This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
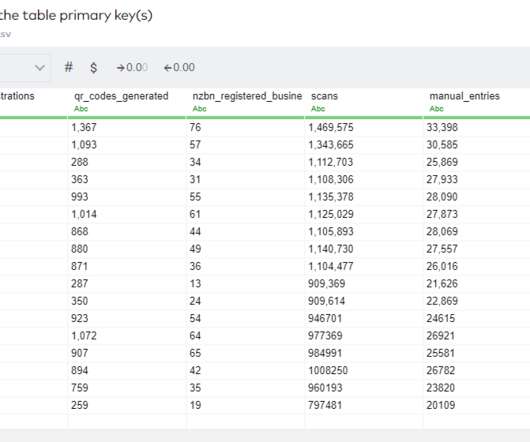
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
Once your datawarehouse is built out, the vast majority of your data will have come from other SaaS tools, internal databases, or customer data platforms (CDPs). Spreadsheets are the Swiss army knife of data processing. How big is the dataset? Does it have a consistent format?
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
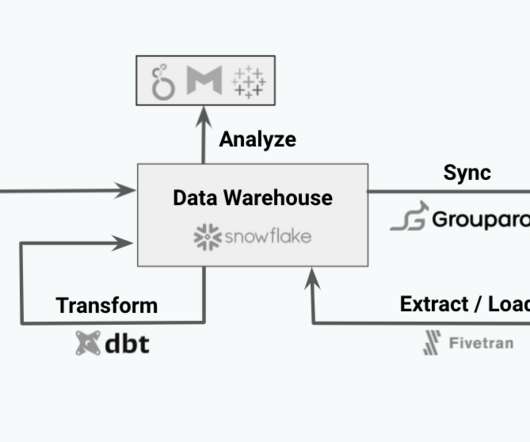
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. Tools like Databricks, Tabular and Galaxy try to solve this problem and it really feels like the future. You can change these # to conform to your data. Datalake example. Image by author.
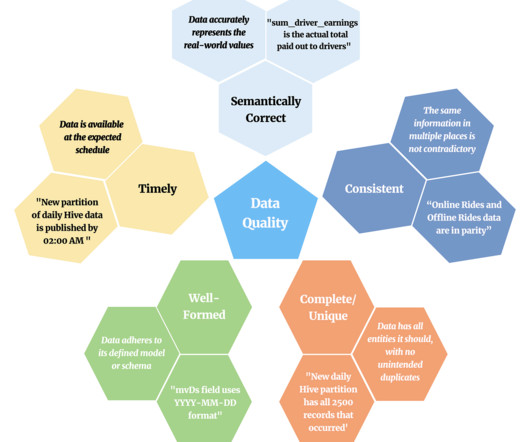
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive DataWarehouse. What and Where is Data Quality?
Regardless of the structure they eventually build, it’s usually composed of two types of specialists: builders, who use data in production, and analysts, who know how to make sense of data. Distinction between data scientists and engineers is similar. Data scientist’s responsibilities — Datasets and Models.
Operational analytics is the process of creating data pipelines and datasets to support business teams such as sales, marketing, and customer support. Data analysts and data engineers are responsible for building and maintaining data infrastructure to support many different teams at companies.
Data Ingestion Data ingestion is the first step of both ETL and data pipelines. In the ETL world, this is called data extraction, reflecting the initial effort to pull data out of source systems. The data sources themselves are not built to perform analytics.
These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset. The dataset can be either structured or unstructured or both. In this article, we will look at some of the top Data Science job roles that are in demand in 2024.
This includes the different possible sources of data such as application APIs, social media, relational databases, IoT device sensors, and data lakes. This may include a datawarehouse when it’s necessary to pipeline data from your warehouse to various destinations as in the case of a reverse ETL pipeline.
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their datawarehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use?
Cloud datawarehouses solve these problems. Belonging to the category of OLAP (online analytical processing) databases, popular datawarehouses like Snowflake, Redshift and Big Query can query one billion rows in less than a minute. What is a datawarehouse?
What you really want is a unified view of your data using Customer Data Integration so you can take action on it. Customer data integration here might include creating a datawarehouse where you can house your accurate and complete dataset. Scalability A datawarehouse can scale well with your data.
For more detailed information on data science team roles, check our video. An analytics engineer is a modern data team member that is responsible for modeling data to provide clean, accurate datasets so that different users within the company can work with them. Here’s the video explaining how data engineers work.
Data tokenization techniques allow the storage of critical data in secure locations while datawarehouses store a token that points to the secure copy. This enables the application of security controls and protection techniques to a subset of data, transparent to processes accessing the datawarehouse.
This data can be structured, semi-structured, or entirely unstructured, making it a versatile tool for collecting information from various origins. The extracted data is then duplicated or transferred to a designated destination, often a datawarehouse optimized for Online Analytical Processing (OLAP).
This is done by specific data analyzing algorithms implemented into the data models to analyze the data efficiently. Maintenance: Bugs are common when dealing with different sizes and types of datasets. Thus, the role demands prior experience in handling large volumes of data. Salary: $105,000 - $125,000 3.
