This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
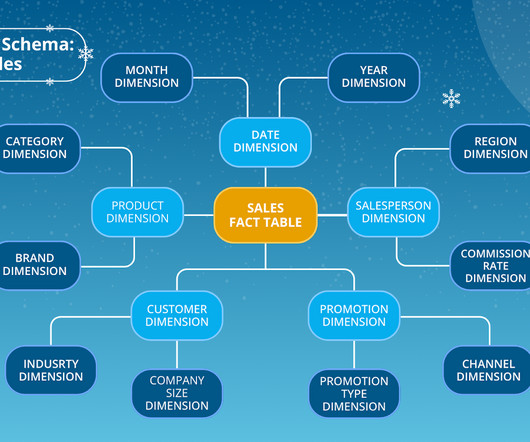
Think of your datawarehouse like a well-organized library. Thats where datawarehouse schemas come in. A datawarehouse schema is a blueprint for how your data is structured and linkedusually with fact tables (for measurable data) and dimension tables (for descriptive attributes).
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera DataWarehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? The DataWarehouse on Cloudera Data Platform provides easy to use self-service and advanced analytics use cases at scale.
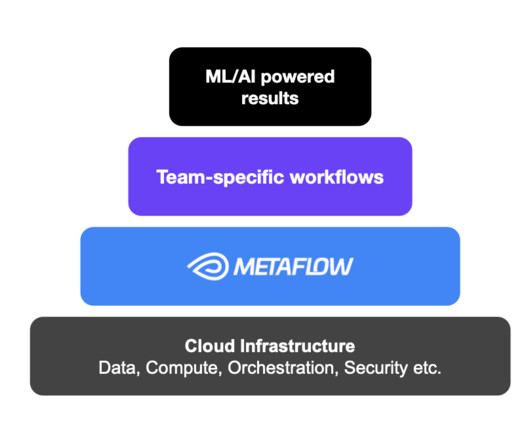
Metaboost serves as a single interface to three different internal platforms at Netflix that manage ETL/Workflows ( Maestro ), Machine Learning Pipelines ( Metaflow ) and DataWarehouse Tables ( Kragle ). training Below is a simple Metaflow pipeline that fetches data, executes feature engineering, and trains a LinearRegression model.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Summary The market for datawarehouse platforms is large and varied, with options for every use case. What are some of the advanced capabilities, such as SQL extensions, supported data types, etc. For someone getting started with Clickhouse can you describe how they should be thinking about data modeling?
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Missing data? Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Now that more and more data warehousing is done in the cloud, much of that in the Cloudera DataWarehousedata service, performance improvement directly equates to cost savings. A recent benchmark by a third party shows how Cloudera has the best price-performance on the cloud datawarehouse market.
For those using a robust analytics database, such as the Snowflake® Data Cloud , adding the power of a data engineering platform can help maximize the value you’re getting out of that database. DataWarehouses Have Boundaries Datawarehouses do what they’re meant to, they provide a high-performance environment for data analytics.
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
At Snowflakes most recent virtual events for industries, Accelerate Retail & Consumer Goods , in partnership with Microsoft, and Accelerate Advertising, Media & Entertainment , attendees heard how industry leaders are accelerating innovation, business insights, customer experience and more with robust enterprise AI and data strategies.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring data accessibility, accuracy, and utility. However, beneath their surface lies a host of invisible risks embedded within the datawarehouse layers.
So, you’re planning a cloud datawarehouse migration. But be warned, a warehouse migration isn’t for the faint of heart. As you probably already know if you’re reading this, a datawarehouse migration is the process of moving data from one warehouse to another. A worthy quest to be sure.
Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a datawarehouse. Batch data integration is useful for data that isn’t extremely time-sensitive. Electric bills are a relevant example.
This includes modeling the lifecycle of your information as a pipeline from the raw, messy, loosely structured records in your data lake, through a series of transformations and ultimately to your datawarehouse. What is your opinion on the relative merits of a datawarehouse vs a data lake and are they mutually exclusive?
." Since joining Google, he's been working on Malloy, a new way to query data. Malloy compiles in SQL and works on data semantics. During the demo, Llyod does some data analysis in the browser and it's just mind-blowing 🤯 At the same time someone Google also did a Calcite presentation.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Just make sure you have enough processes in place to prevent data silos! Data Lakehouse Pattern Data lakehouses are the sporks of architectural patterns – combining the best parts of datawarehouses with data lakes. Plus, data lineage tracking helps you pinpoint exactly where problems originate.
In the beginning, CDP ran only on AWS with a set of services that supported a handful of use cases and workload types: CDP DataWarehouse: a kubernetes-based service that allows business analysts to deploy datawarehouses with secure, self-service access to enterprise data. That Was Then. Learn More, Keep in Touch.
Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. To avoid disruptions to operational databases, companies typically replicate data to datawarehouses for analysis. Small data volumes or hoping to get hands on quickly?
In this blog we will take you through a persona-based data adventure, with short demos attached, to show you the A-Z data worker workflow expedited and made easier through self-service, seamless integration, and cloud-native technologies. Company data exists in the data lake. The Data Scientist.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Unstruk is the DataOps platform for your unstructured data.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Data teams are increasingly under pressure to deliver.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Summary One of the most complex aspects of managing data for analytical workloads is moving it from a transactional database into the datawarehouse. Request a demo at dataengineeringpodcast.com/metis-machine to learn more about how Metis Machine is operationalizing data science.
Your team will get the most complete, accurate and ready-to-use behavioral web and mobile data, delivered into your datawarehouse, data lake and real-time streams. Set up a demo and mention you’re a listener for a special offer! Setting up and managing a datawarehouse for your business analytics is a huge task.
Summary The flexibility of software oriented data workflows is useful for fulfilling complex requirements, but for simple and repetitious use cases it adds significant complexity. Coalesce is a platform designed to reduce repetitive work for common workflows by adopting a visual pipeline builder to support your datawarehouse transformations.
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. The first 25 will receive a free, limited edition Monte Carlo hat!
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Unstruk is the DataOps platform for your unstructured data.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Request a demo at dataengineeringpodcast.com/metis-machine to learn more about how Metis Machine is operationalizing data science. Contact Info LinkedIn Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Missing data? Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. RudderStack helps you build a customer data platform on your warehouse or data lake.
Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Tired of deploying bad data? Need to automate data pipelines with less red tape?
Why data consumers do not trust your reporting — It is a good illustration of the data journey manifesto. Stakeholders often notice data issues before the data team does. Datawarehouses are mutable, this is one of the many root causes proposed by Lucas. Data Documentation 101: Why?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content