This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to Data Lake vs. DataWarehouse appeared first on Analytics Vidhya.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structureddata management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Summary Datawarehouses have gone through many transformations, from standard relational databases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen.
Summary Datawarehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform.
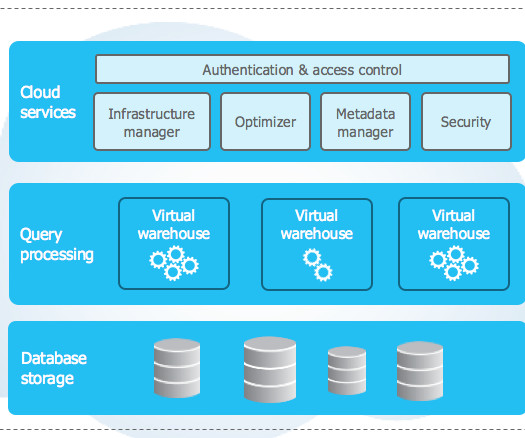
A datawarehouse is a centralized system that stores, integrates, and analyzes large volumes of structureddata from various sources. It is predicted that more than 200 zettabytes of data will be stored in the global cloud by 2025.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. Fabric is meant for organizations looking for a single pane of glass across their data estate with seamless integration and a low learning curve for Microsoft users. Next, we will see what Snowflake is What is Snowflake?
Snowflake DataWarehouse delivers essential infrastructure for handling a Data Lake, and DataWarehouse needs. It can store semi-structured and structureddata in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages. Data warehousing offers several advantages.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataWarehouse? .
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
Proficiency in Programming Languages Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike. In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
How could Matthew serve all this data, together , in an easily consumable way, without losing focus on his core business: finding a cure for cancer. The Vision of a Discovery DataWarehouse. A Discovery DataWarehouse is cloud-agnostic. Access to valuable data should not be hindered by the technology.
Summary Designing the structure for your datawarehouse is a complex and challenging process. As businesses deal with a growing number of sources and types of information that they need to integrate, they need a data modeling strategy that provides them with flexibility and speed.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
Evolution of the data landscape 1980s — Inception Relational databases came into existence. Result: Datawarehouse was born. Data volumes started to grow. Result: The concept of Massively Parallel Processing (MPP) was introduced — data distributed across clusters. The concept of `Data Marts` was introduced.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically datawarehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
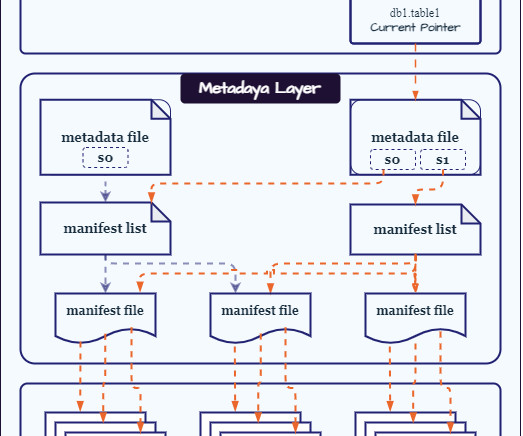
Major datawarehouse providers (Snowflake, Databricks) have released their flavors of REST catalogs, leading to compatibility issues and potential vendor lock-in. Start the Data Governance Process: Don't wait until the last minute to build the data governance framework.
As data volumes increase, fetching insights from this data comes with its challenges. Sure, you can use lakes and marts to dump any data, but ultimately, deriving business insights requires structureddata with a faster querying experience. This raises the need for […]
Data Lakehouse Pattern Data lakehouses are the sporks of architectural patterns – combining the best parts of datawarehouses with data lakes. You get the structure and performance of a warehouse with the flexibility and scalability of a lake. The data lakehouse has got you covered!
[link] Meta: Data logs - The latest evolution in Meta’s access tools Meta writes about its access tool's system design, which helps export individual users’ access logs. link] GetInData: Data Quality in Streaming: A Deep Dive into Apache Flink Data Quality in a real-time streaming system is always challenging.
Prior to data powering valuable data products like machine learning models and real-time marketing applications, datawarehouses were mainly used to create charts in binders that sat off to the side of board meetings. The most common themes: Data readiness- You cant have good AI with bad data.
Morgan Stanley Data Engineer Interview Questions As a data engineer at Morgan Stanley, you will be responsible for creating and maintaining the infrastructure for their datawarehouse. Analyzing this data often involves Machine Learning, a part of Data Science. What is a datawarehouse?
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Data storage and compute are very much the foundation of your data platform. Let’s jump in! So, let’s take a look at each in a bit more detail.
Structured and Unstructured Data: A Treasure Trove of Insights Enterprise data encompasses a wide array of types, falling mainly into two categories: structured and unstructured. Structureddata is highly organized and formatted in a way that makes it easily searchable in databases and datawarehouses.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value. Enter Snowpark !
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
Before going into further details on Delta Lake, we need to remember the concept of Data Lake, so let’s travel through some history. The main player in the context of the first data lakes was Hadoop, a distributed file system, with MapReduce, a processing paradigm built over the idea of minimal data movement and high parallelism.
A data lake is a central storage place for an organization’s data in its original format. Unlike datawarehouses, data lakes can handle all kinds of data, including unstructured and semi-structureddata like images, video, audio, and documents.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as datawarehouses to multi-format data stores like data lakes.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content