This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The critical question is: what exactly are these data warehousing tools, and how many different types are available? This article will explore the top seven data warehousing tools that simplify the complexities of datastorage, making it more efficient and accessible. Table of Contents What are Data Warehousing Tools?
What is a MachineLearning Pipeline? A machinelearning pipeline helps automate machinelearning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. Table of Contents What is a MachineLearning Pipeline?
Machinelearning is revolutionizing how different industries function, from healthcare to finance to transportation. In this blog, we'll explore some exciting machinelearning case studies that showcase the potential of this powerful emerging technology. So, let's get started!
The world today is flooded with applications of machinelearning and artificial intelligence. Machinelearning applications are found in many areas, such as digital assistants or cancer detectors. Hence, machinelearning has become a core aspect of everyday life, making it an essential topic to acknowledge.
Machinelearning engineers often face the tough challenge of turning abstract business problems into practical machinelearning solutions. Data Preprocessing “Volume of data isn’t everything,” says Dudon Wai, product manager at Canvass. “It can be garbage in, garbage out.
Implementing machinelearning projects has its own challenges. From data quality issues to algorithm selection and model interpretation, machinelearning engineers must navigate numerous challenges in deploying and monitoring machinelearning systems to successfully deploy a machinelearning model in production.
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machinelearning models. Apache HBase is an effective datastorage system for many workflows but accessing this data specifically through Python can be a struggle.
When you click on a show in Netflix, you’re setting off a chain of data-driven processes behind the scenes to create a personalized and smooth viewing experience. As soon as you click, data about your choice flows into a global Kafka queue, which Flink then uses to help power Netflix’s recommendation engine.
Managing the data that represents organizational knowledge is easy for any developer and does not require exhaustive cycles of data science work. Utilizing Pinecone for vector datastorage over an in-house open-source vector store can be a prudent choice for organizations.
Also called datastorage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all MachineLearning models. Machinelearning uses algorithms that comb through data sets and continuously improve the machinelearning model.
Good knowledge of various machinelearning and deep learning algorithms will be a bonus. Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc. Good communication skills as a data engineer directly works with the different teams. For machinelearning, an introductory text by Gareth M.
13 Top Careers in AI for 2025 From MachineLearning Engineers driving innovation to AI Product Managers shaping responsible tech, this section will help you discover various roles that will define the future of AI and MachineLearning in 2024. Enter the MachineLearning Engineer (MLE), the brain behind the magic.
Institutional Considerations While I am on this topic of data management, I should mention—I recently started a new role! I am the first senior machinelearning engineer at DataGrail, a company that provides a suite of B2B services helping companies secure and manage their customer data. You’re using the data, of course!
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructured data ready for machinelearning. Can you describe what Activeloop is and the story behind it?
The demand for data-related roles has increased massively in the past few years. Companies are actively seeking talent in these areas, and there is a huge market for individuals who can manipulate data, work with large databases and build machinelearning algorithms. What is an AI Engineer? What does an AI Engineer do?
From on-prem to cloud : Moving from physical data centers to a cloud-based infrastructure unlocks huge potential for automotive companies. Enabling OEMs to scale datastorage and processing capabilities, cloud computing also facilitates collaboration across teams globally.
ETL is a process that involves data extraction, transformation, and loading from multiple sources to a data warehouse, data lake, or another centralized data repository. An ETL developer designs, builds and manages datastorage systems while ensuring they have important data for the business.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Let’s dive into the tools necessary to become an AI data engineer.
AWS DevOps offers an innovative and versatile set of services and tools that allow you to manage, scale, and optimize big data projects. With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex data processing pipelines, machinelearning models, and more.
Snowflake Features that Make Data Science Easier Here are three Snowflake attributes that make running successful data science projects easier for businesses- 1. Centralized Source of Data When training machinelearning models, data scientists must consider a wide range of data.
Since data needs to be accessible easily, organizations use Amazon Redshift as it offers seamless integration with business intelligence tools and helps you train and deploy machinelearning models using SQL commands. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties.
Using familiar SQL as Athena queries on raw data stored in S3 is easy; that is an important point, and you will explore real-world examples related to this in the latter part of the blog. It is compatible with Amazon S3 when it comes to datastoragedata as there is no requirement for any other storage mechanism to run the queries.
But most data leaders quickly understand the value unlock that comes from being able to more directly support real-time operational decision making. Instead, they work with domain teams to understand data quality requirements and translate those into SQL rules, or data tests.
Snowflake Horizon provides a built-in framework for data security, compliance and privacy management for all data stored within Snowflake, for use cases such as marketing campaign activation via Hightouch. Leverage native machinelearning (ML) and artificial intelligence (AI).
Introduction to Teradata VantageCloud Lake on AWS Teradata VantageCloud Lake, a comprehensive data platform, serves as the foundation for our data mesh architecture on AWS. The data mesh architecture Key components of the data mesh architecture 1.
Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. Use machinelearning algorithms to predict winning probabilities or player success in upcoming matches. venues or weather).
Azure Synapse and Databricks are two of the most popular data warehouse platforms that offer features of ETL pipelines, machinelearning , and enterprise data warehousing. But when it comes to choosing the two platforms, it is up to the organization to assess its data management needs.
An AWS Data Scientist is a professional who combines expertise in data analysis, machinelearning , and AWS technologies to extract meaningful insights from vast datasets. They are responsible for designing and implementing scalable, cost-effective AWS solutions, ensuring organizations can make data-driven decisions.
For full-stack data science mastery, you must understand data management along with all the bells and whistles of machinelearning. This high-level overview is a road map for the history and current state of the expansive options for datastorage and infrastructure solutions.
Machinelearning (ML) is only possible because of all the data we collect. However, with data coming from so many different sources, it doesn’t always come in a format that’s easy for ML models to understand. Why Prepare Data for MachineLearning Models? As the saying goes: “Garbage in, garbage out.”
AWS boasts a comprehensive suite of scalable and secure offerings, while GCP leverages Google's expertise in data analytics and machinelearning. Google Cloud platform offers more than 100 services, including cloud computing, storage, machinelearning, resource monitoring and management, networking, and application development.
The benefits it offers start from data management and manipulation to machinelearning tools on the GCP platform. GCP offers 90 services that span computation, storage, databases, networking, operations, development, data analytics , machinelearning , and artificial intelligence , to name a few.
GCP provides a full range of computing services, including tools for managing GCP costs, governing data, providing web content and online video, and using AI and machinelearning. Who is a GCP Data Engineer? A professional data engineer designs systems to gather and navigate data.
It is also possible to use BigQuery to directly export data from Google SaaS apps, Amazon S3, and other data warehouses, such as Teradata and Redshift. Furthermore, BigQuery supports machinelearning and artificial intelligence, allowing users to use machinelearning models to analyze their data.
In addition to analytics and data science, RAPIDS focuses on everyday data preparation tasks. This features a familiar DataFrame API that connects with various machinelearning algorithms to accelerate end-to-end pipelines without incurring the usual serialization overhead.
FAQs on Data Engineering Skills Mastering Data Engineering Skills: An Introduction to What is Data Engineering Data engineering is the process of designing, developing, and managing the infrastructure needed to collect, store, process, and analyze large volumes of data. 2) Does data engineering require coding?
If you are keen on learning how to apply DevOps for MachineLearning on Microsoft Azure, then this blog is for you. With data being the buzzword of the decade and machinelearning being applied in the real world more than ever, why do nearly 85 to 95% of machinelearning projects fail to deliver?
.” said the McKinsey Global Institute (MGI) in its executive overview of last month's report: "The Age of Analytics: Competing in a Data-Driven World." 2016 was an exciting year for big data with organizations developing real-world solutions with big data analytics making a major impact on their bottom line.
AWS Data Engineering is one of the core elements of AWS Cloud in delivering the ultimate solution to users. AWS Data Engineering helps big data professionals manage Data Pipelines, Data Transfer, and DataStorage. Table of Contents Who is an AWS Data Engineer? What Does an AWS Data Engineer Do?
Apache Spark has become a cornerstone technology in the world of big data and analytics. Learning Spark opens up a world of opportunities in data processing, machinelearning, and more. Familiarize yourself with concepts like distributed computing, datastorage, and data processing frameworks.
Snowflake has a market share of 18.33% in the current industry because of its disruptive architecture for datastorage, analysis, processing, and sharing. In contrast, Databricks is less expensive when it comes to datastorage since it gives its clients different storage environments that can be configured for specific purposes.
Source: [link] Key Features Apache Kafka stands out with its ability to deliver messages at network-limited throughput, achieved through a cluster of machines with impressively low latencies, as low as 2ms. Apache Kafka offers a robust solution for permanent datastorage in a distributed, durable, and fault-tolerant cluster.
Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis , Amazon Redshift, Amazon S3, and Amazon MSK. It is also compatible with other popular datastorage that may be deployed on Amazon EC2 instances.
With over 200 native connectors, it facilitates seamless data connectivity across on-premises and cloud sources, ensuring robust data integration capabilities. Data Science The data science component streamlines the process of building, deploying, and operationalizing machinelearning models.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









