This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud datawarehouse to Snowflake and some of the benefits they saw.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. As part of this announcement, Snowflake is also announcing private preview support of a new end-to-end data migration experience for Amazon Redshift.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. As part of this announcement, Snowflake is also announcing private preview support of a new end-to-end data migration experience for Amazon Redshift.
So, we are […] The post How to Normalize Relational Databases With SQL Code? If a corrupted, unorganized, or redundant database is used, the results of the analysis may become inconsistent and highly misleading. appeared first on Analytics Vidhya.
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera DataWarehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? Today, we are pleased to announce the general availability of HPL/SQL integration in CDW public cloud.
This results in the generation of so much data daily. This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases.
dbt Core is an open-source framework that helps you organise datawarehouseSQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQL Databases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake.
These stages propagate through various systems including function-based systems that load, process, and propagate data through stacks of function calls in different programming languages (e.g., For simplicity, we will demonstrate these for the web, the datawarehouse, and AI, per the diagram below. Hack, C++, Python, etc.)
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable.
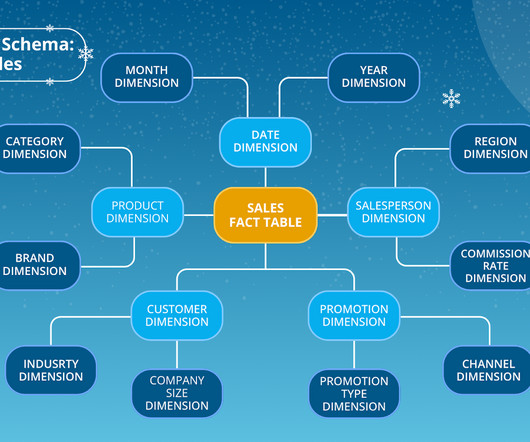
Think of your datawarehouse like a well-organized library. Thats where datawarehouse schemas come in. A datawarehouse schema is a blueprint for how your data is structured and linkedusually with fact tables (for measurable data) and dimension tables (for descriptive attributes).
Introduction Setup Code Conditional logic to read from mock input Custom macro to test for equality Setup environment specific test Run ELT using dbt Conclusion Further reading Introduction With the recent advancements in datawarehouses and tools like dbt most transformations(T of ELT) are being done directly in the datawarehouse.
You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines. You can Implement RudderStack SDKs once, then automatically send events to your warehouse and 150+ business tools, and you’ll never have to worry about API changes again.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
He listed 4 things that are the most difficult data integration tasks: from mutable data to IT migrations, everything adds complexity to ingestion systems. The software development lifecycle within a modern data engineering framework — A great deep-dive about a data platform using dltHub, dbt and Dagster.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Data lakes are notoriously complex. Data lakes are notoriously complex. Your first 30 days are free! Your first 30 days are free!
Contrast that with the skills honed over decades for gaining access, building datawarehouses, performing ETL, creating reports and/or applications using structured query language (SQL). The declarative nature of the SQL language makes it a powerful paradigm for getting data to the people who need it.
It runs locally, has extensive SQL support and can run queries directly on Pandas data, Parquet, JSON data. The fact it’s insanely fast and does (mostly) all processing in memory make it a good choice for building my personal datawarehouse. Extra points for its seamless integration with Python and R.
With yato you give a folder with SQL queries and it guesses the DAG and runs the queries in the right order. BigQuery supports DELETE to delete partitions in a SQL query. Arrow doing a lot of the data operation heavy lifting. Give a lot of insights on the market. this is more common sense but always works.
In this episode Emily Riederer shares her work to create a controlled vocabulary for managing the semantic elements of the data managed by her team and encoding it in the schema definitions in her datawarehouse. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. No more shipping and praying, you can now know exactly what will change in your database!
He also explains why he started Decodable to address that limitation and the work that he and his team have done to let data engineers build streaming pipelines entirely in SQL. Start trusting your data with Monte Carlo today! Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. you could write the same pipeline in Java, in Scala, in Python, in SQL, etc.—with 3) Spark 4.0
Oracle is a well-known technology for hosting Enterprise DataWarehouse solutions. However, many customers like Optum and the U.S. Citizenship and Immigration Services.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Try Cloudera DataWarehouse (CDW) by signing up for a 60 day trial , or test drive CDP.
Take advantage of old school databasetricks In the last 1015 years weve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, datawarehouses, and new tools (lots and lots of newtools). Created by the author using SQL-WatchPup Thats it. No server hosting costs.
Many data engineers and analysts don’t realize how valuable the knowledge they have is. They’ve spent hours upon hours learning SQL, Python, how to properly analyze data, build datawarehouses, and understand the differences between eight different ETL solutions.
Materialize’s PostgreSQL-compatible interface lets users leverage the tools they already use, with unsurpassed simplicity enabled by full ANSI SQL support. Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses.
link] Jon Osborn: Best Practices for Using QUERY_TAG in Snowflake The modern datawarehouses are good at running at scale, given the cost is not a constraint. link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure.
Summary Cloud datawarehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a datawarehouse. Batch data integration is useful for data that isn’t extremely time-sensitive. Electric bills are a relevant example.
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
As described in our recent blog post , an SQL AI Assistant has been integrated into Hue with the capability to leverage the power of large language models (LLMs) for a number of SQL tasks. This is a real game-changer for data analysts on all levels and will make SQL development faster, easier, and less error-prone.
In this episode Ori Rafael explains how they are automating the creation and scheduling of orchestration flows and their related transforations in a unified SQL interface. Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Missing data?
A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
Photo by Tiger Lily Datawarehouses and data lakes play a crucial role for many businesses. It gives businesses access to the data from all of their various systems. As well as often integrating data so that end-users can answer business critical questions.
How to reduce warehouse costs? — Hugo propose 7 hacks to optimise datawarehouse cost. Dimensional data modeling with dbt — A great 6-steps process to create a simple dim-fact model with dbt. teej/titan — Titan is a Python library to manage datawarehouse infrastructure. Crazy amounts.
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL.
Datafold built automated regression testing to help data and analytics engineers deal with data quality in their pull requests. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Pricing for SQLake is simple.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content