This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
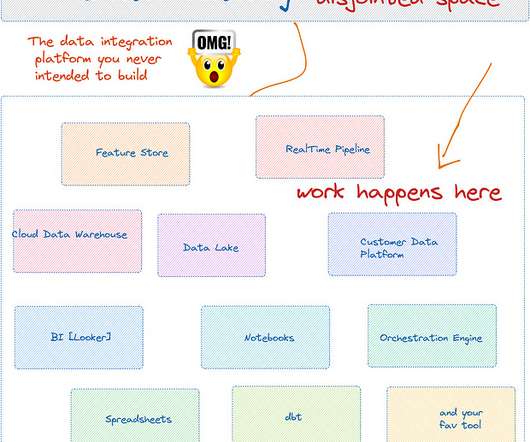
The fact that ETLtools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Let’s highlight the fact that the abstractions exposed by traditional ETLtools are off-target.
Amazon Redshift is a serverless, fully managed leading datawarehouse in the market, and many organizations are migrating their legacy data to Redshift for better analytics. In this blog, we will discuss the best Redshift ETLtools that you can use to load data into Redshift.
Are you trying to better understand the plethora of ETLtools available in the market to see if any of them fits your bill? Are you a Snowflake customer (or planning on becoming one) looking to extract and load data from a variety of sources? If any of the above questions apply to you, then […]
Some of the common challenges with data ingestion in Hadoop are parallel processing, data quality, machine data on a higher scale of several gigabytes per minute, multiple source ingestion, real-time ingestion and scalability. Sqoop hadoop can also be used for exporting data from HDFS into RDBMS.
Tableau has helped numerous organizations understand their customer data better through their Visual Analytics platform. Data Visualization is the next step after the customer data present in rudimentary form has been cleaned, organized, transformed, and placed in a DataWarehouse. […]
Once your datawarehouse is built out, the vast majority of your data will have come from other SaaS tools, internal databases, or customer data platforms (CDPs). Spreadsheets are the Swiss army knife of data processing. Do changes need to be tracked? Where are the files coming from?
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
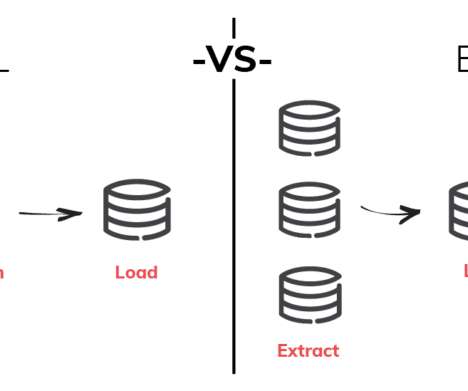
ETL stands for Extract, Transform, and Load. ETL is a process of transferring data from various sources to target destinations/datawarehouses and performing transformations in between to make data analysis ready. Managing data is a tedious task if done manually and leads to no guarantee of accuracy.
AWS Glue is a serverless ETL solution that helps organizations move data into enterprise-class datawarehouses. It provides close integration with other AWS services, which appeals to businesses already invested significantly in AWS.
Ascend is a compelling option for managing these integration workflows, offering automation and scalability to streamline data integration tasks. With its capabilities, users can efficiently extract data from various databases, reconcile differences in formats, and load the integrated data into a datawarehouse or other target systems.
Also, data analysts have a thorough comprehension of statistical ideas and methods. Data Engineer vs Data Analyst: General Requirements Data Engineers must have experience with ETLtools, data warehousing, data modeling, data pipelines, and cloud computing.
What are the core principles of data engineering that have remained from the original wave of ETLtools and rigid datawarehouses? What are some of the new foundational elements of data products that need to be codified for the next generation of organizations and data professionals?
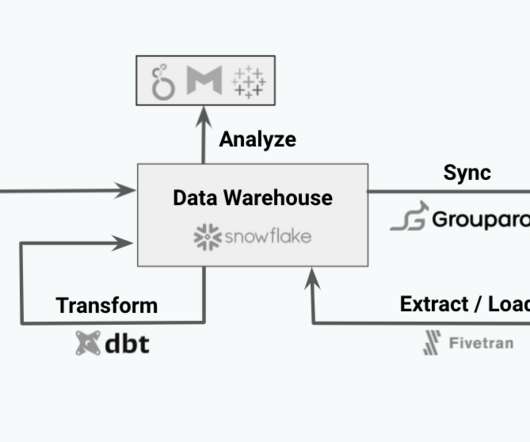
The Modern Data Stack is a recent development in the data engineering space. The core enabler of the Modern Data Stack is that datawarehouse technologies such as Snowflake, BigQuery, and Redshift have gotten fast enough and cheap enough to be considered the source of truth for many businesses.
In the world of data management, ETL (Extract, Transform, Load) tools play a crucial role in ensuring data is efficiently integrated, transformed, and loaded into datawarehouses. The right ETLtools can significantly streamline […]
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
Data Ingestion Data ingestion is the first step of both ETL and data pipelines. In the ETL world, this is called data extraction, reflecting the initial effort to pull data out of source systems. The data sources themselves are not built to perform analytics.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. ETL has typically been carried out utilizing datawarehouses and on-premise ETLtools.
ETL stands for Extract, Transform, and Load, which involves extracting data from various sources, transforming the data into a format suitable for analysis, and loading the data into a destination system such as a datawarehouse. ETL developers play a significant role in performing all these tasks.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
era of Data Catalog Let’s call the pre-modern era; as the state of DataWarehouses before the explosion of big data and subsequent cloud datawarehouse adoption. Applications deployed in a large monolithic web server with all the datawarehouse changes go through a central data architecture team.
