This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big DataStorage with HDFS appeared first on Analytics Vidhya.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Introduction The Hadoop Distributed File System (HDFS) is a Java-based file system that is Distributed, Scalable, and Portable. Due to its lack of POSIX conformance, some believe it to be datastorage instead.
When you click on a show in Netflix, you’re setting off a chain of data-driven processes behind the scenes to create a personalized and smooth viewing experience. As soon as you click, data about your choice flows into a global Kafka queue, which Flink then uses to help power Netflix’s recommendation engine.
Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. There are also newer AI/ML applications that need datastorage, optimized for unstructured data using developer friendly paradigms like Python Boto API.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Key parts of datasystems: 2.1. Data flow design 2.3. Data processing design 2.5. Datastorage design 2.7. Introduction If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools. Introduction 2. Requirements 2.2.
In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full data architecture for a Data Warehouse system. I went with Apache Druid for datastorage, Apache Superset for querying and Apache Airflow as a task orchestrator.
Part of this emphasis extends to helping enterprises deal with their data and overall cloud connectivity as well as local networks. At the same time, operators are also becoming more data- and cloud-centric themselves. The focus has also been hugely centred on compute rather than datastorage and analysis.
A streaming ETL for Snowflake approach loads data to Snowflake from diverse sources such as transactional databases, security systems logs, and IoT sensors/devices in real time , while simultaneously meeting scalability, latency, security, and reliability requirements.
But what does an AI data engineer do? AI data engineers play a critical role in developing and managing AI-powered datasystems. Table of Contents What Does an AI Data Engineer Do? DataStorage Solutions As we all know, data can be stored in a variety of ways. What are they responsible for?
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. What is metadata?
The information system is a very vast concept that encompasses several aspects like database management, the communication system, various devices, several connections, the internet, collection, organization, and storing data and other information-related applications that are typically used in a business forum.
Amazon Elastic File System (EFS) is a service that Amazon Web Services ( AWS ) provides. It is intended to deliver serverless, fully-elastic file storage that enables you to share data independently of capacity and performance. All these features make it easier to safeguard your data and also keep to the legal requirements.
Instead of handling each piece of data as it arrives, you collect it all and process it in scheduled chunks. It’s like having a designated “laundry day” for your data. This approach is super cost-efficient because you’re not running your systems constantly. The downside?
When you are a data engineer you're getting paid to build systems that people can rely on. Big data technologies are dead—bye Zookeeper 👋—but data generated by systems are still massive and is the modern data stack relevant to answer this need in storage and processing?
DeepSeek continues to impact the Data and AI landscape with its recent open-source tools, such as Fire-Flyer File System (3FS) and smallpond. The industry relies more or less on S3 as a de facto datastorage, and I found the experimentation on optimizing the S3 read optimization to be an excellent reference.
We focused on building end-to-end AI systems with a major emphasis on researcher and developer experience and productivity. Grand Teton builds on the many generations of AI systems that integrate power, control, compute, and fabric interfaces into a single chassis for better overall performance, signal integrity, and thermal performance.
Evals are introduced to evaluate LLM responses through various techniques, including self-evaluation, using another LLM as a judge, or human evaluation to ensure the system's behavior aligns with intentions. It employs a two-tower model approach to learn query and item embeddings from user engagement data.
In this blog, we’ll dive into the top 7 mobile security threats that are putting both personal and organizational data at risk and explore effective strategies to defend against these dangers. Operating System and App Vulnerabilities No operating system is immune to flaws.
From his early days at Quora to leading projects at Facebook and his current venture at Fennel (a real-time feature store for ML), Nikhil has traversed the evolving landscape of machine learning engineering and machine learning infrastructure specifically in the context of recommendation systems.
In order to improve your data infra you should sometimes try to occasionally kill your data stack , chaos engineering is something that helps discover issues. This goes further than being a data-driven enterprise , you have to put in place a framework the puts data measurement at every product choice, resulting in maturity increase.
If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. Look for a suitable big data technologies company online to launch your career in the field.
While the modern data stack has undeniably revolutionized data management with its cloud-native approach, its complexities and limitations are becoming increasingly apparent. Agent systems powered by LLMs are already transforming how we code and interact with data. Data engineering followed a similar path.
