This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An important part of this journey is the datavalidation and enrichment process. Defining DataValidation and Enrichment Processes Before we explore the benefits of datavalidation and enrichment and how these processes support the data you need for powerful decision-making, let’s define each term.
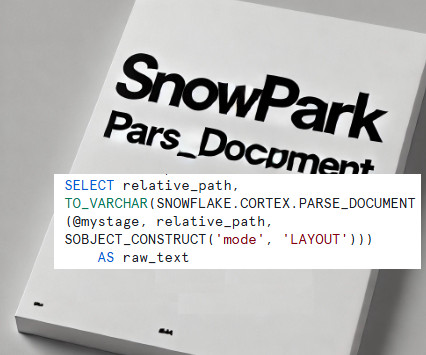
Our goal is to: Extract the raw text using PARSE_DOCUMENT. Process and validate key fields such as policy numbers, holder names, and financial amounts. Store the cleaned data in a structured format for analysis. Step 1: Extract RawData Using PARSE_DOCUMENT First, PDFs are uploaded to a Snowflake stage.
Code and rawdata repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns. Web frontend: Angular 17 with server-side rendering support (SSR).
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
We covered how Data Quality Testing, Observability, and Scorecards turn data quality into a dynamic process, helping you build accuracy, consistency, and trust at each layerBronze, Silver, and Gold. Practical Tools to Sprint Ahead: Dive into hands-on tips with open-source tools that supercharge datavalidation and observability.
We work with organizations around the globe that have diverse needs but can only achieve their objectives with expertly curated data sets containing thousands of different attributes. The post Use Data Enrichment to Supercharge AI appeared first on Precisely.
In this article, we’ll dive into the six commonly accepted data quality dimensions with examples, how they’re measured, and how they can better equip data teams to manage data quality effectively. Table of Contents What are Data Quality Dimensions? What are the 7 Data Quality Dimensions?
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial datavalidation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
According to the 2023 Data Integrity Trends and Insights Report , published in partnership between Precisely and Drexel University’s LeBow College of Business, 77% of data and analytics professionals say data-driven decision-making is the top goal of their data programs. That’s where data enrichment comes in.
Taking data from sources and storing or processing it is known as data extraction. Define Data Wrangling The process of data wrangling involves cleaning, structuring, and enriching rawdata to make it more useful for decision-making. Data is discovered, structured, cleaned, enriched, validated, and analyzed.
How many tables and views will be migrated, and how much rawdata? Are there redundant, unused, temporary or other types of data assets that can be removed to reduce the load? What is the best time to extract the data so it has minimal impact on business operations?
I often noticed that the derived data is always > 10 times larger than the warehouse's rawdata. The Netflix blog emphasizes the importance of finding the zombie data and the system design around deleting unused data.
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation.
So let’s say that you have a business question, you have the rawdata in your data warehouse , and you’ve got dbt up and running. The analyst will try to do as much discovery work up-front as possible, because it’s hard to predict exactly what you’ll find in the rawdata. Or are you?
Precisely’s address and property data helps you identify serviceable addresses in your target area accurately, with mail delivery indicators, detailed land use, building designations, and more.
Introduction to Data Products In today’s data-driven landscape, data products have become essential for maximizing the value of data. As organizations seek to leverage data more effectively, the focus has shifted from temporary datasets to well-defined, reusable data assets.
The current landscape of Data Observability Tools shows a marked focus on “Data in Place,” leaving a significant gap in the “Data in Use.” ” When monitoring rawdata, these tools often excel, offering complete standard data checks that automate much of the datavalidation process.
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching rawdata before it can be used for analysis or machine learning models. There are several types of data testing tools.
The Transform Phase During this phase, the data is prepared for analysis. This preparation can involve various operations such as cleaning, filtering, aggregating, and summarizing the data. The goal of the transformation is to convert the rawdata into a format that’s easy to analyze and interpret.
In today's data-driven world, where information reigns supreme, businesses rely on data to guide their decisions and strategies. However, the sheer volume and complexity of rawdata from various sources can often resemble a chaotic jigsaw puzzle. What are the six steps of data wrangling?
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching rawdata before it can be used for analysis or machine learning models. There are several types of data testing tools. The post Data testing tools: Key capabilities you should know appeared first on Databand.
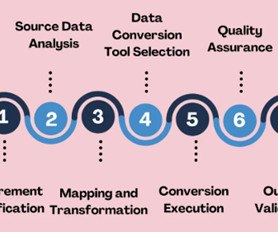
Selecting the strategies and tools for validatingdata transformations and data conversions in your data pipelines. Introduction Data transformations and data conversions are crucial to ensure that rawdata is organized, processed, and ready for useful analysis.
Read More: What is ETL? – (Extract, Transform, Load) ELT for the Data Lake Pattern As discussed earlier, data lakes are highly flexible repositories that can store vast volumes of rawdata with very little preprocessing. Their task is straightforward: take the rawdata and transform it into a structured, coherent format.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial datavalidation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes.
