This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
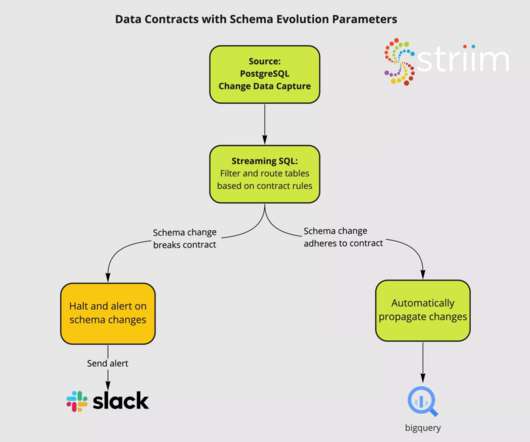
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
To address this, they focused on creating an experimentation-oriented culture, enabled thanks to a cloud-native platform supporting the full data lifecycle. This platform, including an ad-hoc capable datawarehouse service with built-in, easy-to-use visualization, made it easy for anyone to jump in and start experimenting.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
Want to learn more about data governance? Check out our Data Governance on Snowflake blog! Metadata Management Data modeling methodologies help in managing metadata within the data lake. Metadata describes the characteristics, attributes, and context of the data.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Data storage and compute are very much the foundation of your data platform. Let’s jump in! So, let’s take a look at each in a bit more detail.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs data lake vs data lakehouse: What’s the difference.
To differentiate and expand the usefulness of these models, organizations must augment them with first-party data – typically via a process called RAG (retrieval augmented generation). Today, this first-party data mostly lives in two types of data repositories.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value. Enter Snowpark !
Before going into further details on Delta Lake, we need to remember the concept of Data Lake, so let’s travel through some history. The main player in the context of the first data lakes was Hadoop, a distributed file system, with MapReduce, a processing paradigm built over the idea of minimal data movement and high parallelism.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. Data integration with ETL has changed in the last three decades. But cloud computing is preferred over the other.
Snowflake Overview A datawarehouse is a critical part of any business organization. Lot of cloud-based datawarehouses are available in the market today, out of which let us focus on Snowflake. Snowflake is an analytical datawarehouse that is provided as Software-as-a-Service (SaaS).
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of datawarehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Datawarehouse vs. data lake in a nutshell.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. See our post: Data Lakes vs. DataWarehouses.
A Better Way Forward: Cloudera’s Open Data Lakehouse Cloudera offers a solution to these challenges with its open data lakehouse, which combines the flexibility and scalability of data lake storage with datawarehouse functionality to unify and simplify the management of cyber log data.
is whether to choose a datawarehouse or lake to power storage and compute for their analytics. While datawarehouses provide structure that makes it easy for data teams to efficiently operationalize data (i.e., Data discovery tools and platforms can help. Image courtesy of Adrian on Unsplash.
At its core, BigQuery is a serverless DataWarehouse for analytical purposes and built-in features like Machine Learning ( BigQuery ML ). The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
This week, we got to think about our data ingestion design. We looked at the following: How do we ingest – ETL vs ELT Where do we store the data – Data lake vs datawarehouse Which tool to we use to ingest – cronjob vs workflow engine NOTE : This weeks task requires good internet speed and good compute.
Secondly , the rise of data lakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape. Read More: What is ETL?
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from datawarehouses and data lakes. What is Data Hub?
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , datawarehouses , data lakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
Companies need to analyze large volumes of datasets, leading to an increase in data producers and consumers within their IT infrastructures. These companies collect data from production applications and B2B SaaS tools (e.g., This data makes its way into a data repository, like a datawarehouse (e.g.,
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based datawarehouses have revolutionized data processing with their advanced massively parallel processing (MPP) capabilities and SQL support.
Workaround: Implement custom metadata tracking scripts or use dbt Clouds freshness monitoring. Testing Limitations: Both dbt Cloud and dbtCore dbt is designed for SQL-based transformations in datawarehouses, meaning it is not well-suited for non-SQL, real-time, or highly complex unstructured data transformations.
Big Data Processing In order to extract value or insights out of big data, one must first process it using big data processing software or frameworks, such as Hadoop. Big Query Google’s cloud datawarehouse. Data Catalog An organized inventory of data assets relying on metadata to help with data management.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structureddata, and a data lake used to host large amounts of raw data.
From the perspective of data science, all miscellaneous forms of data fall into three large groups: structured, semi-structured, and unstructured. Key differences between structured, semi-structured, and unstructured data. Note, though, that not any type of web scraping is legal.
About Schemata Schemata is a schema modeling framework for decentralized domain-driven ownership of data. Schemata combine a set of standard metadata definitions for each schema & data field and a scoring algorithm to provide a feedback loop on how efficient the data modeling of your datawarehouse is.
You can leverage AWS Glue to discover, transform, and prepare your data for analytics. In addition to databases running on AWS, Glue can automatically find structured and semi-structureddata kept in your data lake on Amazon S3, datawarehouse on Amazon Redshift, and other storage locations.
Hive- Performance Benchmarking Hive vs Pig Pig vs Hive - Differences Pig Hive Procedural Data Flow Language Declarative SQLish Language For Programming For creating reports Mainly used by Researchers and Programmers Mainly used by Data Analysts Operates on the client side of a cluster. Does not have a dedicated metadata database.
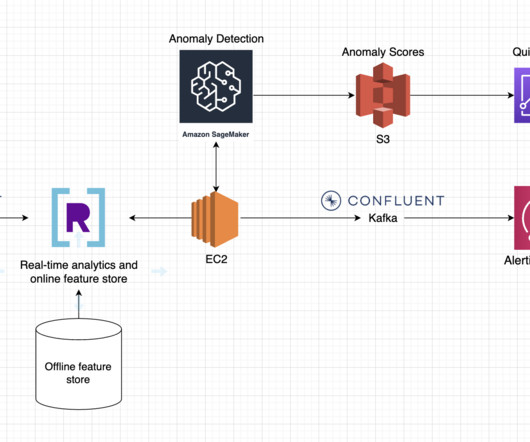
Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. This data tends to be slow changing and is stored in an offline feature store. This could be a cloud datawarehouse, a data lake, or a database. The database has two primary jobs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content