This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snowflake partner Accenture, for example, demonstrated how insurance claims professionals can leverage AI to process unstructured data including government IDs and reports to make document gathering, datavalidation, claims validation and claims letter generation more streamlined and efficient.
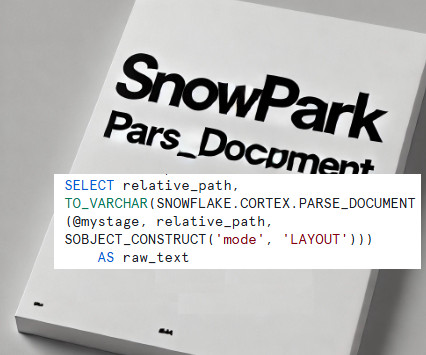
Extending PARSE_DOCUMENT with Snowpark Using Snowpark, we can: Process and validate extracted content dynamically. Apply advanced data cleansing and transformation logic using Python. Automate structureddata insertion into Snowflake tables for downstream analytics.
Benefit #2: “ Flexible data model” — Yehonathan Sharvit “When using generic datastructures, data can be created with no predefined shape, and its shape can be modified at will.” — Yehonathan Sharvit In the example below, not all the dictionaries in the list have the same keys.
Background The Goku-Ingestor is an asynchronous data processing pipeline that performs multiplexing of metrics data. Thrift Integration for Enhanced Parsing Leveraging the structureddata serialization capabilities of Apache Thrift presents a promising avenue for optimizing the parsing of incoming data.
Data integrity is all about building a foundation of trusted data that empowers fast, confident decisions that help you add, grow, and retain customers, move quickly and reduce costs, and manage risk and compliance – and you need data enrichment to optimize those results. Read Why is Data Enrichment Important?
Data integration and transformation: Before analysis, data must frequently be translated into a standard format. Data processing analysts harmonise many data sources for integration into a single data repository by converting the data into a standardised structure.
Executing dbt docs creates an interactive, automatically generated data model catalog that delineates linkages, transformations, and test coverageessential for collaboration among data engineers, analysts, and business teams.
In contrast, ETL is primarily employed by DW/ETL developers responsible for data integration between source systems and reporting layers. DataStructure: Data wrangling deals with varied and complex data sets, which may include unstructured or semi-structureddata. Frequently Asked Questions (FAQs) 1.
Attention to Detail : Critical for identifying data anomalies. Tools : Familiarity with datavalidation tools, data wrangling tools like Pandas , and platforms such as AWS , Google Cloud , or Azure. Data observability tools: Monte Carlo ETL Tools : Extract, Transform, Load (e.g., Informatica , Talend ).
This velocity aspect is particularly relevant in applications such as social media analytics, financial trading, and sensor data processing. Variety: Variety represents the diverse range of data types and formats encountered in Big Data. Handling this variety of data requires flexible data storage and processing methods.
Data Loading : Load transformed data into the target system, such as a data warehouse or data lake. In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability. Used for identifying and cataloging data sources.
With a complex datavalidation process, for example, an RPA bot might struggle to identify and handle unexpected errors. These include: Structureddata dependence: RPA solutions thrive on well-organized, predictable data. It struggles with unstructured data like emails, scanned documents, or free-form text.
A combination of structured and semi structureddata can be used for analysis and loaded into the cloud database without the need of transforming into a fixed relational scheme first. The key features include: Rapid migration of data from SAP BW and HANA. Automated data cleansing and predefined datavalidation.
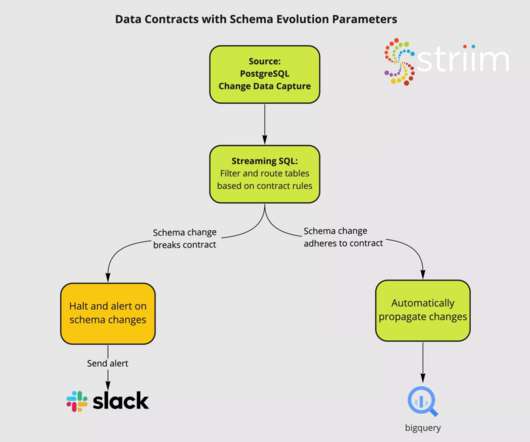
According to them, a data contract implementation consists of the following components, as depicted below: Defining data contracts as code using open-source projects (e.g. Apache Avro) to serialize and deserialize structureddata.
Strong schema support : Avro has a well-defined schema that allows for type safety and strong datavalidation. Sample use case: Avro is a good choice for big data platforms that need to process and analyze large volumes of log data.
If the data includes an old record or an incorrect value, then it’s not accurate and can lead to faulty decision-making. Data content: Are there significant changes in the data profile? Datavalidation: Does the data conform to how it’s being used?
Stepwise Transformation: Structuringdata transformation in sequential steps provides clarity and control over sophisticated data operations such as business validation, data normalization, and analytics functions.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into datavalidation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
Incomplete data from external sources When you ingest data from an external source, you lack a certain amount of control over how data is structured and made available. Different sources may structuredata inconsistently, which can lead to missing values within your data sets.
Data Analysis: Perform basic data analysis and calculations using DAX functions under the guidance of senior team members. Data Integration: Assist in integrating data from multiple sources into Power BI, ensuring data consistency and accuracy. Ensure compliance with data protection regulations.
Data Ingestion Data in today’s businesses come from an array of sources, including various clouds, APIs, warehouses, and applications. This multitude of sources often causes a dispersed, complex, and poorly structureddata landscape.
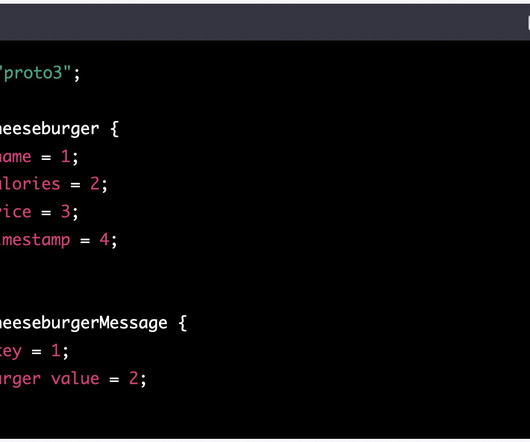
The contracts themselves should be created using well-established protocols for serializing and deserializing structureddata such as Google’s Protocol Buffers (protobuf), Apache Avro, or even JSON. They provide common data checks and a way to write custom tests within your dbt project. Consistency in your tech stack.
Datavalidations or data type checks can be performed using SQL, while duplicates, foreign key constraints, and NULL checks can all be identified using ETL solutions. Data processing tasks containing SQL-based data transformations can be conducted utilizing Hadoop or Spark executors by ETL solutions.
Data Variety Hadoop stores structured, semi-structured and unstructured data. RDBMS stores structureddata. Data storage Hadoop stores large data sets. RDBMS stores the average amount of data. Works with only structureddata. Hardware Hadoop uses commodity hardware.
To ensure consistency in the data product definitions across domains, these guidelines should at least cover: Metadata standards: Define a standard set of metadata to accompany every data product. This might include information about the data source, the type of data, the date of creation, and any relevant context or description.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structureddata. Schema Schema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
It’s true Big Data is dead, but we can’t deny it is a result of collective advancement in data processing techniques. link] Dropbox: Balancing quality and coverage with our datavalidation framework Data Testing should be part of the data creation lifecycle; it is not a standalone process.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content