This is done by specific data analyzing algorithms implemented into the data models to analyze the data efficiently. Maintenance: Bugs are common when dealing with different sizes and types of datasets. Thus, the role demands prior experience in handling large volumes of data. Salary: $135,000 - $165,000 2.Big
Why is ETL used in Data Science? ETL stands for Extract, Transform, and Load. It entails gathering data from numerous sources, converting it, and then storing it in a new single datawarehouse. Supports data migration to a datawarehouse from existing systems, etc.
The architecture of a data lake project may contain multiple components, including the Data Lake itself, one or multiple DataWarehouses or one or multiple Data Marts. The Data Lake acts as the central repository for aggregating data from diverse sources in its raw format.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
Reduce ingest latency and complexity: Multiple point solutions were needed to move data from different data sources to downstream systems. These data products can be web applications, dashboards, alerting systems, or even data science notebooks. . Better yet, it works in any cloud environment.
Introduction Amazon Redshift, a cloud datawarehouse service from Amazon Web Services (AWS), will directly query your structured and semi-structured data with SQL. Amazon Redshift Serverless allows customers to analyze and query data without configuring and managing a datawarehouse.
Here is a step-by-step guide on how to become an Azure Data Engineer: 1. Understanding SQL You must be able to write and optimize SQL queries because you will be dealing with enormous datasets as an Azure Data Engineer. You should be able to create scalable, effective programming that can work with big datasets.
Overwhelmed with log files and sensor data? It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. Businesses can run these workflows on a recurring basis, which keeps data fresh and analysis-ready.
DatasetsDatasets in Azure Data Factory define the schema and location of data sources or sinks. They represent the data you want to work with and are used in activities within pipelines. This process ensures that consolidated and consistent data is available for building comprehensive reports and dashboards.
Introduction Most data modeling approaches for customer segmentation are based on a wide table with user attributes. This table only stores the current attributes for each user, and is then loaded into the various SaaS platforms via Reverse ETLtools.
What Does a Data Engineer Do? Data engineers play a paramount role in the organization by transforming raw data into valuable insights. Their roles are expounded below: Acquire Datasets: It is about acquiring datasets that are focused on defined business objectives to drive out relevant insight.
A pipeline may include filtering, normalizing, and data consolidation to provide desired data. It can also consist of simple or advanced processes like ETL (Extract, Transform and Load) or handle training datasets in machine learning applications. What is a Big Data Pipeline?
Improved Collaboration Among Teams Data engineering teams frequently collaborate with other departments, such as analysts or scientists, who depend on accurate datasets for their tasks. Boosting Operational Efficiency A well-monitored data pipeline can significantly increase an organization’s operational efficiency.
The term data lake itself is metaphorical, evoking an image of a large body of water fed by multiple streams, each bringing new data to be stored and analyzed. Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture.
Transform: Process the data to make it suitable for analysis (this can involve cleaning, aggregating, enriching, and restructuring). Load: Deliver the transformed data into a destination, typically a database or datawarehouse.
The responsibilities of a DataOps engineer include: Building and optimizing data pipelines to facilitate the extraction of data from multiple sources and load it into datawarehouses. A DataOps engineer must be familiar with extract, load, transform (ELT) and extract, transform, load (ETL) tools.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making raw data efficient to form insights. Connecting to Data Begin by selecting your dataset.
The platform’s massive parallel processing (MPP) architecture empowers you with high-performance querying of even massive datasets. Polyglot Data Processing Synapse speaks your language! This flexibility allows your data team to leverage their existing skills and preferred tools, boosting productivity.
Data integration defines the process of collecting data from a number of disparate source systems and presenting it in a unified form within a centralized location like a datawarehouse. So, why is data integration such a big deal? Connections to both datawarehouses and data lakes are possible in any case.
Companies that embraced the modern data stack reaped the rewards, namely the ability to make even smarter decisions with even larger datasets. Now more than ten years old, the modern data stack is ripe for innovation. Real-time insights delivered straight to users, i.e. the modern real-time data stack. The problem?
Wealth of Data, Little Observability Those metrics included the data generated by existing and new Seesaw users as they interacted with the service. Storing all of that data was not a problem. Seesaw was able to scale up its main database, an Amazon DynamoDB cloud-based service optimized for large datasets.
The first step in transformation is structural transformations that convert data to a standard format, typically including flattening hierarchical structures and adding missing records. To goal is to create a consistent and coherent dataset compatible with analytical applications and services. featured image via unsplash
Data Pipelines Data lakes continue to get new names in the same year, and it becomes imperative for data engineers to supplement their skills with data pipelines that help them work comprehensively with real-time streams, daily occurrence raw data, and datawarehouse queries.
Examples of Data Wrangling Data wrangling can be applied in various scenarios, making it a versatile and valuable process. Here are some common examples: Merging Data Sources : Combining data from multiple sources into one cohesive dataset for analysis, facilitating comprehensive insights.
ETL (extract, transform, and load) techniques move data from databases and other systems into a single hub, such as a datawarehouse. Get familiar with popular ETLtools like Xplenty, Stitch, Alooma, etc. Different methods are used to store different types of data.
It backs up and restores relational DBMS, NoSQL, datawarehouses, and any other data repository types. The actual mapping and transformation work will be performed using the AWS SCT tool, and a small percentage of manual intervention could be required to map the complex schemas. Is AWS DMS an ETLtool?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content