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
Secondly , the rise of data lakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
This includes the different possible sources of data such as application APIs, social media, relational databases, IoT device sensors, and data lakes. This may include a datawarehouse when it’s necessary to pipeline data from your warehouse to various destinations as in the case of a reverse ETL pipeline.
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. It’s worth mentioning that its data frame transformations have been included in one of the basic methods of data loading for many modern datawarehouses.
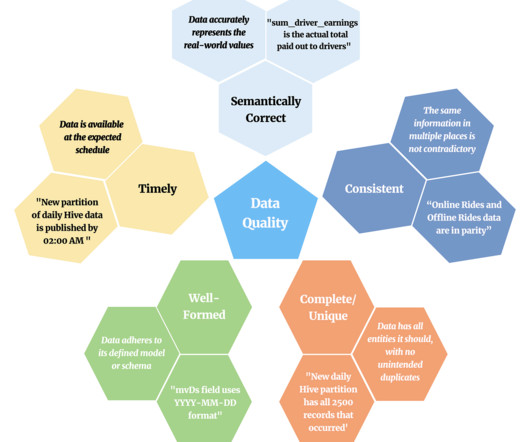
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive DataWarehouse. What and Where is Data Quality?
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange. This indicates the growing use of the ETL process and various ETLtools and techniques across multiple industries.
Modern data teams have all the right solutions in place to ensure that data is ingested, stored, transformed, and loaded into their datawarehouse, but what happens at “the last mile?” In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use?
At the time, the data engineering team mainly used a datawarehouseETLtool called Ab Initio, and an MPP (Massively Parallel Processing) database for warehousing. Both were appliances located in our own data center. The company was primarily thought of as a tech company.
They use Azure Synapse Analytics (previously, Azure SQL DataWarehouse) for developing scalable and high-performance data warehousing solutions. Role Level: Intermediate Responsibilities Design and develop datawarehouse schemas, tables, and indexes using Azure Synapse Analytics.
What you really want is a unified view of your data using Customer Data Integration so you can take action on it. Customer data integration here might include creating a datawarehouse where you can house your accurate and complete dataset. Scalability A datawarehouse can scale well with your data.
ETL, or Extract, Transform, Load, is a process that involves extracting data from different data sources , transforming it into more suitable formats for processing and analytics, and loading it into the target system, usually a datawarehouse. ETLdata pipelines can be built using a variety of approaches.
Loading ChatGPT ETL prompts can help write scripts to load data into different databases, data lakes, or datawarehouses. Simply ask ChatGPT to leverage popular tools or libraries associated with each destination. I'd like to import this data into my MySQL database into a table called products_table.
If you encounter Big Data on a regular basis, the limitations of the traditional ETLtools in terms of storage, efficiency and cost is likely to force you to learn Hadoop. Having said that, the data professionals cannot afford to rest on their existing expertise of one or more of the ETLtools.
The key distinctions between the two jobs are outlined in the following table: Parameter AWS Data Engineer Azure Data Engineer Platform Amazon Web Services (AWS) Microsoft Azure Data Services AWS Glue, Redshift, Kinesis, etc. Azure Data Factory, Databricks, etc.
2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETLtools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. Vendors making claims of being faster than Flink should be viewed with suspicion.
They use tools like Microsoft Power BI or Oracle BI to develop dashboards, reports, and Key Performance Indicator (KPI) scorecards. They should know SQL queries, SQL Server Reporting Services (SSRS), and SQL Server Integration Services (SSIS) and a background in Data Mining and DataWarehouse Design.
Today, organizations are adopting modern ETLtools and approaches to gain as many insights as possible from their data. However, to ensure the accuracy and reliability of such insights, effective ETL testing needs to be performed. So what is an ETL tester’s responsibility? Data integration testing.
The technology was written in Java and Scala in LinkedIn to solve the internal problem of managing continuous data flows. cloud datawarehouses — for example, Snowflake , Google BigQuery, and Amazon Redshift. Moving information from database to database has always been the key activity for ETLtools.
Data tokenization techniques allow the storage of critical data in secure locations while datawarehouses store a token that points to the secure copy. This enables the application of security controls and protection techniques to a subset of data, transparent to processes accessing the datawarehouse.
Meltano is a DataOps platform that enables data engineers to streamline data management and keep all stages of data production in a single place. Analysis While data engineers don’t typically analyze data, they can prepare the data for analysis for data scientists and business analysts to access and derive insights.
Cloud datawarehouses solve these problems. Belonging to the category of OLAP (online analytical processing) databases, popular datawarehouses like Snowflake, Redshift and Big Query can query one billion rows in less than a minute. What is a datawarehouse?
It is the process of extracting data from various sources, transforming it into a format suitable for analysis, and loading it into a target database or datawarehouse. ETL is used to integrate data from different sources and formats into a single target for analysis. What is an ETL Pipeline?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






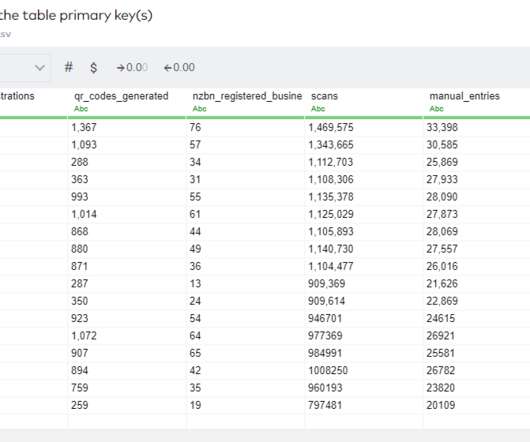






































Let's personalize your content