This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern businesses are data-driven – they use data in daily operations and decision-making. Data is collected from a variety of datastorage systems, formats, and locations, and data engineers have a hefty job structuring, cleaning, and integrating this data.
Impala only masquerades as an ETL pipeline tool: use NiFi or Airflow instead It is common for Cloudera Data Platform (CDP) users to ‘test’ pipeline development and creation with Impala because it facilitates fast, iterate development and testing. So which open source pipeline tool is better, NiFi or Airflow?
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
Data Integration and Transformation, A good understanding of various data integration and transformation techniques, like normalization, data cleansing, data validation, and data mapping, is necessary to become an ETL developer. Extract, transform, and load data into a target system.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase.
ELT offers a solution to this challenge by allowing companies to extract data from various sources, load it into a central location, and then transform it for analysis. The ELT process relies heavily on the power and scalability of modern datastorage systems. The data is loaded as-is, without any transformation.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a data warehouse ), where it’s kept.
Here are some role-specific skills to consider if you want to become an Azure data engineer: Programming languages are used in the majority of datastorage and processing systems. Data engineers must be well-versed in programming languages such as Python, Java, and Scala.
Real-time data update is possible here, too, along with complete integration with all the top-notch data science tools and programming environments like Python, R, and Jupyter to ease your data manipulation analysis work. Why Use MongoDB for Data Science? js combined with MongoDB for advanced data visualizations.
Therefore, it’s critical to manage data integrity and protect against all credible threats. The Grouparoo reverse Extract, Transform, and Load (ETL) tool takes data from a data warehouse and sends the data to different destinations or tools, empowering business teams to act with verified and trustworthy data.
The step involving data transfer, filtering, and loading into either a data warehouse or data mart is called the extract-transform-load (ELT) process. When dealing with dependent data marts, the central data warehouse already keeps data formatted and cleansed, so ETLtools will do little job.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
Data Architecture and Design: These experts excel in creating effective data structures that meet scalability requirements, ensure optimal datastorage, processing, and retrieval, and correspond with business demands. Azure Data Factory stands at the forefront, orchestrating data workflows.
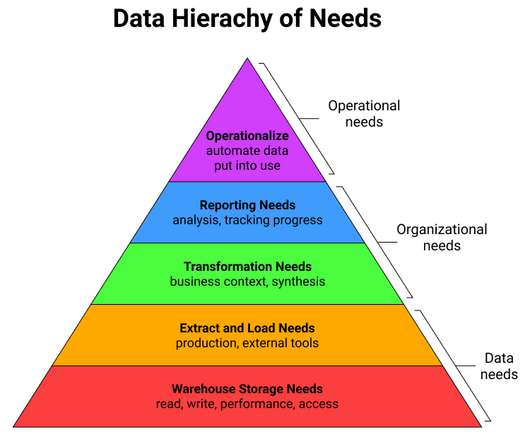
All of this investment in datastorage, loading, transformation, and analysis culminates in automated impact. Reverse ETL with Grouparoo Grouparoo is an open source Reverse ETLtool that makes it easy to act on your data. This action lies at the top of the pyramid because it is the highest leverage activity.
But as businesses pivot and technologies advance, data migrations are—regrettably—unavoidable. Much like a chess grandmaster contemplating his next play, data migrations are a strategic move. A good datastorage migration ensures data integrity, platform compatibility, and future relevance.
Thus, the role demands prior experience in handling large volumes of data. To ensure the datasets are correctly handled, the Big Data Engineer should be thorough with various ETLtools, SQL tools, frameworks like Hadoop and Apache Spark, and programming languages like Python or Java.
Thus, the role demands prior experience in handling large volumes of data. To ensure the datasets are correctly handled, the Big Data Engineer should be thorough with various ETLtools, SQL tools, frameworks like Hadoop and Apache Spark, and programming languages like Python or Java.
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Get familiar with popular ETLtools like Xplenty, Stitch, Alooma, etc.
Additionally, for a job in data engineering, candidates should have actual experience with distributed systems, data pipelines, and related database concepts. Let’s understand in detail: Great demand: Azure is one of the most extensively used cloud platforms, and as a result, Azure Data Engineers are in great demand.
