is Google BigQuery Used for?
MongoDB is a NoSQL database that’s been making rounds in the data science community. MongoDB’s unique architecture and features have secured it a place uniquely in data scientists’ toolboxes globally. Let us see where MongoDB for Data Science can help you. Why Use MongoDB for Data Science?
Data warehousing to aggregate unstructureddata collected from multiple sources. Data architecture to tackle datasets and the relationship between processes and applications. You should be well-versed in Python and R, which are beneficial in various data-related operations. What is COSHH? Explain indexing.
In our earlier articles, we have defined “What is Apache Hadoop” To recap, Apache Hadoop is a distributed computing open source framework for storing and processing huge unstructureddatasets distributed across different clusters. MapReduce breaks down a big data processing job into smaller tasks.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a Data Lake? Consistency of data throughout the data lake.
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Big resources still manage file data hierarchically using Hadoop's open-source ecosystem.
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster datastorage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Data Integration 3.Scalability
Data processing analysts are experts in data who have a special combination of technical abilities and subject-matter expertise. They are essential to the data lifecycle because they take unstructureddata and turn it into something that can be used.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content