This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this guide, we’ll explore the patterns that can help you design data pipelines that actually work. Table of Contents Common Data Pipeline Design Patterns Explained 1. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5. Data Mesh Pattern 8. Batch Processing Pattern 2.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. The Lambdaarchitecture has largely been abandoned, so what is the answer for today’s data lakes?
This conversation was useful for getting a better idea of the challenges that exist in large scale data analytics, and the current state of the tradeoffs between data lakes and datawarehouses in the cloud. What are some of the common antipatterns in data lake implementations and how does Delta Lake address them?
You monitor your website to make sure that you’re the first to know when something goes wrong, but what about your data? Tidy Data is the DataOps monitoring platform that you’ve been missing. You monitor your website to make sure that you’re the first to know when something goes wrong, but what about your data?
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day.
How does the introduction of a universal SQL layer change the staffing requirements for building and maintaining a data lake? What are the advantages of a data lake over a datawarehouse if everything is being managed via SQL anyway?
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. What is Real Time Data Warehousing?
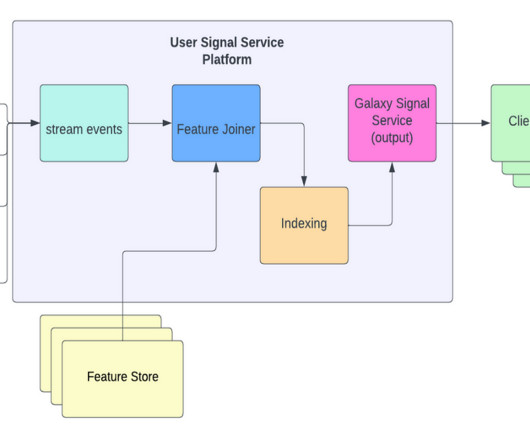
This platform is also a key component for PinnerFormer work providing real-time user sequence data. Real-Time Indexing Pipeline The main goal of the real-time indexing pipeline is to enrich, store, and serve the last few relevant user actions as they come in. To explore life at Pinterest, visit our Careers page.
The platform approach to enable the citizen machine learning engineers is a great perspective while building both the Data & ML platform. Architectural patterns like LambdaArchitecture and Kappa Architecture emerged to bridge the gap between real-time and batch data processing.
Data ingestion is the process of collecting data from various sources and moving it to your datawarehouse or lake for processing and analysis. It is the first step in modern data management workflows. Source : Fundamentals of Data Engineering by Joe Reis and Matt Housley. There are trade-offs.
Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis. Data Analytics: A data engineer works with different teams who will leverage that data for business solutions.
A typical use case is building a DataWarehouse for batch processing and daily reporting. The Spark data frames abstraction has been used as a generic ingestion platform capable of ingesting data from multiple sources of different formats. This has been made possible due to Spark to a great extent.
There are many uses and benefits for real-time traffic simulation and prediction projects using big data. This project is a LambdaArchitecture program that tracks Chicago's streets' traffic conditions, including congestion and safety. Simulating real-time traffic has successfully been modeled.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content