This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt Core is an open-source framework that helps you organise datawarehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
Meta joins the Data Transfer Project and has continuously led the development of shared technologies that enable users to port their data from one platform to another. 2024: Users can access data logs in Download Your Information. What are data logs?
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
Setting the Stage: We need E&L practices, because “copying rawdata” is more complex than it sounds. For instance, how would you know which orders got “canceled”, an operation that usually takes place in the same data record and just “modifies” it in place.
While business rules evolve constantly, and while corrections and adjustments to the process are more the rule than the exception, it’s important to insulate compute logic changes from data changes and have control over all of the moving parts. But how do we model this in a functional datawarehouse without mutating data?
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring data accessibility, accuracy, and utility. However, beneath their surface lies a host of invisible risks embedded within the datawarehouse layers.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
At TCS , we help companies shift their enterprise datawarehouse (EDW) platforms to the cloud as well as offering IT services. We’re extremely familiar with just how tricky a cloud migration can be, especially when it involves moving historical business data. How many tables and views will be migrated, and how much rawdata?
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. How Does AWS Glue Work?
Data Store Another significant change from 2021 to 2024 lies in the shift from “DataWarehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of Data Lakes. Their robust core offering seamlessly integrates datawarehouses with data-hungry applications.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a datawarehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
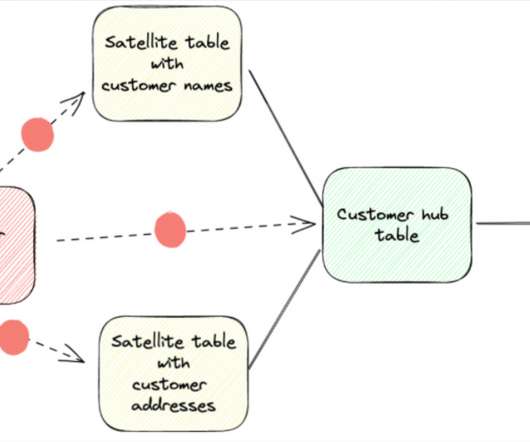
Over the past several years, datawarehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound data architecture needs to be thrown out the window. What is a Data Vault model? The data vault paradigm addresses the desire to overlay organization on top of semi-permanent rawdata storage.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. It is designed to be easily queryable with SQL even for large analytic tables (we’re talking petabytes of data). How Apache Iceberg tables structure metadata.
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Datawarehouse vs. data lake in a nutshell.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. ETL has typically been carried out utilizing datawarehouses and on-premise ETL tools.
Secondly , the rise of data lakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape. Read More: What is ETL?
Traditionally, after being stored in a data lake, rawdata was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. See our post: Data Lakes vs. DataWarehouses.
The data products are packaged around the business needs and in support of the business use cases. This step requires curation, harmonization, and standardization from the rawdata into the products. Luke: Let’s talk about some of the fundamentals of modern data architecture. What is a data fabric?
Two different data modeling approaches—dimensional data modeling and Data Vault—each have their own pros and cons. Modernizing a datawarehouse with Snowflake Data Cloud is a smart investment that can provide significant benefits to businesses of all sizes, today more than ever as data models become ever more complex.
This week, we got to think about our data ingestion design. We looked at the following: How do we ingest – ETL vs ELT Where do we store the data – Data lake vs datawarehouse Which tool to we use to ingest – cronjob vs workflow engine NOTE : This weeks task requires good internet speed and good compute.
What is data curation? Data curation is the process of transforming and enriching larger amounts of rawdata into smaller, more widely accessible subsets of data that provide additional value to the organization or the intended use case. It would also make the data engineering team a bottleneck.
Over the past several years, cloud data lakes like Databricks have gotten so powerful (and popular) that according to Mordor Intelligence , the data lake market is expected to grow from $3.74 Traditionally, data lakes held rawdata in its native format and were known for their flexibility, speed, and open source ecosystem.
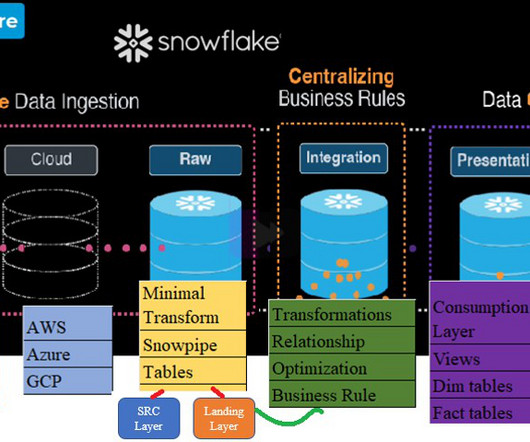
Secondly, Define Business Rules : Develop the transformation on RAWdata and include the Business logic. Develop the relationship among different sources table to produce meaningful data. Thirdly, Data Consumption: Develop the Views on Transformed or aggregated tables. Snowpipe to automate the ingestion process.
Those tasks are saving the extracted data in the data lake (or warehouse or lakehouse). Other tasks, probably SQL jobs orchestrated with DBT, are running transformation on the loaded data. They are querying rawdata tables, enriching them, joining between tables, and creating business data – all ready to be used.
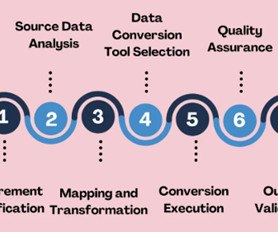
Selecting the strategies and tools for validating data transformations and data conversions in your data pipelines. Introduction Data transformations and data conversions are crucial to ensure that rawdata is organized, processed, and ready for useful analysis.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
is whether to choose a datawarehouse or lake to power storage and compute for their analytics. While datawarehouses provide structure that makes it easy for data teams to efficiently operationalize data (i.e., Data discovery tools and platforms can help. Image courtesy of Adrian on Unsplash.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. RudderStack builds your CDP on top of your datawarehouse, giving you a more secure and cost-effective solution.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from datawarehouses and data lakes. What is Data Hub?
Now that we have understood how much significant role data plays, it opens the way to a set of more questions like How do we acquire or extract rawdata from the source? How do we transform this data to get valuable insights from it? Where do we finally store or load the transformed data?
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
It is a data integration process with which you first extract raw information (in its original formats) from various sources and load it straight into a central repository such as a cloud datawarehouse , a data lake , or a data lakehouse where you transform it into suitable formats for further analysis and reporting.
DBT, which stands for Data Build Tool, is a powerful tool designed to transform and manage data in a scalable and reproducible manner. It allows data engineers to define and execute data transformations in a structured and modular way. Initialize the Airflow metadata database by running airflow initdb in your terminal.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Other models were also evaluated including BERT , a model trained on a big corpus of text data, but found that BERT was better suited for word embeddings than sentence embeddings and was pre-trained only in English. Due to the large number of listings at eBay, the data is loaded in batches to HDFS, eBay’s datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content