This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In order to build high-qualitydata lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Hack, C++, Python, etc.)
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of DataQuality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
However, for all of our uncertified data, which remained the majority of our offline data, we lacked visibility into its quality and didn’t have clear mechanisms for up-leveling it. How could we scale the hard-fought wins and best practices of Midas across our entire datawarehouse?
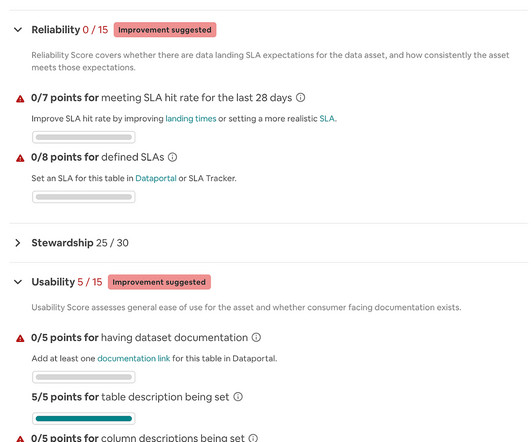
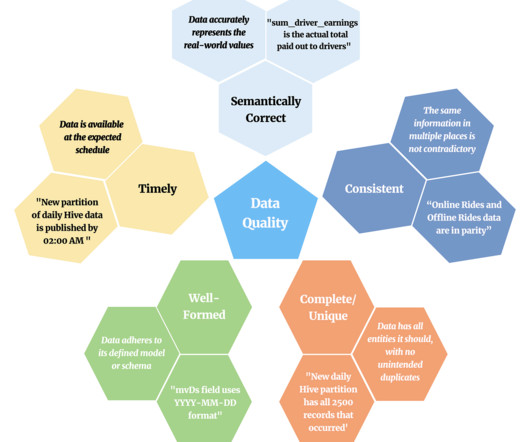
High-qualitydata is necessary for the success of every data-driven company. It is now the norm for tech companies to have a well-developed data platform. This makes it easy for engineers to generate, transform, store, and analyze data at the petabyte scale. What and Where is DataQuality?
With this announcement, we welcome our customer data teams to streamline data transformation pipelines in their open data lakehouse using any engine on top of data in any format in any form factor and deliver highqualitydata that their business can trust. The Open Data Lakehouse .
It then passes through various ranking systems like Mustang, Superroot, and NavBoost, which refine the results to the top 10 based on factors like content quality, user behavior, and link analysis. The author did an amazing job of describing how Parquet stores the data and compression and metadata strategies.
Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata. As data grows exponentially, so do the complexities of managing and leveraging it to fuel AI and analytics.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Metadata layer 4.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Metadata layer 4.
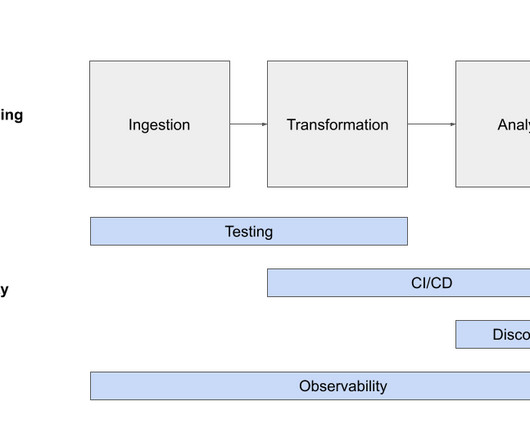
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern datawarehouses and quickly expanded our support as data lakes became data lakehouses.
Carefully curated test data (realistic samples, edge cases, golden datasets) that reveal issuesearly. Proper tooling & environment (Python ecosystem for Great Expectations, datawarehouse credentials and macros fordbt).
Data lineage provides the answer by telling you which upstream sources and downstream ingestors were impacted, as well as which teams are generating the data and who is accessing it. Both terms are focused on the practice of ensuring healthy, highqualitydata across an organization. It is still relevant today.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , datawarehouses , data lakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
Adopting a cloud datawarehouse like Snowflake is an important investment for any organization that wants to get the most value out of their data. This query will fetch a list of all tables within a database, along with helpful metadata about their settings.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-qualitydata. Here lies the critical role of data engineering: preparing and managing data to feed AI models.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
In addition to discussing what the data observability category is, Gartner also makes a point to explain how it’s both different and complements traditional dataquality approaches, as well as the vendors placed in their augmented dataquality category that have their own critical capabilities—some of which overlap.
How does it impact datawarehouse/lakehouse performance? Data observability tools should offer both broad automated metadata monitoring across all the tables once they have been added to your selected schemas, as well as deep monitoring for issues inherent in the data itself. Robust role based access controls?
At some point in the last two decades, the size of our data became inextricably linked to our ego. We watched enviously as FAANG companies talked about optimizing hundreds of petabyes in their data lakes or datawarehouses. We imagined what it would be like to manage big dataquality at that scale.
Whether it be the marketing team seeking customer insights, the finance team working on budgeting, or executives crafting business strategies, data needs to be shared in a manner that aligns with their specific objectives and competencies. It is the stage where data truly becomes a product, delivering tangible value to its end users.
Often, teams run custom data tests as part of a deployment pipeline, or scheduled on production systems via job schedulers like Apache Airflow, dbt Cloud, or via in-built schedulers in your datawarehouse solution. We could talk dataquality all day long. Here are some common use cases for dbt tests.
“What excites me about Monte Carlo is their vision for making the delivery of data more reliable and transparent through observability. Their artificial intelligence data-driven platform relies on high-qualitydata to make coverage recommendations for customers.
DataWarehouse (Or Lakehouse) Migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Another common breaking schema change scenario is when data teams sync their production database with their datawarehouse as is the case with Freshly.
Datawarehouse (or Lakehouse) migration 34. Integrate Data Stacks Post Merger 35. Know When To Fix Vs. Refactor Data Pipelines Improve DataOps Processes 37. “We Another common breaking schema change scenario is when data teams sync their production database with their datawarehouse as is the case with Freshly.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content