This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Data lakes are notoriously complex. Data lakes are notoriously complex. Go to dataengineeringpodcast.com/dagster today to get started.
In todays data-driven world, organizations depend on high-qualitydata to drive accurate analytics and machine learning models. But poor dataquality gaps, inconsistencies and errors can undermine even the most sophisticated data and AI initiatives.
In order to build high-qualitydata lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Hack, C++, Python, etc.)
Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads? Hightouch is the easiest way to sync data into the platforms that your business teams rely on. The data you’re looking for is already in your datawarehouse and BI tools. No more scripts, just SQL.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Starburst : ![Starburst
In this episode Tasso Argyros, CEO of ActionIQ, gives a summary of the major epochs in database technologies and how he is applying the capabilities of cloud datawarehouses to the challenge of building more comprehensive experiences for end-users through a modern customer data platform (CDP).
Data lakes are notoriously complex. For data engineers who battle to build and scale highqualitydata workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake.
This involves integrating customer data across various channels – like your CRM systems, datawarehouses, and more – so that the most relevant and up-to-date information is used consistently in your customer interactions. Focus on high-qualitydata. Dataquality is essential for personalization efforts.
There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate. Data Storage Solutions As we all know, data can be stored in a variety of ways.
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of DataQuality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
Shifting left involves moving data processing upstream, closer to the source, enabling broader access to high-qualitydata through well-defined data products and contracts, thus reducing duplication, enhancing data integrity, and bridging the gap between operational and analytical data domains.
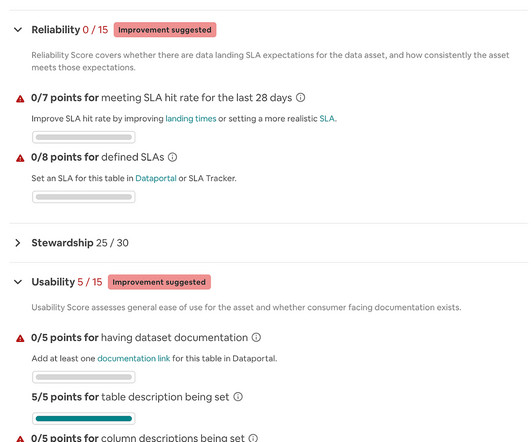
The importance of dataquality within an organization cannot be overemphasized as it is a critical aspect of running and maintaining an efficient datawarehouse. High-qualitydata ensures that organizations make data-driven decisions to […]
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
As the appetite for Hadoop and related big data technologies grows at an exponential rate, it is not out to spell the death of data warehousing. Data warehousing as a technology is evolving. DataWarehouse – Decide Which One to Use When Hadoop vs DataWarehouse Shocking Headlines like “Is datawarehouse dead?”,
However, for all of our uncertified data, which remained the majority of our offline data, we lacked visibility into its quality and didn’t have clear mechanisms for up-leveling it. How could we scale the hard-fought wins and best practices of Midas across our entire datawarehouse?
With this announcement, we welcome our customer data teams to streamline data transformation pipelines in their open data lakehouse using any engine on top of data in any format in any form factor and deliver highqualitydata that their business can trust. The Open Data Lakehouse .
High-qualitydata is necessary for the success of every data-driven company. It is now the norm for tech companies to have a well-developed data platform. This makes it easy for engineers to generate, transform, store, and analyze data at the petabyte scale. What and Where is DataQuality?
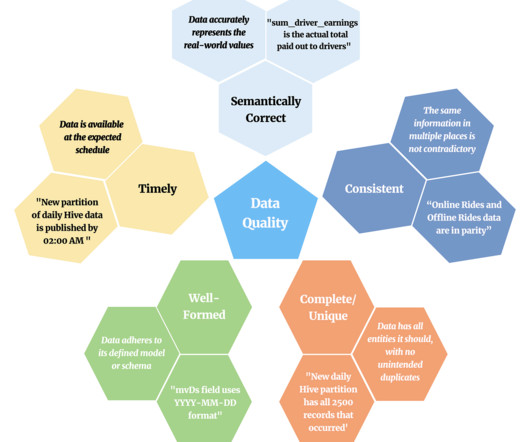
Consistent: Data is consistently represented in a standard way throughout the dataset. Qualitydata must meet all these criteria. If it is lacking in just one way, it could compromise any data-driven initiative. However, simply having high-qualitydata does not, of itself, ensure that an organization will find it useful.
It then passes through various ranking systems like Mustang, Superroot, and NavBoost, which refine the results to the top 10 based on factors like content quality, user behavior, and link analysis. The author writes an overview of the performance implication of disaggregated systems compared to traditional monolithic databases.
With DBT, they weave powerful SQL spells to create data models that capture the essence of their organization’s information. DBT’s superpowers include seamlessly connecting with databases and datawarehouses, performing amazing transformations, and effortlessly managing dependencies to ensure high-qualitydata.
link] Intel: Four Data Cleaning Techniques to Improve Large Language Model (LLM) Performance If someone asks me to define LLM, this is my one-line definition. Large Language Models: Turning messy data into surprisingly coherent nonsense since 2023. High-qualitydata is the cornerstone of LLM.
