This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt Core is an open-source framework that helps you organise datawarehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Performance is one of the key, if not the most important deciding criterion, in choosing a Cloud DataWarehouse service. In today’s fast changing world, enterprises have to make data driven decisions quickly and for that they rely heavily on their datawarehouse service. . Cloudera DataWarehouse vs HDInsight.
These stages propagate through various systems including function-based systems that load, process, and propagate data through stacks of function calls in different programming languages (e.g., For simplicity, we will demonstrate these for the web, the datawarehouse, and AI, per the diagram below. Hack, C++, Python, etc.)
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. This is Croissant. Starting today it will be supported by 3 majors platforms: Kaggle, HuggingFace and OpenML.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
In this blog post, we compare Cloudera DataWarehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 Cloudera DataWarehouse vs EMR. Learn more about Cloudera DataWarehouse on CDP.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. What are some of the challenges and mistakes that are common among engineers and analysts with regard to versioning and evolving schemas and the accompanying data?
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structured data to a modern platform.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Try Cloudera DataWarehouse (CDW) by signing up for a 60 day trial , or test drive CDP.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Meta joins the Data Transfer Project and has continuously led the development of shared technologies that enable users to port their data from one platform to another. 2024: Users can access data logs in Download Your Information. What are data logs?
link] Jon Osborn: Best Practices for Using QUERY_TAG in Snowflake The modern datawarehouses are good at running at scale, given the cost is not a constraint. The service offers configurable counter types optimized for various use cases with a unified Control Plane configuration. I’ve seen a similar work by Ben E.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Summary Cloud datawarehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. What you have to code is this workflow !
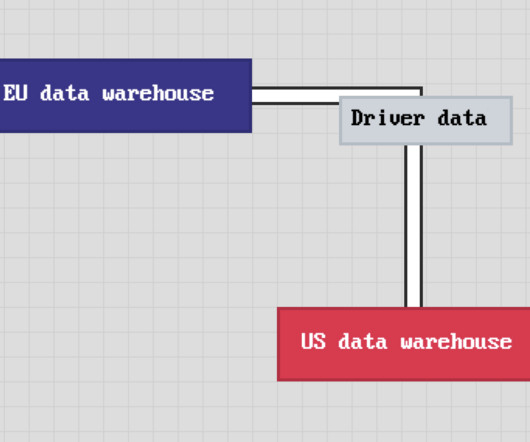
This truth was hammered home recently when ride-hailing giant Uber found itself on the receiving end of a staggering €290 million ($324 million) fine from the Dutch Data Protection Authority. Poor datawarehouse governance practices that led to the improper handling of sensitive European driver data. The reason?
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
Why worry about costs with cloud-native data warehousing? Have you been burned by the unexpected costs of a cloud datawarehouse? If not, before adopting a cloud datawarehouse, consider the true costs of a cloud-native datawarehouse. These costs impede the adoption of cloud-native datawarehouses.
Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. To avoid disruptions to operational databases, companies typically replicate data to datawarehouses for analysis.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix datawarehouse.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
Summary Building a well managed data ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
Note that where a TRUNCATE PARTITION is typically a “free” metadata operation, a DELETE operation may be expensive and that should be taken into considerations. This means that ideally the logic in source control describes how to build the full state of the datawarehouse throughout all time periods.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.
Take advantage of old school databasetricks In the last 1015 years weve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, datawarehouses, and new tools (lots and lots of newtools). Consequently, weve had to say goodbye to some things to make room for all this new stuff.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content