This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Summary With the increased ease of gaining access to servers in data centers across the world has come the need for supporting globally distributed datastorage. With the first wave of cloud era databases the ability to replicate information geographically came at the expense of transactions and familiar query languages.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription TimescaleDB, from your friends at Timescale, is the leading open-source relationaldatabase with support for time-series data. Time-series data is time stamped so you can measure how a system is changing.
If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. Look for a suitable big data technologies company online to launch your career in the field.
What has changed in recent years to allow for the current proliferation of graph oriented storagesystems? What are some of the common uses of graph storagesystems? How does the query interface and datastorage in DGraph differ from other options? What are some of the common uses of graph storagesystems?
You don’t need to archive or clean data before loading. The system automatically replicates information to prevent data loss in the case of a node failure. Master Nodes control and coordinate two key functions of Hadoop: datastorage and parallel processing of data. A file stored in the system ?an’t
Summary One of the biggest challenges for any business trying to grow and reach customers globally is how to scale their datastorage. FaunaDB is a cloud native database built by the engineers behind Twitter’s infrastructure and designed to serve the needs of modern systems.
This programming language is used for general purposes and is a robust system. Here are some things that you should learn: Recursion Bubble sort Selection sort Binary Search Insertion Sort Databases and Cache To build a high-performance system, programmers need to rely on the cache. Put the system logic in order.
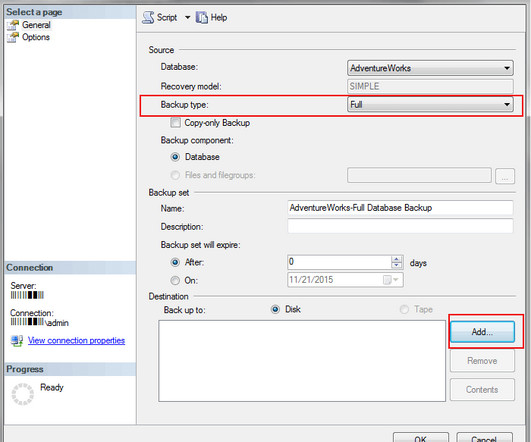
Microsoft SQL Server (MSSQL) is a popular relationaldatabase management application that facilitates datastorage and access in your organization. Backing up and restoring your MSSQL database is crucial for maintaining data integrity and availability. In the event of system failure or […]
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. DatastorageDatastorage follows.
Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing. Data Loading : Load transformed data into the target system, such as a data warehouse or data lake. Used for identifying and cataloging data sources.
The tuple is one of the most used components of database management systems (or DBMS). A tuple in a database management system is essentially a row with linked data about a certain entity (it can be any object). The relational model depicts the database as a collection of relations.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
Businesses need to efficiently store, handle, and analyze the growing amounts of data they produce. This article will explore the two prominent datastoragesystems organizations use: Hive and PostgreSQL.
Meta’s Systematic Code and Asset Removal Framework (SCARF) has a subsystem for identifying and removing unused data types. SCARF scans production datasystems to identify tables or assets that are unused and safely removes them. Each represents a class of data — not individual records.
A database is a structured data collection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloud storage keeps larger datasets. According to a database model, the organization of data is known as database design.
In this article, I will explore the unique roles of database vs data structure, uncovering their differences and how they work together to handle information in the world of computers. What is a Database? Table modeling of the data in standard databases facilitates efficient searching and processing.
The transition from mainframe systems to a cloud-first strategy can be complicated. Migrating applications and data are potentially expensive, time-consuming, and fraught with risk. Many organizations adopt a long-term approach, leveraging the relative strengths of both mainframe and cloud systems.
For datastorage, the database is one of the fundamental building blocks. There are many kinds of databases available, each with its strengths and weaknesses. This includes the database vendor, underlying operating system, and the hardware infrastructure components.
NoSQL Databases NoSQL databases are non-relationaldatabases (that do not store data in rows or columns) more effective than conventional relationaldatabases (databases that store information in a tabular format) in handling unstructured and semi-structured data.
