This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with 3) Spark 4.0
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix datawarehouse.
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Datafold also helps automate regression testing of ETL code with its Data Diff feature that instantly shows how a change in ETL or BI code affects the produced data, both on a statistical level and down to individual rows and values. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. The result is that streaming data tends to be “locked away” from everyone but a small few, and the data engineering team is highly overworked and backlogged. A rare breed.
Summary With the constant evolution of technology for data management it can seem impossible to make an informed decision about whether to build a datawarehouse, or a data lake, or just leave your data wherever it currently rests. How does it influence the relevancy of datawarehouses or data lakes?
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer data pipeline is warehouse-first.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Contrast this with the skills honed over decades for gaining access, building datawarehouses, performing ETL, creating reports and/or applications using structured query language (SQL). Benefits of Streaming Data for Business Owners. A rare breed. What does all this mean for those in business leadership roles? .
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
The past decades of enterprise data platform architectures can be summarized in 69 words. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Data professionals are not perfectly interchangeable.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads? Hightouch is the easiest way to sync data into the platforms that your business teams rely on. The data you’re looking for is already in your datawarehouse and BI tools. No more scripts, just SQL.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
In order to quickly identify if and how two data systems are out of sync Gleb Mezhanskiy and Simon Eskildsen partnered to create the open source data-diff utility. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Summary The "data lakehouse" architecture balances the scalability and flexibility of data lakes with the ease of use and transaction support of datawarehouses. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Summary The optimal format for storage and retrieval of data is dependent on how it is going to be used. For analytical systems there are decades of investment in datawarehouses and various modeling techniques. For analytical systems there are decades of investment in datawarehouses and various modeling techniques.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
Spark provides an interactive shell that can be used for ad-hoc data analysis, as well as APIs for programming in Java, Python, and Scala. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data. The two most popular datawarehouse systems are Teradata and Oracle Exadata.
Select Star’s data discovery platform solves that out of the box, with an automated catalog that includes lineage from where the data originated, all the way to which dashboards rely on it and who is viewing them every day. Go to dataengineeringpodcast.com/ascend and sign up for a free trial.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a datawarehouse, a centralized repository for structured data, and a data lake used to host large amounts of raw data.
The DataWarehouse Toolkit (Kimball & Ross) The DataWarehouse Toolkit, 3rd Edition - Kimball Group I’m not going to bury the lead. If you work in data, you at the very least need to be familiar with dimensional modeling concepts, and I personally don’t think there’s a better way than by going straight to the source.
In order to filter out information from the system, it analyzes data from other users and their interactions with the system. What are some of the most popular tools used in big data? Hadoop Scala Spark Flume Define N-gram. The database is optimized so that data can be retrieved more quickly.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a data storage (typically, a datawarehouse ), where it’s kept.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
During this transformation, Airbnb experienced the typical growth challenges that most companies do, including those that affect the datawarehouse. This post explores the data challenges Airbnb faced during hyper growth and the steps we took to overcome these challenges. This is discussed below.
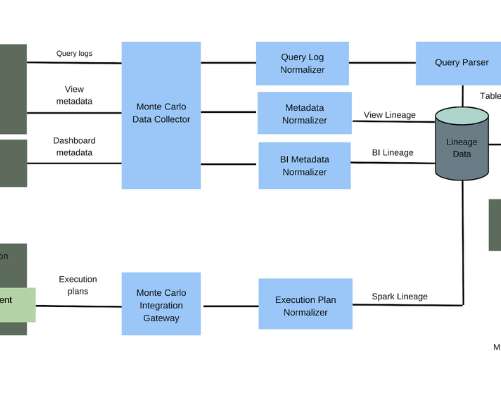
Metadata from the datawarehouse/lake and from the BI tool of record can then be used to map the dependencies between the tables and dashboards. It also becomes outdated virtually the moment it’s mapped as your environment continues to ingest more data and you continue to layer on additional solutions. option('header', 'true').option('inferSchema',
Programming and Scripting Skills Building data processing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java. Database Knowledge Data warehousing ideas like the star and snowflake schema, as well as how to design and develop a datawarehouse, should be well understood by you.
ETL, or Extract, Transform, Load, is a process that involves extracting data from different data sources , transforming it into more suitable formats for processing and analytics, and loading it into the target system, usually a datawarehouse. ETL data pipelines can be built using a variety of approaches.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your data management to the next level. ETL has typically been carried out utilizing datawarehouses and on-premise ETL tools.
Python is ubiquitous, which you can use in the backends, streamline data processing, learn how to build effective data architectures, and maintain large data systems. Java can be used to build APIs and move them to destinations in the appropriate logistics of data landscapes.
Data engineers add meaning to the data for companies, be it by designing infrastructure or developing algorithms. The practice requires them to use a mix of various programming languages, datawarehouses, and tools. While they go about it - enter big datadata engineer tools.
Because DE is fully integrated with the Cloudera Shared Data Experience (SDX), every stakeholder across your business gains end-to-end operational visibility, with comprehensive security and governance throughout. For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , datawarehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, data lakes, and datawarehouses. ETL activities are also the responsibility of data engineers.
These are the world of data and the datawarehouse that is focused on using structured data to answer questions about the past and the world of AI that needs more unstructured data to train models to predict the future. Databricks Workflows reached 100m weekly jobs and are processing 2 excabytes of data per day.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content