This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
dbt Core is an open-source framework that helps you organise datawarehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
Meta joins the Data Transfer Project and has continuously led the development of shared technologies that enable users to port their data from one platform to another. 2024: Users can access data logs in Download Your Information. What are data logs?
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
Setting the Stage: We need E&L practices, because “copying rawdata” is more complex than it sounds. For instance, how would you know which orders got “canceled”, an operation that usually takes place in the same data record and just “modifies” it in place. But not at the ingestion level.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring data accessibility, accuracy, and utility. However, beneath their surface lies a host of invisible risks embedded within the datawarehouse layers.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. Databricks is focusing on simplification (serverless, auto BI 2 , improved PySpark) while evolving into a datawarehouse.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
While business rules evolve constantly, and while corrections and adjustments to the process are more the rule than the exception, it’s important to insulate compute logic changes from data changes and have control over all of the moving parts. But how do we model this in a functional datawarehouse without mutating data?
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. There are times when the data is structured , but it is often messy since it is ingested directly from the data source. What is DataWarehouse? . DataWarehouse in DBMS: .
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
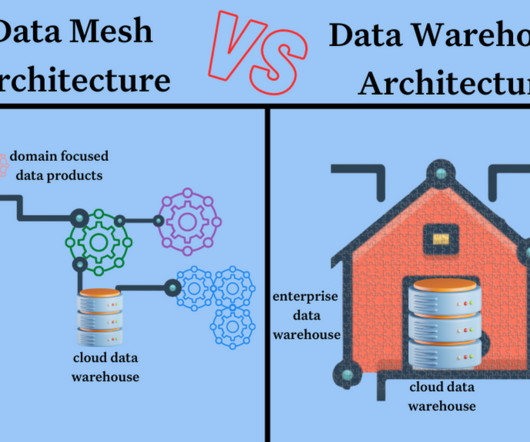
Data mesh vs datawarehouse is an interesting framing because it is not necessarily a binary choice depending on what exactly you mean by datawarehouse (more on that later). Despite their differences, however, both approaches require high-quality, reliable data in order to function. What is a Data Mesh?
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
At TCS , we help companies shift their enterprise datawarehouse (EDW) platforms to the cloud as well as offering IT services. We’re extremely familiar with just how tricky a cloud migration can be, especially when it involves moving historical business data. How many tables and views will be migrated, and how much rawdata?
Just make sure you have enough processes in place to prevent data silos! Data Lakehouse Pattern Data lakehouses are the sporks of architectural patterns – combining the best parts of datawarehouses with data lakes. The data lakehouse has got you covered!
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
Each data source is updated on its own schedule, for example, daily, weekly or monthly. The DataKitchen Platform ingests data into a data lake and runs Recipes to create a datawarehouse leveraged by users and self-service data analysts. Let’s consider how to break up our architecture into data mesh domains.
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
A lot of data teams embraced dbt, or at least the SQL with engineering practices to transform data in cloud datawarehouses. As introduction Tristan gives the original vision of dbt that became mainstream, today. In dbt Core 1.5
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
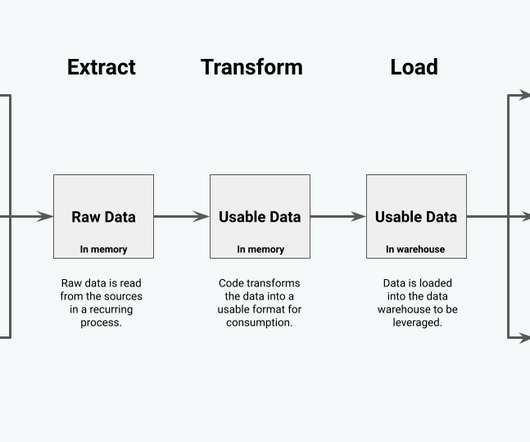
ELT comprises three main phases: Extract (E) : data is extracted from multiple sources in different formats, both structured and unstructured. Load (L) : data is loaded into a target destination, such as a datawarehouse. Extract and Load This phase includes VDK jobs calling the Europeana REST API to extract rawdata.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a datawarehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. What is Real Time Data Warehousing?
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks.
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the datawarehouse? Dataform picks up where your ETL jobs leave off, turning rawdata into reliable analytics.
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
The goal of dimensional modeling is to take rawdata and transform it into Fact and Dimension tables that represent the business. Part 7: Consume dimensional model Finally, we can consume our dimensional model by connecting to our datawarehouse to our Business Intelligence (BI) tools such as Tableau, Power BI, and Looker.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
After evaluating numerous data solution providers, Databricks stood out due to its seamless performance and lakehouse capabilities, which offer the best of both data lakes and datawarehouses. This vital information then streams to the XRPL Data Extractor App. Why Databricks Emerged as the Top Contender 1.
After the hustle and bustle of extracting data from multiple sources, you have finally loaded all your data to a single source of truth like the Snowflake datawarehouse. However, data modeling is still challenging and critical for transforming your rawdata into any analysis-ready form to get insights.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build data lakes and ingest rawdata extracted from different sources, including structured, semi-structured, and unstructured data.
The mission of many data teams is a very simple one. They seek to use data to help the business take smarter actions. The input is rawdata from everywhere that touches the business. How can we best get the data into a usable form? The end goal of both is to have data in a datawarehouse ready to be leveraged.
Meet Airbyte, the data magician that turns integration complexities into child’s play. In this digital era, businesses thrive on data, and making this data dance harmoniously with your analytics tools is crucial. Airbyte ensures that you don’t miss out on those insights due to tangled data integration processes.
ELT: When to Transform Your Data ETL (Extract, Transform, Load) ELT (Extract, Load, Transform) Which One Should You Choose? Batch vs. Stream Processing: How to Move Your Data Batch Processing Stream Processing Which One Should You Choose? Data Lakes vs. DataWarehouses: Where Should Your Data Live?
ETL, or Extract, Transform, Load, is a process that involves extracting data from different data sources , transforming it into more suitable formats for processing and analytics, and loading it into the target system, usually a datawarehouse. ETL data pipelines can be built using a variety of approaches.
Back to Data in the 21st Century Thinking back at my own experiences, the philosophy of most big data engineering projects I’ve worked on was similar to that of Multics. For example, there was a project where we needed to automate standardising the rawdata coming in from all our clients. That was it.
The data extraction process The first step of modeling and using data begins with extracting it from different sources and putting it in a library where it can be assessed: the DataWarehouse. In some cases, rawdata is extracted and placed in the staging area; in others, a few transformations need to be performed.
As data volumes continue to grow, organizations seek ways to make sense of it all, and datawarehouses are at the center. BigQuery is a popular cloud-based datawarehouse that allows for powerful analytics and querying at scale. This is […]
Data Store Another significant change from 2021 to 2024 lies in the shift from “DataWarehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of Data Lakes. Their robust core offering seamlessly integrates datawarehouses with data-hungry applications.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content