This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. The data you’re looking for is already in your data warehouse and BI tools.
But what does an AI data engineer do? AI data engineers play a critical role in developing and managing AI-powered datasystems. Table of Contents What Does an AI Data Engineer Do? DataStorage Solutions As we all know, data can be stored in a variety of ways. What are they responsible for?
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases. There are also newer AI/ML applications that need datastorage, optimized for unstructureddata using developer friendly paradigms like Python Boto API.
Prior to data powering valuable data products like machine learning models and real-time marketing applications, data warehouses were mainly used to create charts in binders that sat off to the side of board meetings. For complex systems, it is the only way to identify issues early and trace them back to the root cause.
While the modern data stack has undeniably revolutionized data management with its cloud-native approach, its complexities and limitations are becoming increasingly apparent. Agent systems powered by LLMs are already transforming how we code and interact with data. Data engineering followed a similar path.
We’re excited to introduce vector search on Rockset to power fast and efficient search experiences, personalization engines, fraud detection systems and more. Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data.
For example, the datastoragesystems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. The principles emphasize machine-actionability (i.e.,
As advanced use cases, like advanced driver assistance systems featuring lane change departure detection, advanced vehicle diagnostics, or predictive maintenance move forward, the existing infrastructure of the connected car is being stressed. billion in 2019, and is projected to reach $225.16 billion by 2027, registering a CAGR of 17.1%
The opportunities are endless in this field — you can get a job as an operation analyst, quantitative analyst, IT systems analyst, healthcare data analyst, data analyst consultant, and many more. A Python with Data Science course is a great career investment and will pay off great rewards in the future. Choose data sets.
Automated Data Classification and Governance LLMs are reshaping governance practices. Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. DatastorageDatastorage follows.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
These programs and technologies include, among other things, servers, databases, networking, and datastorage. Cloud-based storage enables you to store files in a remote database as opposed to a local or proprietary hard drive. A web data center server’s hardware and operating system are called a “cloud platform.”
Statistics are used by data scientists to collect, assess, analyze, and derive conclusions from data, as well as to apply quantifiable mathematical models to relevant variables. Microsoft Excel An effective Excel spreadsheet will arrange unstructureddata into a legible format, making it simpler to glean insights that can be used.
IBM has developed a system called IBM Cloud Pak for data. It allows businesses to bypass unused data and use only meaningful data to generate results. As a result, it puts data to use quickly and effectively. IBM is one of the best companies to work for in Data Science.
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructureddata and documents.
Also called datastorage areas , they help users to understand the essential insights about the information they represent. Machine Learning without data sets will not exist because ML depends on data sets to bring out relevant insights and solve real-world problems.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
Formed in 2022, the company provides a simple, SaaS-based drag and drop interface that democratizes AI data analytics, allowing everyone within the business to solve problems and create value faster. Along with its seamless integration with other systems helping to avoid vendor lock-in. The result?
Amazon S3 : Highly scalable, durable object storage designed for storing backups, data lakes, logs, and static content. Data is accessed over the network and is persistent, making it ideal for unstructureddatastorage.
You don’t need to archive or clean data before loading. The system automatically replicates information to prevent data loss in the case of a node failure. Master Nodes control and coordinate two key functions of Hadoop: datastorage and parallel processing of data. A file stored in the system ?an’t
Every day, enormous amounts of data are collected from business endpoints, cloud apps, and the people who engage with them. Cloud computing enables enterprises to access massive amounts of organized and unstructureddata in order to extract commercial value. It allows you to improve the system's performance.
Today, companies from all around the world are witnessing an explosion of event generation coming from everywhere, including their own internal systems. These systems emit logs containing valuable information that needs to be part of any company strategy. But cloud alone doesn’t solve all the problems.
Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing. Data Loading : Load transformed data into the target system, such as a data warehouse or data lake. Used for identifying and cataloging data sources.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. In this case, alternatives such as data lakes or data lakehouses would be better.
It is designed to support business intelligence (BI) and reporting activities, providing a consolidated and consistent view of enterprise data. Data warehouses are typically built using traditional relational database systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. In this case, alternatives such as data lakes or data lakehouses would be better.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. In this case, alternatives such as data lakes or data lakehouses would be better.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructureddata. As data processing requirements grow exponentially, NoSQL is a dynamic and cloud friendly approach to dynamically process unstructureddata with ease.IT
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing. Hadoop architecture layers.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems.
ELT offers a solution to this challenge by allowing companies to extract data from various sources, load it into a central location, and then transform it for analysis. The ELT process relies heavily on the power and scalability of modern datastoragesystems. The data is loaded as-is, without any transformation.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. They identify business problems and opportunities to enhance the practices, processes, and systems within an organization. Data Analyst Scientist.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. It is also compatible with other popular datastorage that may be deployed on Amazon EC2 instances. Establish a crawler schedule.
Pipeline-centric Pipeline-centric data engineers work with Data Scientists to help use the collected data and mostly belong in midsize companies. They are required to have deep knowledge of distributed systems and computer science. Since the evolution of Data Science, it has helped tackle many real-world challenges.
The larger the company, the more data it has to generate actionable insights. Because it is scattered across disparate systems, hardly available for analytical apps. Evidently, common storage solutions fail to provide a unified data view and meet the needs of companies for seamless data flow. Data hub architecture.
The integration of data from separate sources becomes a self-consistent data set with the removal of duplications and flagging of inconsistencies or, if possible, their resolution. Datastorage uses a non-volatile environment with strict management controls on the modification and deletion of data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














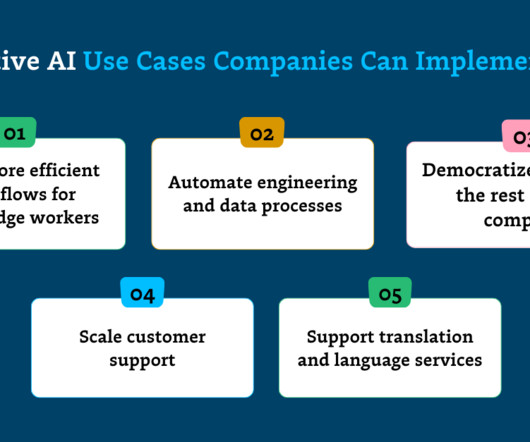




















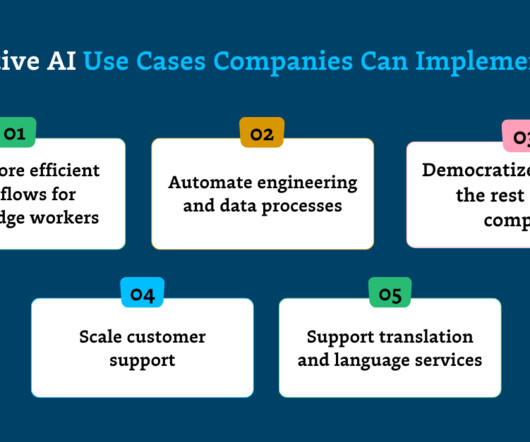














Let's personalize your content