This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An important part of this journey is the datavalidation and enrichment process. Defining DataValidation and Enrichment Processes Before we explore the benefits of datavalidation and enrichment and how these processes support the data you need for powerful decision-making, let’s define each term.
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. Pandera, a datavalidation library for dataframes, now supports Polars. This is Croissant.
Storing data: data collected is stored to allow for historical comparisons. The historical dataset is over 20M records at the time of writing! This means about 275,000 up-to-date server prices, and around 240,000 benchmark scores. Web frontend: Angular 17 with server-side rendering support (SSR).
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
The Definitive Guide to DataValidation Testing Datavalidation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. It’s also important to understand the limitations of datavalidation testing.
Project Idea: Start data engineering pipeline by sourcing publicly available or simulated Uber trip datasets, for example, the TLC Trip record dataset.Use Python and PySpark for data ingestion, cleaning, and transformation. This project will help analyze user data for actionable insights.
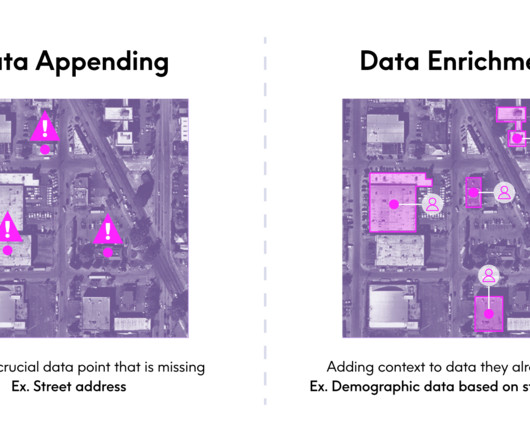
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
While these roles have different day-to-day responsibilities and technical focuses, they are united by common pain points when data quality fails: Delayed project deliveries as teams spend time investigating and fixing data issues Reduced confidence in analytics among business stakeholders Increased operational overhead from manual datavalidation (..)
By enabling automated checks and validations, DMFs allow organizations to monitor their data continuously and enforce business rules. With built-in and custom metrics, DMFs simplify the process of validating large datasets and identifying anomalies. Scalability : Handle large datasets without compromising performance.
When you delve into the intricacies of data quality, however, these two important pieces of the puzzle are distinctly different. Knowing the distinction can help you to better understand the bigger picture of data quality. What Is DataValidation? Read What Is Data Verification, and How Does It Differ from Validation?
You must study how data is altered during ETL processes, including common tasks like filtering, sorting, aggregating, and combining data. Practice With Real Data The transition from synthetic datasets to real-world data. You must get your hands on real-world datasets and practice ETL tasks using them.
Different schemas, naming standards, and data definitions are frequently used by disparate repository source systems, which can lead to datasets that are incompatible or conflicting. To guarantee uniformity among datasets and enable precise integration, consistent data models and terminology must be established.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
Build A Movie Recommendation API Tools and Technologies: Python, FastAPI, Machine Learning (Collaborative/Content-based Filtering), Tensorflow Project Solution Approach: To build the Movie Recommendation API project, you would need a dataset containing information about movies, such as the MovieLens dataset, IMDb dataset, or TMDB dataset.
In this article, we’ll dive into the six commonly accepted data quality dimensions with examples, how they’re measured, and how they can better equip data teams to manage data quality effectively. Table of Contents What are Data Quality Dimensions? What are the 7 Data Quality Dimensions?
And of course, getting your data up to the task is the other critical piece of the AI readiness puzzle. Yoğurtçu identifies three critical steps that you should take to prepare your data for AI initiatives: Identify all critical and relevant datasets , ensuring that those used for AI training and inference are accounted for.
This influx of data and surging demand for fast-moving analytics has had more companies find ways to store and process data efficiently. This is where Data Engineers shine! The first step in any data engineering project is a successful data ingestion strategy.
Target Data Completeness This involves validating the presence of expected records and the population of required fields in the target dataset, preventing data loss and supporting comprehensive analysis. Record Completeness: Record completeness checks assess whether all expected records are present in the target dataset.
If the data changes over time, you might end up with results you didn’t expect, which is not good. To avoid this, we often use data profiling and datavalidation techniques. Data profiling gives us statistics about different columns in our dataset. It lets you log all sorts of data. So let’s dive in!