Snowflake can also ingest external tables from on-premise s data sources via S3-compliant datastorage APIs. Batch/file-based data is modeled into the raw vault table structures as the hub, link, and satellite tables illustrated at the beginning of this post.
ETL Processes : Knowledge of ETL (Extract, Transform, Load) processes and familiarity with ETLtools like Xplenty, Stitch, and Alooma is essential for efficiently moving and processing data. Automation : Automation is key for managing large datasets efficiently. The certification cost is $165 USD.
As a result, data engineers working with big data today require a basic grasp of cloud computing platforms and tools. Businesses can employ internal, public, or hybrid clouds depending on their datastorage needs, including AWS, Azure, GCP, and other well-known cloud computing platforms.
DataStorage Specialists A data engineer needs to specialize in datastorage, database management, and working on data warehouses (both cloud and on-premises). The datastorage platform you choose should be optimized to work effectively within your organization's budget constraints.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Datastorage for business intelligence You'll typically need three levels of accessible datastorage for your business intelligence solutions: primary datastorage, data warehouse/historical storage, and analytical databases. You will also need an ETLtool to transport data between each tier.
It involves combining data from disparate sources, removing its redundancies, cleaning up any errors, and aggregating it within a single data store like a data warehouse. The delivery style to consolidate data is common datastorage we’re covering below. How data consolidation works.
Big Data Engineer Big data engineers focus on the infrastructure for collecting and organizing vast amounts of data, building data pipelines, and designing data infrastructures. They manage datastorage and the ETL process. The standard salary range, however, is $95,000 to $154,000.
Get More Practice, More Big Data and Analytics Projects , and More guidance.Fast-Track Your Career Transition with ProjectPro Companies Using HBase - HBase Use Cases In the big data category, HBase has a market share of about 9/1% i.e. approximately 6190 companies use HBase. Pinterest uses HBase to store the graph data.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making raw data efficient to form insights. BigQuery), or another datastorage solution. Excel), a cloud server (e.g.,
Education & Skills Required Bachelor’s or Master’s degree in Computer Science, Data Science , or a related field. Good Hold on MongoDB and data modeling. Experience with ETLtools and data integration techniques. Strong programming skills (e.g., Python, Java). Writing efficient and scalable MongoDB queries.
Amazon EMR owns and maintains the heavy-lifting hardware that your analyses require, including datastorage, EC2 compute instances for big jobs and process sizing, and virtual clusters of computing power. Let’s see what is AWS EMR, its features, benefits, and especially how it helps you unlock the power of your big data.
A fast, secure, and cost-effective, petabyte-scale, managed cloud object storage platform. The two main pricing models are as follows: On-Demand Pricing: you will pay for the capabilities of computing and relevant datastorage by the hour, but it does not involve long-term engagements.
Basic knowledge of ML technologies and algorithms will enable you to collaborate with the engineering teams and the Data Scientists. It will also assist you in building more effective data pipelines. It then loads the transformed data in the database or other BI platforms for use. Hadoop, for instance, is open-source software.
It does away with the requirement to import data from an outside source. Use a few straightforward T-SQL queries to import data from Hadoop, Azure Blob Storage, or Azure Data Lake Store without having to install a third-party ETLtool. Data export and archiving to outside data stores are supported.
Knowledge of the definition and architecture of AWS Big Data services and their function in the data engineering lifecycle, including data collection and ingestion, data analytics, datastorage, data warehousing, data processing, and data visualization. big data and ETLtools, etc.
Below are some big data interview questions for data engineers based on the fundamental concepts of big data, such as data modeling, data analysis , data migration, data processing architecture, datastorage, big data analytics, etc. What is meant by Aggregate Functions in SQL?
It’s like building your own data Avengers team, with each component bringing its own superpowers to the table. Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: DataStorage and Processing : This is your foundation.
Flat Files: CSV, TXT, and Excel spreadsheets are standard text file formats for storing data. Nontechnical users can easily access these data formats without installing data science software. SQL RDBMS: The SQL database is a trendy datastorage where we can load our processed data.
To solve this last mile problem and ensure your data models actually get used by business team members, you need to sync data directly to the tools your business team members use day-to-day, from CRMs like Salesforce to ad networks, email tools and more. You might also be wondering: why now?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content