This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before diving into what makes each company unique, let’s look at the three tools that kept showing up everywhere: Apache Kafka : A distributed event streaming platform that is the standard for moving large amounts of data in real-time. Just like with Netflix, requesting an Uber starts a bigger data journey in the background.
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. It offers a unified solution to real-time data needs any organisation might have. This is where Apache Kafka comes in.
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
Real-time data for operational decision making In the modern data stack, data can move fast enough that it no longer needs to be reserved for those daily metric pulse checks. Data teams can take advantage of Delta live tables , Snowpark , Kafka , Kinesis , micro-batching and more.
The people behind Apache Kafka asked themselves the same question , so they invented the Kappa Architecture, where instead of having both batching and streaming layers, everything is real-time with the whole stream of data stored in a central log like Kafka.
Data Engineering Tools Data engineers need to be comfortable using essential tools for data pipeline management and workflow orchestration, including Apache Kafka, Apache Spark, Airflow, Dagster, dbt, and many more. DataStorage Solutions As we all know, data can be stored in a variety of ways.
To meet this need, people who work in data engineering will focus on making systems that can handle ongoing data streams with little delay. Real-time data analysis is becoming more important, and technologies like Apache Kafka and Apache Flink are getting a lot of attention as powerful ways to handle this fast-paced data processing.
link] Open AI: Model Spec LLM models are slowly emerging as the intelligent datastorage layer. Similar to how data modeling techniques emerged during the burst of relation databases, we started to see similar strategies for fine-tuning and prompt templates. Will they co-exist or fight with each other? On the time will tell us.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
Druid Data Ingestion Our pipeline for the two methods of ingesting data into Druid—the upper process is for batch ingestion, the lower process is for real-time ingestion. Then, they needed to define an ingestion specification which tells Druid how to process the data being ingested. This was our main form of ingestion.
Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Your host is Tobias Macey and today I’m interviewing Tom Kaitchuck about Pravega, an open source datastorage platform optimized for persistent streams Interview Introduction How did you get involved in the area of data management?
This episode promises invaluable insights into the shift from batch to real-time data processing, and the practical applications across multiple industries that make this transition not just beneficial but necessary. Explore the intricate challenges and groundbreaking innovations in datastorage and streaming.
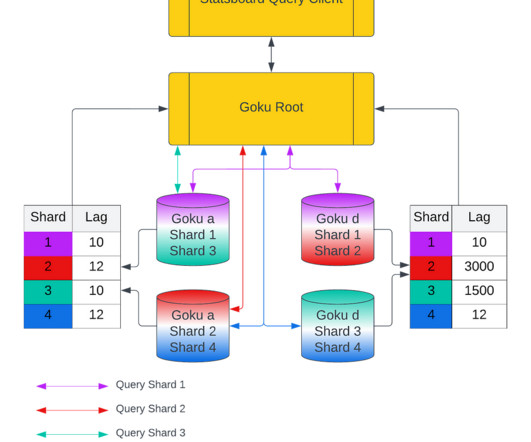
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
Lithium uses a Bring Your Own Host (BYOH) model, allowing developers to integrate custom processors within their services and ensuring data proximity and tenant isolation. The CDC approach addresses challenges like time travel, data validation, performance, and cost by replicating operational data to an AWS S3-based Iceberg Data Lake.
The paper discusses trade-offs among data freshness, resource cost, and query performance. Ref: [link] In the current state of the data infrastructure, we use a combination of multiple specialized datastorage and processing engines to achieve this balance. Presto tried with RaptorX. It doesn’t fly.
As a big data architect or a big data developer, when working with Microservices-based systems, you might often end up in a dilemma whether to use Apache Kafka or RabbitMQ for messaging. Rabbit MQ vs. Kafka - Which one is a better message broker? Table of Contents Kafka vs. RabbitMQ - An Overview What is RabbitMQ?
In order to achieve our targets, we’ll use pre-built connectors available in Confluent Hub to source data from RSS and Twitter feeds, KSQL to apply the necessary transformations and analytics, Google’s Natural Language API for sentiment scoring, Google BigQuery for datastorage, and Google Data Studio for visual analytics.
A trend often seen in organizations around the world is the adoption of Apache Kafka ® as the backbone for datastorage and delivery. This is when CloudBank selected Apache Kafka as technology enabler for their needs. more data per server) and constant retrieval time. Journey from mainframe to cloud.
The first advice is about the documentation readers: data team, business users or other stakeholders. Change Data Capture (CDC) with PostgreSQL and ClickHouse — This is a nice vendor post about CDC with Kafka as movement layer (using Debezium). The post explains well the architecture you need to make it work.
For datastorage , it uses an object store cluster, running on VAST hardware. In this cluster, around 15 PB of raw data and 21 PB of logical data can be stored. More data can be fitted than there is raw storage available thanks to VAST’s data deduplication.
