This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
These stages propagate through various systems including function-based systems that load, process, and propagate data through stacks of function calls in different programming languages (e.g., For simplicity, we will demonstrate these for the web, the datawarehouse, and AI, per the diagram below. Hack, C++, Python, etc.)
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
[link] Netflix: Netflix’s Distributed Counter Abstraction Netflix writes about scalable Distributed Counter abstractions for accurately counting events across its global services with millisecond latency. The service offers configurable counter types optimized for various use cases with a unified Control Plane configuration.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
When functions are “pure” — meaning they do not have side-effects — they can be written, tested, reasoned-about and debugged in isolation, without the need to understand external context or history of events surrounding its execution. But how do we model this in a functional datawarehouse without mutating data?
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. To avoid disruptions to operational databases, companies typically replicate data to datawarehouses for analysis.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. What are the most interesting, innovative, or unexpected ways that you have seen column-aware data modeling used?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. What you have to code is this workflow !
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
The datawarehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “ the datawarehouse is broken ” on LinkedIn. Treating data like an API. Immutable datawarehouses have challenges too.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. Interview Introduction How did you get involved in the area of data management?
Our investments in a lakeless datawarehouse, modern analytics platform, and strong master data practices have made data a core strategic capability. The Turning Point: Year3 At Picnic we had a DataWarehouse from the start, from the very first order. The challenges were multi-dimensional (pun intended).
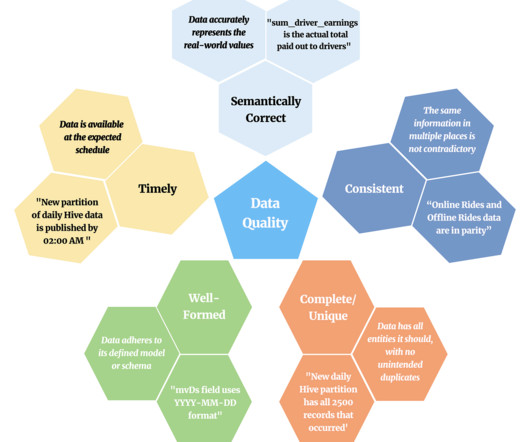
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive DataWarehouse. What and Where is Data Quality?
Like the staging environment, Fronting Kafka receives all the events without validation. A streaming consumer, often implemented in stream processing frameworks like Flink or Spark, consumes the events from the fronting Kafka and runs through data contract validation. Event Routers typically don’t alter the payload.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. How does SaasGlue manage metadata propagation throughout the execution graph?
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. We use Snowflake as our datawarehouse where we build dashboards both for internal use and for customers. So our solution was to start using an intentional contract: Events.
They are working through organizational design challenges while also establishing foundational data management capabilities like metadata management and data governance that will allow them to offer trusted data to the business in a timely and efficient manner for analytics and AI.”
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
They explain how to think about your data systems in a holistic and maintainable fashion, the security challenges that threaten to derail your efforts, and the power of using metadata as the foundation of everything that you do. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
In truth, the synergy between batch and streaming pipelines is essential for tackling the diverse challenges posed to your data platform at scale. The key to seamlessly addressing these challenges lies, unsurprisingly, in data orchestration. Their robust core offering seamlessly integrates datawarehouses with data-hungry applications.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. How do you structure the log events and metadata to provide detail and context for data applications?
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
However, for all of our uncertified data, which remained the majority of our offline data, we lacked visibility into its quality and didn’t have clear mechanisms for up-leveling it. How could we scale the hard-fought wins and best practices of Midas across our entire datawarehouse?
Moreover, it facilitates the implementation of microservices architectures and event-driven systems, automating reactions to data changes without manual intervention. It captures incremental changes from transactional databases or other sources, efficiently loading them into datawarehouses or data lakes.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content