For instance, we are using the D8 v3 instance type for COD workloads on Azure and we calculated the savings opportunity based on 1-year reserved pricing for RHEL instances, since Azure doesn’t offer the 3-year reserved pricing billing type for most of the regions where RHEL-based Virtual Machines are available: Object Storage.
RelationalDatabases – The fundamental concept behind databases, namely MySQL, Oracle Express Edition, and MS-SQL that uses SQL, is that they are all RelationalDatabase Management Systems that make use of relations (generally referred to as tables) for storing data.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. And most of this data has to be handled in real-time or near real-time.
PostgreSQL, also known as Postgres, is an advanced object-relationaldatabase management system (ORDBMS) used for datastorage, retrieval, and management. It is available on the Azure platform in a PaaS model (Platform as a Service) through the Azure Database for PostgreSQL service.
SQL databases are one of the most widely used types of databasesystems available. SQL is a structured query language that these databases enable users to utilize for data management, retrieval, and storage. A number of SQL databases are available. However SQLite is one of the most widely used.
In the world of databases, data independence plays a vital role in making sure the flexibility and adaptability of databasesystems. Data independence tells us about the ability to modify the database schema or organization without affecting the applications that use the data.
While this “data tsunami” may pose a new set of challenges, it also opens up opportunities for a wide variety of high value business intelligence (BI) and other analytics use cases that most companies are eager to deploy. . Traditional data warehouse vendors may have maturity in datastorage, modeling, and high-performance analysis.
Making decisions in the database space requires deciding between RDBMS (RelationalDatabase Management System) and NoSQL, each of which has unique features. RDBMS uses SQL to organize data into structured tables, whereas NoSQL is more flexible and can handle a wider range of data types because of its dynamic schemas.
Database applications also help in data-driven decision-making by providing data analysis and reporting tools. In this blog, we will deep dive into databasesystem applications in DBMS, and their components and look at a list of database applications. What are Database Applications?
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. Any Azure Data Engineer must have experience with Azure’s datastorage options, including Azure Cosmos DB, Azure Data Lake Storage, and Azure Blob Storage.
It aims to streamline data ingestion, processing, and analytics by automating and integrating various data workflows. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. Data Sources Data sources are the backbone of any DataOps architecture.
This blog will guide you through the best data modeling methodologies and processes for your data lake, helping you make informed decisions and optimize your data management practices. What is a Data Lake? What are Data Modeling Methodologies, and Why Are They Important for a Data Lake?
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon RelationalDatabase Service.
Amazon Aurora is a relationaldatabase engine compatible with MySQL and PostgreSQL. Data Plane Aurora uses these operations in its datastorage and retrieval. To improve data high availability and durability, it is logged and stored continuously in Amazon S3. You will also know when to use it for your apps.
It is designed to support business intelligence (BI) and reporting activities, providing a consolidated and consistent view of enterprise data. Data warehouses are typically built using traditional relationaldatabasesystems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
However, managing data can be a challenging task, especially when dealing with large amounts of information. This is where database management systems come in handy. A database management system (DBMS) is a software system that helps organize, store and manage information efficiently.
The following are some of the essential foundational skills for data engineers- With these Data Science Projects in Python , your career is bound to reach new heights. A data engineer should be aware of how the data landscape is changing. Explore the distinctions between on-premises and cloud data solutions.
This type of developer works with the Full stack of a software application, beginning with Front end development and going through back-end development, Database, Server, API, and version controlling systems. Git is an open source version control system that a developer/ development companies use to manage projects.
A Database Management System is a very prominent software that allows its users to store, organize, and manage enormous volumes of data efficiently and securely. It acts as an interface between the users and the database storing data, providing a seamless and smooth interface to access, change, and display data.
Because of this, standard transactional databases aren’t always the best fit. Instead, databases such as DynamoDB have been designed to manage the new influx of data. DynamoDB is an Amazon Web Services databasesystem that supports data structures and key-valued cloud services.
The following are some of the fundamental foundational skills required of data engineers: A data engineer should be aware of changes in the data landscape. They should also consider how datasystems have evolved and how they have benefited data professionals.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content