This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
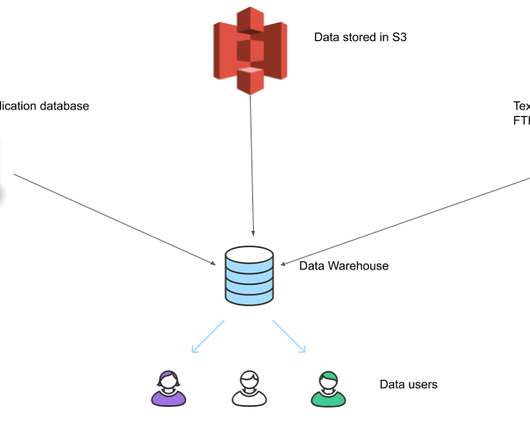
Intro A very common use case in data engineering is to build a ETLsystem for a datawarehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)
Summary The precursor to widespread adoption of cloud datawarehouses was the creation of customer data platforms. Acting as a centralized repository of information about how your customers interact with your organization they drove a wave of analytics about how to improve products based on actual usage data.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Your host is Tobias Macey and today I’m interviewing Brian Leonard about Grouparoo, an open source framework for managing your reverse ETL pipelines Interview Introduction How did you get involved in the area of data management?
This includes the different possible sources of data such as application APIs, social media, relational databases, IoT device sensors, and data lakes. This may include a datawarehouse when it’s necessary to pipeline data from your warehouse to various destinations as in the case of a reverse ETL pipeline.
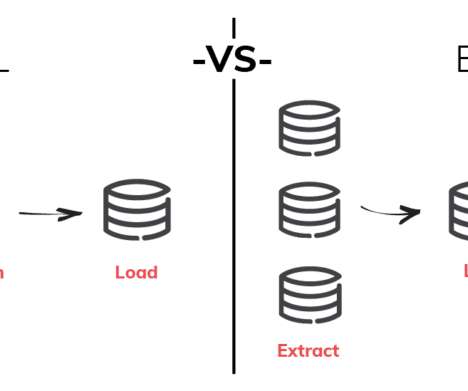
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
ETL testing is also used to verify that the ETL process runs smoothly without any bottlenecks or major performance issues. The testing process is often performed during the initial setup of a datawarehouse after new data sources are added to a pipeline and after data integration and migration projects.
"Hadoop is a key ingredient in allowing LinkedIn to build many of our most computationally difficult features, allowing us to harness our incredible data about the professional world for our users," said Jay Kreps, Principal Engineer, LinkedIn.
Treating batch and streaming as separate pipelines for separate use cases drives up complexity, cost, and ultimately deters data teams from solving business problems that truly require data streaming architectures.
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
Data Pipelines Data lakes continue to get new names in the same year, and it becomes imperative for data engineers to supplement their skills with data pipelines that help them work comprehensively with real-time streams, daily occurrence raw data, and datawarehouse queries.
That's where the ETL (Extract, Transform, and Load) pipeline comes into the picture! Table of Contents What is ETL Pipeline? First, we will start with understanding the Data pipelines with a straightforward layman's example. Now let us try to understand ETLdata pipelines in more detail.
Stop Revenue Bleeding System Modernization and Optimization 33. DataWarehouse (Or Lakehouse) Migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Data observability can help ensure your experimentation program gets off the ground.
Stop Revenue Bleeding System Modernization and Optimization 33. Datawarehouse (or Lakehouse) migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Data observability can help ensure your experimentation program gets off the ground.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content