It’s too hard to change our IT data product. Can we create high-qualitydata in an “answer-ready” format that can address many scenarios, all with minimal keyboarding? . “I I get cut off at the knees from a data perspective, and I am getting handed a sandwich of sorts and not a good one!”.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. But they should!
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. But they should!
Their strategic approach to adopting technological solutions, particularly through the integration of Striim for real-time data analytics, positions Kramp as a visionary in leveraging technology for business growth and efficiency in agriculture.
A data fabric offers several key benefits that transform your data management: Accelerates analytics and decision-making processes by enhancing data accessibility through seamless data integration and retrieval across diverse environments. Increase metadata maturity.
During this transformation, Airbnb experienced the typical growth challenges that most companies do, including those that affect the datawarehouse. In the first post of this series, we shared an overview of how we evolved our organization and technology standards to address the dataquality challenges faced during hyper growth.
And this renewed focus on dataquality is bringing much needed visibility into the health of technical systems. As generative AI (and the data powering it) takes center stage, it’s critical to bring this level of observability to where your data lives, in your datawarehouse , data lake , or data lakehouse.
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern datawarehouses and quickly expanded our support as data lakes became data lakehouses.
Carefully curated test data (realistic samples, edge cases, golden datasets) that reveal issuesearly. Proper tooling & environment (Python ecosystem for Great Expectations, datawarehouse credentials and macros fordbt).
It also came with other advantages such as independence of cloud infrastructure providers, data recovery features such as Time Travel , and zero copy cloning which made setting up several environments — such as dev, stage or production — way more efficient.
We’ll then discuss how they can be avoided with an organizational commitment to high-qualitydata. Imagine this You’re a data scientist with a swagger working on a predictive model to optimize a fast-growing company’s digital marketing spend. The datawarehouse is a mess and devoid of semantic meaning.
They need high-qualitydata in an answer-ready format to address many scenarios with minimal keyboarding. What they are getting from IT and other data sources is, in reality, poor-qualitydata in a format that requires manual customization. DataOps Process Hub.
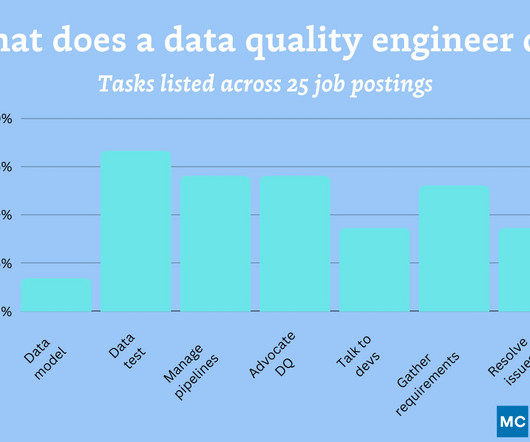
These specialists are also commonly referred to as data reliability engineers. To be successful in their role, dataquality engineers will need to gather dataquality requirements (mentioned in 65% of job postings) from relevant stakeholders.
Understanding the “rise of data downtime” With a greater focus on monetizing data coupled with the ever present desire to increase data accuracy, we need to better understand some of the factors that can lead to data downtime. We’ll take a closer look at variables that can impact your data next.
Choosing one tool over another isn’t just about the features it offers today; it’s a bet on the future of how data will flow within organizations. Matillion is an all-in-one ETL solution that stands out for its ability to handle complex data transformation tasks in all the popular cloud datawarehouses.
The article about data asset pricing is one of the comprehensive thoughts I came across about pricing models, establishing two basic factors. Data value depends on the users and the use cases Dataquality is multi-dimensional, and high-qualitydata costs more. Register now and join us on May 22nd!
It moved from the speculation to the data engineers understanding the benefit of it and asking when we can get the implementation soon. I met many data leaders about Data Contracts, my project Schemata, and how the extended version we are building can help them create high-qualitydata.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
Here are some of the common types: DataWarehouses: A datawarehouse is a centralized repository of information that can be used for reporting and analysis. Datawarehouses typically contain historical data that can be used to track trends over time.
While different solutions or tools may have significant differences in features offered, there is no real difference between data observability and data reliability engineering. Both terms are focused on the practice of ensuring healthy, highqualitydata across an organization. It is still relevant today.
And this renewed focus on dataquality is bringing much needed visibility into the health of technical systems. As generative AI (and the data powering it) takes center stage, it’s critical to bring this level of observability to where your data lives, in your datawarehouse , data lake , or data lakehouse.
Our perspective: How Gartner differentiates between traditional dataquality monitoring and data observability is crucial for understanding their mandatory features. In our experience, static, event-based monitoring – SQL monitors, data testing, etc.
Reporting, querying, and analyzing structured data to generate actionable insights. Data Sources Diverse and vast data sources, including structured, unstructured, and semi-structured data. Structured data from databases, datawarehouses, and operational systems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content