This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, that's also something we're re-thinking with our warehouse-centric strategy. How does reverse ETL factor into the enrichment process for profile data? Rudderstack]([link] RudderStack provides all your customer datapipelines in one platform. Let us know if you have opinions there!
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services.
In this episode founder Shayan Mohanty explains how he and his team are bringing software best practices and automation to the world of machine learning data preparation and how it allows data engineers to be involved in the process. Data stacks are becoming more and more complex. That’s where our friends at Ascend.io
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE) , the only cloud-native service purpose-built for enterprise data engineering teams. Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex datapipelines anywhere.
Without DataOps, companies can employ hundreds of data professionals and still struggle. The datapipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. That’s the power of DataOps automation.
But this article is not about the pricing which can be very subjective depending on the context—what is 1200$ for dev tooling when you pay them more than $150k per year, yes it's US-centric but relevant. It can be deployment in all environment or as a lot of data only in production, because only production exists.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The process hub capability of the DataKitchen Platform ensures that those processes that act upon data – the tests, the recipes – are shareable and manageable.
Data Factory, Data Activator, Power BI, Synapse Real-Time Analytics, Synapse Data Engineering, Synapse Data Science, and Synapse DataWarehouse are some of them. With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Let us now understand the basic responsibilities of a Data engineer.
In a nutshell, DataOps engineers are responsible not only for designing and building datapipelines, but iterating on them via automation and collaboration as well. So, does this mean you should choose DataOps engineering vs. data engineering when considering your next career move? What does a DataOps engineer do? It depends!
A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use.
Analytics Stacks for Startups Jan Katins, Senior IT Consultant/Data Engineer, kreuzwerker GmbH The stack should be relatively fast to implement (two weeks is possible), so you can quickly reap the benefits of having a datawarehouse and BI Tooling in place or upload enriched data back to operational systems.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. Data Ingestion Data ingestion is the first step of both ETL and datapipelines.
He compared the SQL + Jinja approach to the early PHP era… […] “If you take the dataframe-centric approach, you have much more “proper” objects, and programmatic abstractions and semantics around datasets, columns, and transformations. There are many advantages!
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
As organizations shift from the modernization of data-driven applications via Kafka towards delivering real-time insight and/or powering smart automated systems, Flink At Current, adoption of Flink was a hot topic and many of the vendors (Cloudera included) use Flink as the engine to power their stream processing offerings as well.
It aims to explain how we transformed our development practices with a data-centric approach and offers recommendations to help your teams address similar challenges in your software development lifecycle. This approach ensured comprehensive data extraction while handling various edge cases and log formats.
Engineers work with Data Scientists to help make the most of the data they collect and have deep knowledge of distributed systems and computer science. In large organizations, data engineers concentrate on analytical databases, operate datawarehouses that span multiple databases, and are responsible for developing table schemas.
Cookies unfortunately also enabled more nefarious actors to capture and share customer data that didn’t have consumers’ best interests in mind. Instead, it’s the enterprise datawarehouse /lakehouse, and enriched first-party data, not the CDP nor the CRM, that must occupy the center of our marketing analytics kingdom.
This provided a nice overview of the breadth of topics that are relevant to data engineering including datawarehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. Open question: how to seed data in a staging environment? Test system with A/A test. Be adaptable.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Assess the needs and goals of the business.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
The demand for data-related professions, including data engineering, has indeed been on the rise due to the increasing importance of data-driven decision-making in various industries. Becoming an Azure Data Engineer in this data-centric landscape is a promising career choice.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Redshift is no longer a true competitor in the warehouse space.
Learn more in our detailed guide to data lineage visualization (coming soon) Integration with Multiple Data Sources Data lineage tools are designed to integrate with a wide range of data sources, including databases, datawarehouses, and cloud-based data platforms.
The Nuances of Snowflake Costing Snowflake’s pricing strategy is an exemplification of its user-centric approach: pay for what you use. The more tables you have, the kind of SQL queries you run, and the dimensions of your datawarehouses are pivotal determinants. So Why Do Snowflake Costs Become Prohibitive?
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Pipelines for data in motion can quickly turn into DAG hell.
Tip #2: Accept that data quality is a war, not a battle — but we may be at a turning point Our data experts know that data downtime is an ancient enemy — relative to the age of the modern data stack, in any case. I think monitoring for software is a no-brainer, and I feel the same way about monitoring for data.
Microsoft Azure's Azure Synapse, formerly known as Azure SQL DataWarehouse, is a complete analytics offering. Designed to tackle the challenges of modern data management and analytics, Azure Synapse brings together the worlds of big data and data warehousing into a unified and seamlessly integrated platform.
This data can be structured, semi-structured, or entirely unstructured, making it a versatile tool for collecting information from various origins. The extracted data is then duplicated or transferred to a designated destination, often a datawarehouse optimized for Online Analytical Processing (OLAP).
On the other hand, it burdened the centralized data engineering with the impossible task of gatekeeping and onboarding an endless stream of new datasets into new and existing core tables. Furthermore, pipelines built downstream of core_data created a proliferation of duplicative and diverging metrics. Stay tuned for our next post !
Benjamin shares similar advice on LinkedIn, posting regularly about big data, data infrastructure, data science, data engineering, and data warehousing. He provides AI strategy, data product strategy, transformation, and data organizational build-out services to clients like Airbus, Siemens, Walmart, and JPMC.
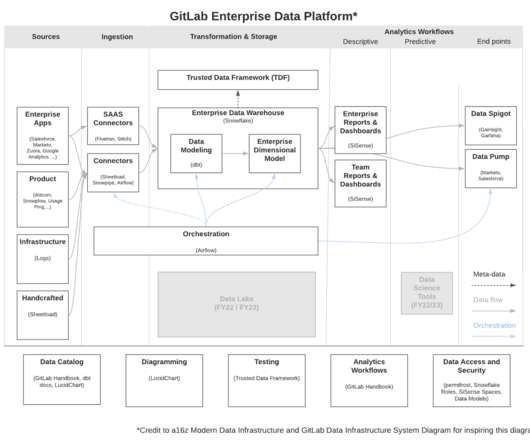
The GitLab data stack Using a cloud-based and modular data stack makes it easy for the data team to scale while serving distributed stakeholders. How does Rob know this customer-centric approach is working? He looks to the data, of course. Image courtesy of GitLab.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
So, here the argument on what to use and where to use become an important topic to be considered and here we can rather focus on some of the adaptable and sensitive models and we begin to consider the data vaults’ technique. So, what is a data vault model or modelling approach? post which is the ML model trainings.
Previously we would have a very laborious datawarehouse or data mart initiative and it may take a very long time and have a large price tag. Be business-centric. Tyo pointed out, “Don’t do data for data’s sake. There is no data strategy, it’s only a business strategy.”.
ADF connects to various data sources, including on-premises systems, cloud services, and SaaS applications. It then gathers and relocates information to a centralized hub in the cloud using the Copy Activity within datapipelines. Transform and Enhance the Data: Once centralized, data undergoes transformation and enrichment.
Key Advantages of Azure Synapse No Code AI or Analytics Capabilities Azure Synapse takes a significant leap forward in democratizing data analytics and AI by offering robust no-code options. Lakehouse Architecture Pioneer Databricks brought the best elements of data lakes and datawarehouses to create Lakehouse.
Follow Eric on LinkedIn 10) Brian Femiano Senior Data Engineer at Apple Brian is a senior data engineer with nearly two decades of experience at companies like Booz Allen Hamilton, Magnetic, Pandora, and, most recently, Apple. Previously, he was the first data team hire at WeWork, where he built the data engineering infrastructure.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content