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? Without the right tools and frameworks, developers often struggle with inefficient datavalidation, scalability issues, and managing complex workflows. and pip installed.
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view.
Distributed Data Processing Frameworks Another key consideration is the use of distributed data processing frameworks and data planes like Databricks , Snowflake , Azure Synapse , and BigQuery. These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets.
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. Learn more in our detailed guide to data reliability 6 Pillars of Data Quality 1.
Sentiment Analysis and Voice of Customer Emerging Trends in AI Data Analytics Build AI and Data Analytics Skills with ProjectPro FAQS What is AI in Data Analytics? AI in data analytics refers to the use of AI tools and techniques to extract insights from large and complex datasets faster than traditional analytics methods.
Both assist in saving on expenses spent on storing such large datasets and offer functionalities that assist in effectively analyzing those datasets. Besides that, they are supported by a strongly-knit community of engineers contributing to novel advancements in managing and analyzing large datasets.
To achieve accurate and reliable results, businesses need to ensure their data is clean, consistent, and relevant. This proves especially difficult when dealing with large volumes of high-velocity data from various sources.
Access control based on roles (RBAC) In accordance with corporate policies, RBAC enables administrators to fine-tune who has granular access to which Fabric assets (such as data lakes, reports, and pipelines). After that, we’ll examine Microsoft Fabric Architecture: Integration Templates.
Data Redundancy Data duplication during data migration can occur when generating staging or intermediate datasets. Understanding the connections between the data fields in depth is crucial for properly identifying and managing such duplicate data. For transferring data from one flat file (.csv,txt),
Read our eBook Validation and Enrichment: Harnessing Insights from Raw Data In this ebook, we delve into the crucial datavalidation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
Machine Learning problems can be divided into the following types : Supervised Learning- Agents learn from labeled datasets, such as training a model to classify emails as spam or not. These models are pre-trained on massive text datasets, enabling them to grasp context and semantics.
Additionally, evaluating models on separate validation or test datasets helps gauge their ability to generalize to unseen data. Implement data quality checks and datavalidation techniques. Feature Engineering: Explore and engineer relevant features from the data to enhance model performance.
And of course, getting your data up to the task is the other critical piece of the AI readiness puzzle. Yoğurtçu identifies three critical steps that you should take to prepare your data for AI initiatives: Identify all critical and relevant datasets , ensuring that those used for AI training and inference are accounted for.
Sample Dataset: Amazon Fine Food Reviews - Contains over 500,000 reviews with text suitable for summarization projects. Fine-tuning models on custom datasets improves accuracy for specific applications. Method: For implementing this project you can use the dataset StackSample.
Data center migration: Physical relocation or consolidation of data centers Virtualization migration: Moving from physical servers to virtual machines (or vice versa) Section 3: Technical Decisions Driving Data Migrations End-of-life support: Forced migration when older software or hardware is sunsetted Security and compliance: Adopting new platforms (..)
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. Enrichment: The Secret to Supercharged AI You’re not just improving accuracy by augmenting your datasets with additional information.
This could involve sourcing data from databases, APIs, or public datasets. For example, data might be collected from transaction logs, customer service interactions, and demographic information in a customer churn prediction project. Collect and clean data to remove inconsistencies and ensure relevance.
Topics include extracting data from files and directories, creating views and tables, deduplication techniques, datavalidation, timestamp manipulation, and using array functions. This section enhances skills in data transformation and manipulation with Apache Spark.
At the end of this pipeline, the data with training features are ingested in the database. Figure 1: hybrid logging for features On a daily basis, the features are joined with the labels to produce the final training dataset. Performance Validation We validate the auto-retraining quality at two places throughout the pipeline.
Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset. This dataset is free to use for commercial and non-commercial purposes. A description of the dataset is shown in the below figure.
Larger companies require more time for transferring data using storage migration. Storage migration also involves datavalidation, duplication, cleaning, etc. Application Migration When investing in one, an organization must transfer all data into a new software system. Gain a Clear Understanding of the Data.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
Define Data Wrangling The process of data wrangling involves cleaning, structuring, and enriching raw data to make it more useful for decision-making. Data is discovered, structured, cleaned, enriched, validated, and analyzed. Values significantly out of a dataset’s mean are considered outliers.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content