This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
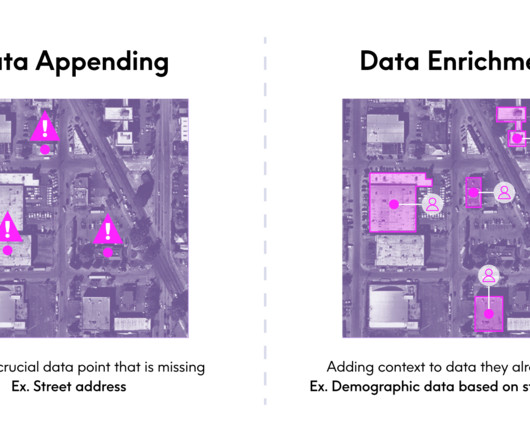
An important part of this journey is the datavalidation and enrichment process. Defining DataValidation and Enrichment Processes Before we explore the benefits of datavalidation and enrichment and how these processes support the data you need for powerful decision-making, let’s define each term.
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. Pandera, a datavalidation library for dataframes, now supports Polars. This is Croissant.
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment.
Storing data: data collected is stored to allow for historical comparisons. The historical dataset is over 20M records at the time of writing! This means about 275,000 up-to-date server prices, and around 240,000 benchmark scores. Web frontend: Angular 17 with server-side rendering support (SSR).
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
The Definitive Guide to DataValidation Testing Datavalidation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. It’s also important to understand the limitations of datavalidation testing.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
Different schemas, naming standards, and data definitions are frequently used by disparate repository source systems, which can lead to datasets that are incompatible or conflicting. To guarantee uniformity among datasets and enable precise integration, consistent data models and terminology must be established.
When you delve into the intricacies of data quality, however, these two important pieces of the puzzle are distinctly different. Knowing the distinction can help you to better understand the bigger picture of data quality. What Is DataValidation? Read What Is Data Verification, and How Does It Differ from Validation?
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
In this article, we’ll dive into the six commonly accepted data quality dimensions with examples, how they’re measured, and how they can better equip data teams to manage data quality effectively. Table of Contents What are Data Quality Dimensions? What are the 7 Data Quality Dimensions?
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view.
If the data changes over time, you might end up with results you didn’t expect, which is not good. To avoid this, we often use data profiling and datavalidation techniques. Data profiling gives us statistics about different columns in our dataset. It lets you log all sorts of data. So let’s dive in!
And of course, getting your data up to the task is the other critical piece of the AI readiness puzzle. Yoğurtçu identifies three critical steps that you should take to prepare your data for AI initiatives: Identify all critical and relevant datasets , ensuring that those used for AI training and inference are accounted for.
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. Learn more in our detailed guide to data reliability 6 Pillars of Data Quality 1.
Distributed Data Processing Frameworks Another key consideration is the use of distributed data processing frameworks and data planes like Databricks , Snowflake , Azure Synapse , and BigQuery. These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets.
To achieve accurate and reliable results, businesses need to ensure their data is clean, consistent, and relevant. This proves especially difficult when dealing with large volumes of high-velocity data from various sources.
Data center migration: Physical relocation or consolidation of data centers Virtualization migration: Moving from physical servers to virtual machines (or vice versa) Section 3: Technical Decisions Driving Data Migrations End-of-life support: Forced migration when older software or hardware is sunsetted Security and compliance: Adopting new platforms (..)
Read our eBook Validation and Enrichment: Harnessing Insights from Raw Data In this ebook, we delve into the crucial datavalidation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
And of course, getting your data up to the task is the other critical piece of the AI readiness puzzle. Yoğurtçu identifies three critical steps that you should take to prepare your data for AI initiatives: Identify all critical and relevant datasets , ensuring that those used for AI training and inference are accounted for.
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. Enrichment: The Secret to Supercharged AI You’re not just improving accuracy by augmenting your datasets with additional information.
At the end of this pipeline, the data with training features are ingested in the database. Figure 1: hybrid logging for features On a daily basis, the features are joined with the labels to produce the final training dataset. Performance Validation We validate the auto-retraining quality at two places throughout the pipeline.
Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset. This dataset is free to use for commercial and non-commercial purposes. A description of the dataset is shown in the below figure.
Define Data Wrangling The process of data wrangling involves cleaning, structuring, and enriching raw data to make it more useful for decision-making. Data is discovered, structured, cleaned, enriched, validated, and analyzed. Values significantly out of a dataset’s mean are considered outliers.
Data integrity is all about building a foundation of trusted data that empowers fast, confident decisions that help you add, grow, and retain customers, move quickly and reduce costs, and manage risk and compliance – and you need data enrichment to optimize those results. Read Why is Data Enrichment Important?
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
The concurrent queries will not see the effect of the data loads until the data load is complete, creating 10s of minutes of data lags. OLTP databases aren’t built to ingest massive volumes of data streams and perform stream processing on incoming datasets. So they are not suitable for real-time analytics.
Databand — Data pipeline performance monitoring and observability for data engineering teams. . Soda Data Monitoring — Soda tells you which data is worth fixing. Soda doesn’t just monitor datasets and send meaningful alerts to the relevant teams. Observe, optimize, and scale enterprise data pipelines. .
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
For example, if a media outlet uses incorrect data from an Economic Graph report in their reporting, it could result in a loss of trust among their readership. We currently address over 50 requests for our data and insights per month. This is particularly useful for the Asimov team to see dataset health over time at a glance quickly.
Data Profiling 2. Data Cleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Use of Data Quality Tools Refresh your intrinsic data quality with data observability 1. Data Profiling Data profiling is getting to know your data, warts and quirks and secrets and all.
At their core, ML models learn from data. They are trained on large datasets to recognise patterns and make predictions or decisions based on new information. During the model evaluation phase (validation mode), we will use a labelled dataset of emails to calculate metrics like accuracy, precision and recall.
High-quality data, free from errors, inconsistencies, or biases, forms the foundation for accurate analysis and reliable insights. Data products should incorporate mechanisms for datavalidation, cleansing, and ongoing monitoring to maintain data integrity.
Accurate data ensures that these decisions and strategies are based on a solid foundation, minimizing the risk of negative consequences resulting from poor data quality. There are various ways to ensure data accuracy. Data cleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Building a Resilient Pre-Production DataValidation Framework Proactively validatingdata pipelines before production is the key to reducing data downtime, improving reliability, and ensuring accurate business insights. Enhances the robustness of data transformations by ensuring they handle edge cases effectively.
So let’s say that you have a business question, you have the raw data in your data warehouse , and you’ve got dbt up and running. You’re in the perfect position to get this curated dataset completed quickly! You’ve got three steps that stand between you and your finished curated dataset. Or are you?
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
Table of Contents What Does an AI Data Quality Analyst Do? An AI Data Quality Analyst should be comfortable with: Data Management : Proficiency in handling large datasets. Data Cleaning and Preprocessing : Techniques to identify and remove errors. Attention to Detail : Critical for identifying data anomalies.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
By routinely conducting data integrity tests, organizations can detect and resolve potential issues before they escalate, ensuring that their data remains reliable and trustworthy. Data integrity monitoring can include periodic data audits, automated data integrity checks, and real-time datavalidation.
Tracking data lineage is especially important when working with Python, as the language is so easy to use that you can end up digging your own grave if you start making large unintended changes to your most important datasets. Automated Tools for Python Data Lineage So how can we easily add data lineage to our Python workflows?
Pradheep Arjunan - Shared insights on AZ's journey from on-prem to the cloud data warehouses. Google: Croissant- a metadata format for ML-ready datasets Google Research introduced Croissant, a new metadata format designed to make datasets ML-ready by standardizing the format, facilitating easier use in machine learning projects.
To maximize your investments in AI, you need to prioritize data governance, quality, and observability. Solving the Challenge of Untrustworthy AI Results AI has the potential to revolutionize industries by analyzing vast datasets and streamlining complex processes – but only when the tools are trained on high-quality data.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content