Rockset continuously ingests data streams from Kafka, without the need for a fixed schema, and serves fast SQL queries on that data. We created the Kafka Connect Plugin for Rockset to export data from Kafka and send it to a collection of documents in Rockset. This blog covers how we implemented the plugin.
What are some of the challenges that you and the Cassandra community have faced with the flurry of new datastorage and processing systems that have popped up over the past few years? What do you see as the opportunities for Cassandra over the near to medium term as the cloud continues to grow in prominence?
The powerful platform data security and governance layer, Shared Data Experience (SDX) , is a fundamental part of the open data lakehouse, in the data center just as it is in the cloud. Rolling upgrades are now supported for HDFS, Hive, HBase, Kudu, Kafka, Ranger, YARN, and Ranger KMS.
formats — This is a huge part of data engineering. Picking the right format for your datastorage. In this category I recommend also to have a look at data ingestion (Airbyte, Fivetran, etc.), Main technologies around stream are bus messages like Kafka and processing framework like Flink or Spark on top of the bus.
In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability. Data Validation : Perform quality checks to ensure the data meets quality and accuracy standards, guaranteeing its reliability for subsequent analysis.
From analysts to Big Data Engineers, everyone in the field of data science has been discussing data engineering. When constructing a data engineering project, you should prioritize the following areas: Multiple sources of data (APIs, websites, CSVs, JSON, etc.) Source Code: Yelp Review Analysis 2.
Both companies have added Data and AI to their slogan, Snowflake used to be The Data Cloud and now they're The AI Data Cloud. Accordingly to the press Snowflake and Confluent (Kafka) were also trying to buy Tabular. Buying Tabular — Before the last bullet point, it was already something big.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
Many metadata management systems are simply a service layer on top of a separate datastorage engine. Many metadata management systems are simply a service layer on top of a separate datastorage engine. Can you explain how Marquez is architected and how the design has evolved since you first began working on it?
Master Nodes control and coordinate two key functions of Hadoop: datastorage and parallel processing of data. Worker or Slave Nodes are the majority of nodes used to store data and run computations according to instructions from a master node. Datastorage options. Hadoop nodes: masters and slaves.
We’ve seen a fleet of tools like TextToSQL ; Slack bots to ask questions to your data warehouse , Chat interface for spreadsheets , and even the English SDK for Spark ! I believe the impact of LLM will go further down in the stack with datastorage formats in the coming years. Let me know your thoughts in the comments.
Innovations in Unstructured Data Processing Processing unstructured data at scale remains one of the biggest challenges for modern organizations, prompting innovative solutions in 2024 that blend efficiency, scalability, and accuracy.
Concepts of IaaS, PaaS, and SaaS are the trend, and big companies expect data engineers to have the relevant knowledge. KafkaKafka is one of the most desired open-source messaging and streaming systems that allows you to publish, distribute, and consume data streams. ETL is central to getting your data where you need it.
It hasn’t had its first release yet, but the promise is that it will un-bias your data for you! rc0 – If you like to try new releases of popular products, the time has come to test Kafka 3 and report any issues you find on your staging environment! Change Data Capture at DeviantArt – I think we all know what Debezium is.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
KafkaKafka is an open-source processing software platform. It is used to handle real-time data feeds and build real-time streaming apps. The applications developed by Kafka can help a data engineer discover and apply trends and react to user needs.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing. Apache Kafka.
Rockset offers a number of benefits along with vector search support to create relevant experiences: Real-Time Data: Ingest and index incoming data in real-time with support for updates. Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce datastorage volumes.
Let’s explore what to consider when thinking about data ingestion tools and explore the leading tools in the field. Apache Kafka Apache Kafka is a powerful distributed streaming platform that acts as both a messaging queue and a data ingestion tool. It has a steeper learning curve compared to tools like Fivetran.
link] Meta: Tulip - Schematizing Meta’s data platform Numerous heterogeneous services make up a data platform, such as warehouse datastorage and various real-time systems. The schematization of data plays a vital role in a data platform. The author shares the experience of one such transition.
Because of this, all businesses—from global leaders like Apple to sole proprietorships—need Data Engineers proficient in SQL. NoSQL – This alternative kind of datastorage and processing is gaining popularity. They’ll come up during your quest for a Data Engineer job, so using them effectively will be quite helpful.
Apache Kafka Amazon MSK and Kafka Under the Hood Apache Kafka is an open-source streaming platform. Learn about the AWS-managed Kafka offering in this course to see how it can be more quickly deployed. MongoDB Configuration and Setup Watch an example of deploying MongoDB to understand its benefits as a database system.
Use Snowflake’s native Kafka Connector to configure Kafka topics into Snowflake tables. Snowflake can also ingest external tables from on-premise s data sources via S3-compliant datastorage APIs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content