This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
In this episode Ian Schweer shares his experiences at Riot Games supporting player-focused features such as machine learning models and recommeder systems that are deployed as part of the game binary. Atlan is the metadata hub for your data ecosystem. How is everyone going to find the data they need, and understand it?
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
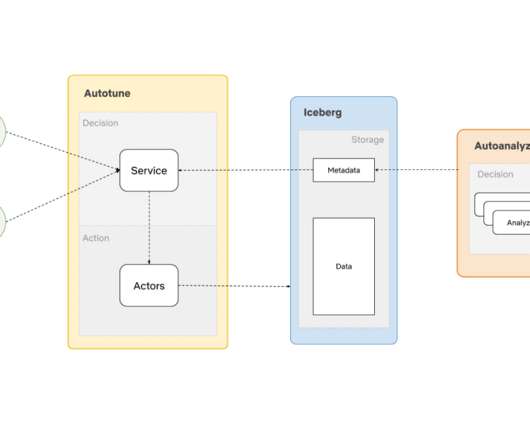
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Use cases We found several use cases where a system like AutoOptimize can bring tons of value.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Summary Building a well managed data ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
In this episode Guy Yachdav, director of software engineering for ImmunAI, shares the complexities that are inherent to managing data workflows for bioinformatics. RudderStack’s smart customer data pipeline is warehouse-first. You can observe your pipelines with built in metadata search and column level lineage.
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. In order to turn this into a tractable problem one approach is to define and enforce contracts between producers and consumers of data. Atlan is the metadata hub for your data ecosystem.
The system leverages a combination of an event-based storage model in its TimeSeries Abstraction and continuous background aggregation to calculate counts across millions of counters efficiently. link] Grab: Metasense V2 - Enhancing, improving, and productionisation of LLM-powered data governance. Boyter on Bloom Filters and SQLite.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. Accessibility : I could easily request access to these data products.
Data Silos: Breaking down barriers between data sources. Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g.,
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
Deploying, managing, and scaling that orchestration can consume a large fraction of a data team’s energy so it is important to pick something that provides the power and flexibility that you need. RudderStack’s smart customer data pipeline is warehouse-first.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
WhyLogs is a powerful library for flexibly instrumenting all of your datasystems to understand the entire lifecycle of your data from source to productionized model. You have full control over your data and their plugin system lets you integrate with all of your other data tools, including datawarehouses and SaaS platforms.
Some of the most powerful results come from combining complementary superpowers, and the “dynamic duo” of Apache Hive LLAP and Apache Impala, both included in Cloudera DataWarehouse , is further evidence of this. Both Impala and Hive can operate at an unprecedented and massive scale, with many petabytes of data.
In relation to previously existing roles , the data engineering field could be thought of as a superset of business intelligence and data warehousing that brings more elements from software engineering. The traditional best practices of data warehousing are loosing ground on a shifting stack.
The biggest challenge with modern datasystems is understanding what data you have, where it is located, and who is using it. Just connect it to your database/datawarehouse/data lakehouse/whatever you’re using and let them do the rest. Sifflet also offers a 2-week free trial.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. To avoid disruptions to operational databases, companies typically replicate data to datawarehouses for analysis.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines? Stale dashboards?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines? Stale dashboards?
Take advantage of old school databasetricks In the last 1015 years weve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, datawarehouses, and new tools (lots and lots of newtools). Each source came from a different revenue provider, and as such a different system.
This leads to systemic, stupid errors that waste hours. Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. Data engineers are many degrees removed from those who are “moving the needle”.
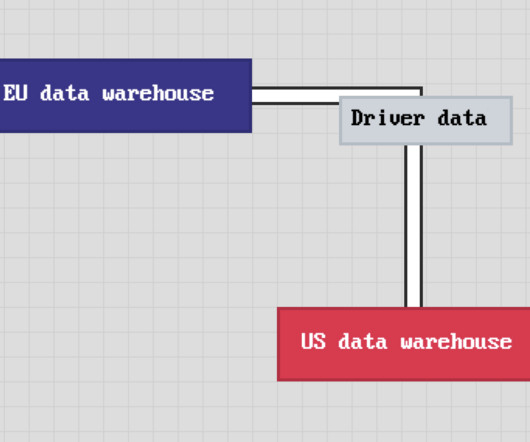
This truth was hammered home recently when ride-hailing giant Uber found itself on the receiving end of a staggering €290 million ($324 million) fine from the Dutch Data Protection Authority. Poor datawarehouse governance practices that led to the improper handling of sensitive European driver data. The reason?
Why worry about costs with cloud-native data warehousing? Have you been burned by the unexpected costs of a cloud datawarehouse? If not, before adopting a cloud datawarehouse, consider the true costs of a cloud-native datawarehouse. These costs impede the adoption of cloud-native datawarehouses.
The dataflow migration command is a special feature, developed single handedly by Stephen Huenneke , to fully automate the communication and tracking of a datawarehouse table changes. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix datawarehouse.
Summary Data analysis is a valuable exercise that is often out of reach of non-technical users as a result of the complexity of datasystems. Atlan is the metadata hub for your data ecosystem. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Cloudera has long had the capabilities of a data lakehouse, if not the label. 4-Ready for modern data fabric architectures. 4-Ready for modern data fabric architectures.
Kirk Marple has spent years working with datasystems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable. Hightouch is the easiest way to sync data into the platforms that your business teams rely on. No more scripts, just SQL.
Summary There are extensive and valuable data sets that are available outside the bounds of your organization. Whether that data is public, paid, or scraped it requires investment and upkeep to acquire and integrate it with your systems. Atlan is the metadata hub for your data ecosystem.
In order to reduce the friction involved in aggregating disparate data sets that share geographic similarities the Unfolded team built a platform that supports working across raster, vector, and tabular data in a single system. Atlan is the metadata hub for your data ecosystem.
You have full control over your data and their plugin system lets you integrate with all of your other data tools, including datawarehouses and SaaS platforms. What are the unique constraints and challenges that come into play when managing data in cloud platforms?
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Note that where a TRUNCATE PARTITION is typically a “free” metadata operation, a DELETE operation may be expensive and that should be taken into considerations. This means that ideally the logic in source control describes how to build the full state of the datawarehouse throughout all time periods.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
Summary Data lineage is the common thread that ties together all of your data pipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content