This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. Pandera, a datavalidation library for dataframes, now supports Polars.
[link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified datawarehouse. GetYourGuide discusses migrating its Business Intelligence (BI) data source from Snowflake to Databricks, achieving a 20% cost reduction. million entities per second in production.
The Definitive Guide to DataValidation Testing Datavalidation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. It’s also important to understand the limitations of datavalidation testing.
So, you’re planning a cloud datawarehouse migration. But be warned, a warehouse migration isn’t for the faint of heart. As you probably already know if you’re reading this, a datawarehouse migration is the process of moving data from one warehouse to another. A worthy quest to be sure.
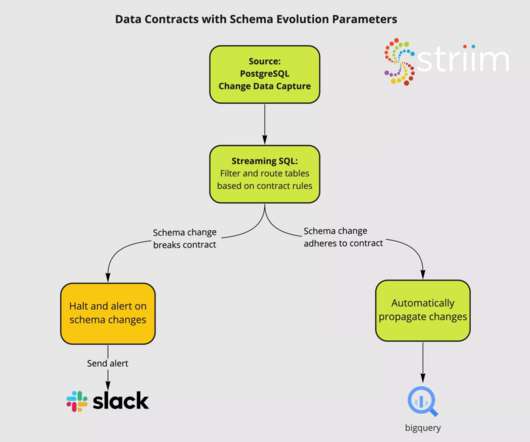
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
It is important to note that normalization often overlaps with the data cleaning process, as it helps to ensure consistency in data formats, particularly when dealing with different sources or inconsistent units. DataValidationDatavalidation ensures that the data meets specific criteria before processing.
At TCS , we help companies shift their enterprise datawarehouse (EDW) platforms to the cloud as well as offering IT services. We’re extremely familiar with just how tricky a cloud migration can be, especially when it involves moving historical business data. Use separate datawarehouses for cost-effective data loading.
Hear me out – back in the on-premises days we had data loading processes that connect directly to our source system databases and perform huge data extract queries as the start of one long, monolithic data pipeline, resulting in our datawarehouse. Till next time.
This conversation was useful for getting a better idea of the challenges that exist in large scale data analytics, and the current state of the tradeoffs between data lakes and datawarehouses in the cloud. What are some of the common antipatterns in data lake implementations and how does Delta Lake address them?
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Snowflake and Azure Synapse offer powerful data warehousing solutions that simplify data integration and analysis by providing elastic scaling and optimized query performance.
It involves thorough checks and balances, including datavalidation, error detection, and possibly manual review. Data Testing vs. These design patterns lead to disjointed data quality tools that add more cost to the pipeline operation than solving the problem. Why I’m making this claim? How to Fix It? Stay Tuned.
If such query workloads create additional data lags then it will actively cause more harm by increasing your blind spot at the exact wrong time, the time when fraud is being perpetrated. OLTP databases aren’t built to ingest massive volumes of data streams and perform stream processing on incoming datasets.
However, for all of our uncertified data, which remained the majority of our offline data, we lacked visibility into its quality and didn’t have clear mechanisms for up-leveling it. How could we scale the hard-fought wins and best practices of Midas across our entire datawarehouse?
In software engineering, data modeling involves applying formal techniques to create a data model for an information system. Dimensional modeling refers to the use of fact and dimension tables to keep a record of historical data in datawarehouses. How does a Data Analysis project work?
Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. DataOps tools help ensure data quality by providing features like data profiling, datavalidation, and data cleansing.
After the horror that was the “data silo” days, with clumps of data living in Access databases, Excel spreadsheets and isolated data stores, we’ve had a pretty good run with the classic Kimball datawarehouse. However, a datawarehouse is a large, sanitary data store.
Secondly , the rise of data lakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape. Read More: What is ETL?
ETL stands for Extract, Transform, and Load, which involves extracting data from various sources, transforming the data into a format suitable for analysis, and loading the data into a destination system such as a datawarehouse. ETL developers play a significant role in performing all these tasks.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, Data Integrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Production Monitoring Only.
Snowflake Overview A datawarehouse is a critical part of any business organization. Lot of cloud-based datawarehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical datawarehouse that is provided as Software-as-a-Service (SaaS).
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a data processing method that involves extracting data from its source, loading it into a database or datawarehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
Data integration and transformation: Before analysis, data must frequently be translated into a standard format. Data processing analysts harmonise many data sources for integration into a single data repository by converting the data into a standardised structure.
