This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python and Java still leads the programming language interest, but with a decrease in interest (-5% and -13%) while Rust gaining traction (+13%), not sure it's related, tho. He listed 4 things that are the most difficult data integration tasks: from mutable data to IT migrations, everything adds complexity to ingestion systems.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Multiple open source projects and vendors have been working together to make this vision a reality.
Obviously Benoit prefers Kestra, at the expense of writing YAML and running a Java application. Arrow doing a lot of the data operation heavy lifting. New Apache Arrow engines — Arrow has become one of the most used library when it comes to built in-memory engines.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Try Cloudera DataWarehouse (CDW) by signing up for a 60 day trial , or test drive CDP.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with What's Iceberg?
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. The result is that streaming data tends to be “locked away” from everyone but a small few, and the data engineering team is highly overworked and backlogged. A rare breed.
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management. Data Storage Solutions As we all know, data can be stored in a variety of ways.
How to reduce warehouse costs? — Hugo propose 7 hacks to optimise datawarehouse cost. Scrape & analyse football data — Benoit nicely put in perspective how to use Kestra, Malloy and DuckDB to analyse data. teej/titan — Titan is a Python library to manage datawarehouse infrastructure.
Agent systems powered by LLMs are already transforming how we code and interact with data. I converted a Java streaming platform into Rust, completing the task faster and gaining valuable insights into Rust's intricacies. These systems provided centralized data storage and processing at the cost of agility.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. My advice on this point is to learn from others.
What we need is: An openness to support a wide range in streaming ingest sources, including NiFi, Spark Streaming, Flink, as well as APIs for languages like C++, Java, and Python. The ability to support not just “insert” type data changes, but Insert+update patterns as well, to accommodate both new data, and changing data.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Links Database Refactoring Website Book Thoughtworks Martin Fowler Agile Software Development XP (Extreme Programming) Continuous Integration The Book Wikipedia Test First Development DDL (Data Definition Language) DML (Data Modification Language) DevOps Flyway Liquibase DBMaintain Hibernate SQLAlchemy ORM (Object Relational Mapper) ODM (Object Document (..)
In the early days, data was the foundation to support basic operations and learn how to achieve operational excellence. Over time, data became the driver for strategic decision-making and innovation. Our journey began by building a strong Master Data Foundation , which laid the groundwork for our first generation of systems.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
The Apache Iceberg project continues developing an implementation of Iceberg specification in the form of Java Library. Several compute engines such as Impala, Hive, Spark, and Trino have supported querying data in Iceberg table format by adopting this Java Library provided by the Apache Iceberg project.
What is a typical workflow for someone using Compilerworks to manage their data lineage? How does Compilerworks simplify the process of migrating between datawarehouses/processing platforms? What is a typical workflow for someone using Compilerworks to manage their data lineage?
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the datawarehouse? Dataform picks up where your ETL jobs leave off, turning raw data into reliable analytics.
Contrast this with the skills honed over decades for gaining access, building datawarehouses, performing ETL, creating reports and/or applications using structured query language (SQL). Benefits of Streaming Data for Business Owners. A rare breed. What does all this mean for those in business leadership roles? .
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
How Mixpanel delivers funnels up to 7x faster than the datawarehouse — Mixpanel team is proud to say that they have better performance than Snowflake. It's written in Java and it does what other orchestrator are already doing. I think it will unlock a lot of use-cases in BigQuery. Curious to see if it will pick up.
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Data professionals are not perfectly interchangeable.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
Snowplow takes care of everything from installing your pipeline in a couple of hours to upgrading and autoscaling so you can focus on your exciting data projects. Your team will get the most complete, accurate and ready-to-use behavioral web and mobile data, delivered into your datawarehouse, data lake and real-time streams.
You have full control over your data and their plugin system lets you integrate with all of your other data tools, including datawarehouses and SaaS platforms. How do you maintain feature parity between the Python and Java integrations? How do you maintain feature parity between the Python and Java integrations?
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
Datawarehouses are optimized for batched writes and complex analytical queries. Between those use cases there are varying levels of support for fast reads on quickly changing data. Datawarehouses are optimized for batched writes and complex analytical queries.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
In order to quickly identify if and how two data systems are out of sync Gleb Mezhanskiy and Simon Eskildsen partnered to create the open source data-diff utility. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Summary The "data lakehouse" architecture balances the scalability and flexibility of data lakes with the ease of use and transaction support of datawarehouses. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The two most popular datawarehouse systems are Teradata and Oracle Exadata.
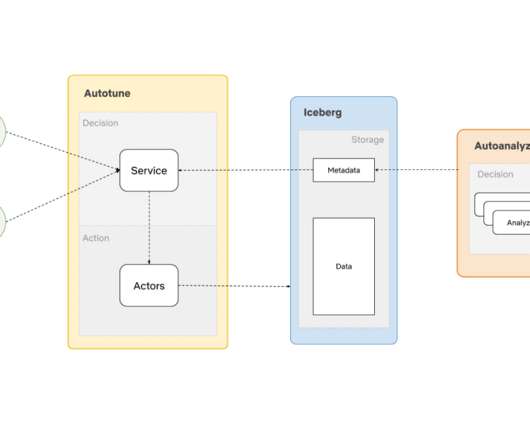
The CDC events are passed on to the Data Mesh enrichment processor, which issues GraphQL queries to Studio Edge to enrich the data. Once the data has landed in the Iceberg tables in Netflix DataWarehouse, they could be used for ad-hoc or scheduled querying and reporting. Currently Iceberg sink is appended only.
In the second blog of the Universal Data Distribution blog series , we explored how Cloudera DataFlow for the Public Cloud (CDF-PC) can help you implement use cases like data lakehouse and datawarehouse ingest, cybersecurity, and log optimization, as well as IoT and streaming data collection.
A degree in computer science, software engineering, or a similar subject is often required of data engineers. They have extensive knowledge of databases, data warehousing, and computer languages like Python or Java. Also, data engineers are well-versed in distributed systems, cloud computing, and data modeling.
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in datawarehouses and various modeling techniques. For analytical systems there are decades of investment in datawarehouses and various modeling techniques.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content