

8 Essential Data Pipeline Design Patterns You Should Know
Monte Carlo
NOVEMBER 21, 2024
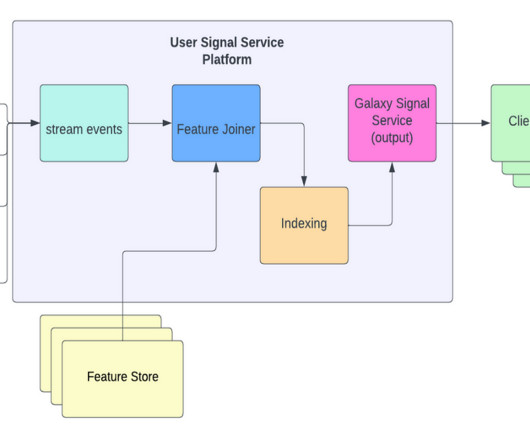
In this guide, we’ll explore the patterns that can help you design data pipelines that actually work. Table of Contents Common Data Pipeline Design Patterns Explained 1. Lambda Architecture Pattern 4. Kappa Architecture Pattern 5. Data Mesh Pattern 8. Batch Processing Pattern 2.









Let's personalize your content