Niv Sluzki June 20, 2023 What Is Data Integrity? Data integrity refers to the overall accuracy, consistency, and reliability of data stored in a database, datawarehouse, or any other information storage system. 4 Ways to Prevent and Resolve Data Integrity Issues 1.
Data Integrity Testing: Goals, Process, and Best Practices Niv Sluzki July 6, 2023 What Is Data Integrity Testing? Data integrity testing refers to the process of validating the accuracy, consistency, and reliability of data stored in databases, datawarehouses, or other data storage systems.
Before we get into more detail, let’s determine how data virtualization is different from another, more common data integration technique — data consolidation. Data virtualization vs data consolidation. The example of a typical two-tier architecture with a data lake and datawarehouses and several ETL processes.
It is the process of extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a target database or datawarehouse. ETL is used to integrate data from different sources and formats into a single target for analysis. What is an ETL Pipeline?
During this transformation, Airbnb experienced the typical growth challenges that most companies do, including those that affect the datawarehouse. In the first post of this series, we shared an overview of how we evolved our organization and technology standards to address the data quality challenges faced during hyper growth.
Companies need to analyze large volumes of datasets, leading to an increase in data producers and consumers within their IT infrastructures. These companies collect data from production applications and B2B SaaS tools (e.g., This data makes its way into a data repository, like a datawarehouse (e.g.,
Optional: Disable the print_table() command, so the model can be materialized on your datawarehouse. With this detailed report, it becomes easier for the AE to find out what could be going wrong with the data refactoring workflow, so the issue can be directly investigated and solved.
Completely Versioned Data Stacks Modern Data Stacks in a Box with DuckDB by Jacob Matson “Why build a bundled Modern Data Stack on a single machine, rather than on multiple machines and on a datawarehouse? There are many advantages!
Executing dbt docs creates an interactive, automatically generated data model catalog that delineates linkages, transformations, and test coverageessential for collaboration among data engineers, analysts, and business teams. Workaround: Use Git branches, tagging, and commit messages to trackchanges.
Its strong on structure, with built-in type checks and datavalidation, so you dont end up with mystery bugs halfway through your pipeline. Tech stack compatibility: Look for tools that integrate well with your existing datawarehouse (like Snowflake or BigQuery), version control, and other parts of your ML pipeline.
By understanding the differences between transformation and conversion testing and the unique strengths of each tool, organizations can design more reliable, efficient, and scalable datavalidation frameworks to support their data pipelines.
In this article we introduce “Key Assets”, a new approach taken by the best data teams to surface your most important data assets for quick and reliable insights. Have you been 3/4ths of the way done with a datawarehouse migration only to discover that you don’t know which data assets are right and which ones are wrong?
This provided a nice overview of the breadth of topics that are relevant to data engineering including datawarehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. 69 The End of ETL as We Know It Use events from the product to notify data systems of changes.
Transmitting data across multiple paths can identify the compromise of one path or a path exhibiting erroneous behavior and corrupting data. Datavalidation rules can identify gross errors and inconsistencies within the data set. Read more about our Reverse ETL Tools. featured image via unsplash
This could be the result of a sync issue, the type of information each collects, or how each platform treats different data types. Having the datawarehouse as a central source of truth can help present a more consistent view of the campaign. Looker also has a semantic layer called LookML.
Despite these challenges, proper data acquisition is essential to ensure the data’s integrity and usefulness. DataValidation In this phase, the data that has been acquired is checked for accuracy and consistency.
DuckDB is gaining much attention on this promise, and the Dagster team writes about its experimental datawarehouse built on top of DuckDB, Parquet, and Dagster. link] Sponsored: Why You Should Care About Dimensional Data Modeling It's easy to overlook all of the magic that happens inside the datawarehouse.
To that end, we needed to have both the legacy Alteryx workflow output table and the refactored dbt model materialized in the project’s datawarehouse. Then we used the macros available in audit_helper to compare query results, data types, column values, row numbers and many more things that are available within the package.
Database differences and schema management Each database, even in the cloud, stores values a little differently–but those little changes can be big data migration risks. For example, one data leader gave us the example of how two datawarehouse store dollar amounts differently.
But, while this can provide some much-needed context, it doesn’t provide the granularity data teams need to remediate the data problems they uncover—or prevent them from happening again in the future. In the context of data pipelines, column level lineage traces the relationships across and between upstream source systems (i.e.,
But, while this can provide some much-needed context, it doesn’t provide the granularity data teams need to remediate the data problems they uncover—or prevent them from happening again in the future. In the context of data pipelines, column level lineage traces the relationships across and between upstream source systems (i.e.,
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content