Read our eBook Validation and Enrichment: Harnessing Insights from RawData In this ebook, we delve into the crucial datavalidation and enrichment process, uncovering the challenges organizations face and presenting solutions to simplify and enhance these processes. Read Trend 3.
Companies that leverage CRMs might mitigate risks related to broad domain access by implementing a framework that includes data collection controls, human-error checks, restricted rawdata access, cybersecurity countermeasures, and frequent data back-ups.
In this respect, the purpose of the blog is to explain what is a data engineer , describe their duties to know the context that uses data, and explain why the role of a data engineer is central. What Does a Data Engineer Do? Design algorithms transforming rawdata into actionable information for strategic decisions.
From RawData to Insights: Simplifying DataValidation and Enrichment Businesses that want to be more data-driven are increasingly in need of data that provides answers to their everyday questions. How can the power of datavalidation and enrichment transform your business? Join us to find out.
In a DataOps architecture, it’s crucial to have an efficient and scalable data ingestion process that can handle data from diverse sources and formats. This requires implementing robust data integration tools and practices, such as datavalidation, data cleansing, and metadata management.
Data Loading : Load transformed data into the target system, such as a data warehouse or data lake. In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability.
Typically, such information may transition through a database or other data store for access as secondary data by the data processor. Machine Data Equipment ranging from simple sensors to complex operational technology may generate information as a data source. It may be rawdata, validateddata, or big data.
The raw measurements and observations made while completing the tasks necessary to complete the project comprise the work performance data. The project manager and team still need to analyze the rawdata. To guarantee data quality, conduct regular audits and datavalidation checks.
ETL stands for: Extract: Retrieve rawdata from various sources. Transform: Process the data to make it suitable for analysis (this can involve cleaning, aggregating, enriching, and restructuring). Data Quality: Automated ETL solutions incorporate advanced data quality assurance mechanisms.
Fixing Errors: The Gremlin Hunt Errors in data are like hidden gremlins. Use spell-checkers and datavalidation checks to uncover and fix them. Automated datavalidation tools can also help detect anomalies, outliers, and inconsistencies. Offers powerful data structures and functions for data cleaning tasks.
Unified DataOps represents a fresh approach to managing and synchronizing data operations across several domains, including data engineering, data science, DevOps, and analytics. The goal of this strategy is to streamline the entire process of extracting insights from rawdata by removing silos between teams and technologies.
During ingestion: Test your data as it enters your system to identify any issues with the source or format early in the process. After transformation: After processing or transforming rawdata into a more usable format, test again to ensure that these processes have not introduced errors or inconsistencies.
Your SQL skills as a data engineer are crucial for data modeling and analytics tasks. Making data accessible for querying is a common task for data engineers. Collecting the rawdata, cleaning it, modeling it, and letting their end users access the clean data are all part of this process.
Maintain Clean Reports Power BI report is a detailed summary of the large data set as per the criteria given by the user. They comprise tables, data sets, and data fields in detail, i.e., rawdata. Working with rawdata is challenging, so it is best advised to keep data clean and organized.
The role of a Power BI developer is extremely imperative as a data professional who uses rawdata and transforms it into invaluable business insights and reports using Microsoft’s Power BI. Data Analysis: Perform basic data analysis and calculations using DAX functions under the guidance of senior team members.
Data collection is a systematic process of gathering and measuring information from various sources to gain insights and answers. Data analysts and data scientists collect data for analysis. In fact, collecting, sorting, and transforming rawdata into actionable insights is one of the most critical data scientist skills.
Common Misspelling and Duplicate entries are a common data quality problem that most of the data analysts face. Having different value representations and misclassified data. 8) What are the important steps in datavalidation process? Involves analysing rawdata from existing datasets.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
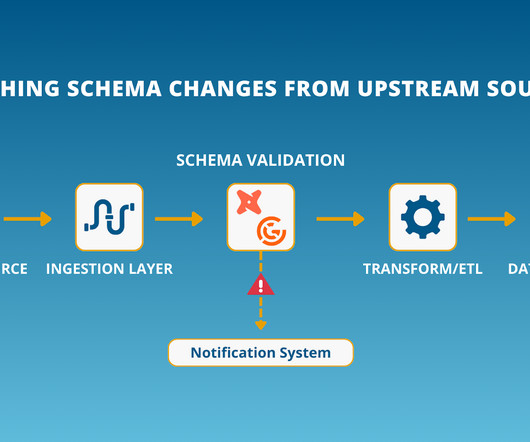
Most datavalidation is a patchwork joba schema check here, a rushed file validation there, maybe a retry mechanism when things go sideways. If youre done with quick fixes that dont hold up, its time to build a system using datavalidation techniques that actually workone that stops issues before they spiral.
Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. Data that can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi-structured data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content