Prior to data powering valuable data products like machine learning models and real-time marketing applications, data warehouses were mainly used to create charts in binders that sat off to the side of board meetings. For complex systems, it is the only way to identify issues early and trace them back to the root cause.
Automate Data Transformation and Orchestration: Automate data cleaning and transformation tasks using a data automation tool like Ascend to reduce manual effort and improve data consistency. API-Driven Integration Incorporating API-driven integration is also essential for future-proofing data pipelines.
Data center deployment Once we’ve chosen a GPU and system, the task of placing them in a data center for optimal usage of resources (power, cooling, networking, etc.) Storage We need efficient data-storage solutions to store the vast amounts of data used in model training.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth data processing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. This limited pilot system greatly reduced the time spent by our users to manually analyze the content. Maintaining disparate systems posed a challenge. Processing took several hours to complete.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. DatastorageDatastorage follows.
For example, the datastoragesystems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. The principles emphasize machine-actionability (i.e.,
The opportunities are endless in this field — you can get a job as an operation analyst, quantitative analyst, IT systems analyst, healthcare data analyst, data analyst consultant, and many more. A Python with Data Science course is a great career investment and will pay off great rewards in the future. Choose data sets.
A complete view of the enterprise Now, Molex can ingest large volumes of data from customer interactions, SAP production lines, and financial transactions with Snowflake’s cloud-based platform. Data shares are secure, configurable, and controlled completely by the provider account. Access to a share can be revoked at any time.
Summary The Cassandra database is one of the first open source options for globally scalable storagesystems. Since its introduction in 2008 it has been powering systems at every scale. Cassandra is primarily used as a system of record. Since its introduction in 2008 it has been powering systems at every scale.
Point solutions are still used every day in many enterprise systems, but as IT continues to evolve, the platform approach beats point solutions in almost every use case. A few years ago, there were several choices of data deduplication apps for storage, and now, it’s a standard function in every system.
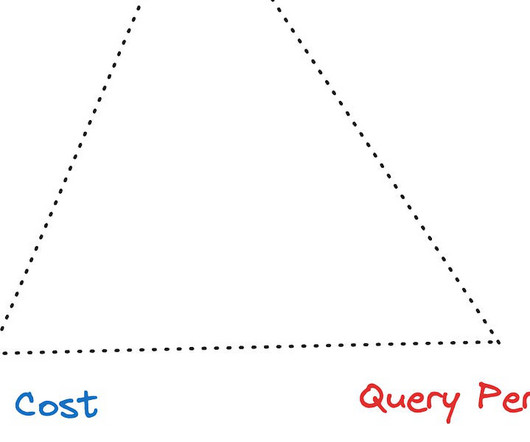
The paper discusses trade-offs among data freshness, resource cost, and query performance. Ref: [link] In the current state of the data infrastructure, we use a combination of multiple specialized datastorage and processing engines to achieve this balance. Here are a few interesting reads. What is Next?
As your systems age, operational costs grow – including the cost of staffing highly specialized individuals to manage legacy technologies. For example, many organizations are now sunsetting older, more expensive systems in favor of cloud technologies that are more widely understood and easier to staff for.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription TimescaleDB, from your friends at Timescale, is the leading open-source relational database with support for time-series data. Time-series data is time stamped so you can measure how a system is changing.
Managing the data that represents organizational knowledge is easy for any developer and does not require exhaustive cycles of data science work. Utilizing Pinecone for vector datastorage over an in-house open-source vector store can be a prudent choice for organizations.
As advanced use cases, like advanced driver assistance systems featuring lane change departure detection, advanced vehicle diagnostics, or predictive maintenance move forward, the existing infrastructure of the connected car is being stressed. billion in 2019, and is projected to reach $225.16 billion by 2027, registering a CAGR of 17.1%
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective datastoragesystem for many workflows but accessing this data specifically through Python can be a struggle.
Replace legacy: It’s hard to avoid having “legacy” systems/applications or versions since technology advancements are moving so fast these days. We see this consistently in the data platform/datastorage space. . Replacing redundant datastorage is a clear opportunity in this category.
For datastorage , it uses an object store cluster, running on VAST hardware. In this cluster, around 15 PB of raw data and 21 PB of logical data can be stored. More data can be fitted than there is raw storage available thanks to VAST’s data deduplication.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content