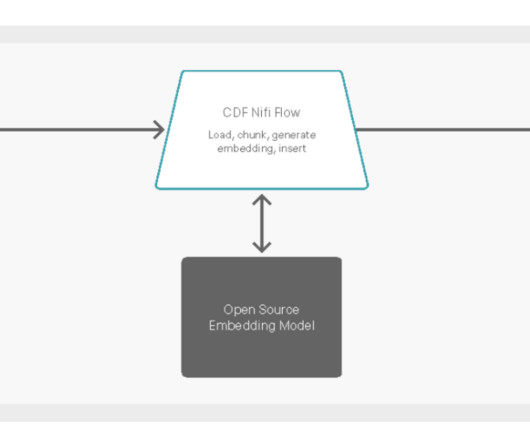



















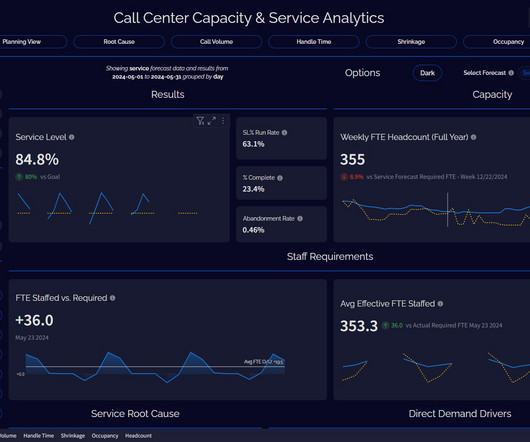














Let's personalize your content