This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
source: svitla.com Introduction Before jumping to the datawarehouse interview questions, let’s first understand the overview of a datawarehouse. The data is then organized and structured […] The post DataWarehouse Interview Questions appeared first on Analytics Vidhya.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud datawarehouse to Snowflake and some of the benefits they saw.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. Snowflake and many of its system integrator (SI) partners have leveraged SnowConvert to accelerate hundreds of migration projects.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. Snowflake and many of its system integrator (SI) partners have leveraged SnowConvert to accelerate hundreds of migration projects.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
But data volumes grow, analytical demands become more complex, and Postgres stops being enough. Therefore, you’ve probably come across terms like OLAP (Online Analytical Processing) systems, datawarehouses, and, more recently, real-time analytical databases.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Did you know Cloudera customers, such as SMG and Geisinger , offloaded their legacy DW environment to Cloudera DataWarehouse (CDW) to take advantage of CDW’s modern architecture and best-in-class performance? The DataWarehouse on Cloudera Data Platform provides easy to use self-service and advanced analytics use cases at scale.
AI Product Day on March 31 ( register ) AI News 🤖 The current economic uncertainties are affecting the tech and data worlds. AI companies are aiming for the moon—AGI—promising it will arrive once OpenAI develops a system capable of generating at least $100 billion in profits.
Intro A very common use case in data engineering is to build a ETL system for a datawarehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)
Twenty years ago, the datawarehouses of choice were Oracle and Teradata. Since then, growth and innovation has shifted to the cloud, and a new generation of datasystems have […].
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Many data engineers coming from traditional batch processing frameworks have questions about real time data processing systems, like “What kind of data model did you implement, for real-time processing?”
Recognizing this shortcoming and the capabilities that could be unlocked by a robust solution Rishabh Poddar helped to create Opaque Systems as an outgrowth of his PhD studies. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production.
A datawarehouse is a centralized system that stores, integrates, and analyzes large volumes of structured data from various sources. It is predicted that more than 200 zettabytes of data will be stored in the global cloud by 2025.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems?
In this episode Guy Yachdav, director of software engineering for ImmunAI, shares the complexities that are inherent to managing data workflows for bioinformatics. RudderStack’s smart customer data pipeline is warehouse-first. RudderStack’s smart customer data pipeline is warehouse-first.
In this episode Ian Schweer shares his experiences at Riot Games supporting player-focused features such as machine learning models and recommeder systems that are deployed as part of the game binary. The biggest challenge with modern datasystems is understanding what data you have, where it is located, and who is using it.
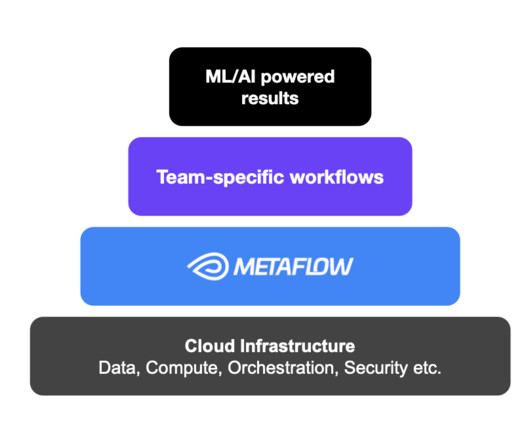
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Photo by Tiger Lily Datawarehouses and data lakes play a crucial role for many businesses. It gives businesses access to the data from all of their various systems. As well as often integrating data so that end-users can answer business critical questions.
In a recent customer workshop with a large retail data science media company, one of the attendees, an engineering leader, made the following observation: “Everytime I go to your competitor website, they only care about their system. How to onboard data into their system? I don’t care about their system.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
These products and services generate petabytes of data based on every transaction and decision, says Prakash Jaganathan, Senior Director of Data and Analytics Engineering at Discover. While working together, they bonded over their shared passion for data.
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Try Cloudera DataWarehouse (CDW) by signing up for a 60 day trial , or test drive CDP.
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. In order to turn this into a tractable problem one approach is to define and enforce contracts between producers and consumers of data. Can you describe what Schemata is and the story behind it?
Managing and understanding large-scale data ecosystems is a significant challenge for many organizations, requiring innovative solutions to efficiently safeguard user data. Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale.
WhyLogs is a powerful library for flexibly instrumenting all of your datasystems to understand the entire lifecycle of your data from source to productionized model. You have full control over your data and their plugin system lets you integrate with all of your other data tools, including datawarehouses and SaaS platforms.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. Accessibility : I could easily request access to these data products.
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of DataWarehouses, Data Lakes, and Lake Houses … the merging of the old relational database functionality with TB and PB level cloud-based file storage systems.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
Once again, I want to thank the Data Heros community. Last Friday, we discussed the challenges in bulk discovery and anonymization processes in datawarehouses. The collective design choices and ideas lead to a comprehensive overview of thinking about designing data infrastructure with a privacy-first approach.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as datawarehouses to multi-format data stores like data lakes. This makes gathering information for decision making a challenge.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
This is not surprising when you consider all the benefits, such as reducing complexity [and] costs and enabling zero-copy data access (ideal for centralizing data governance).
Getting data out of source systems and into a datawarehouse or data lake is one of the first steps in making it usable by analysts and data scientists. The question is how will your team do that?
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
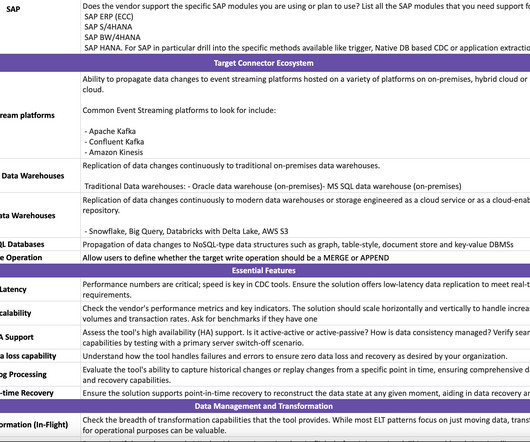
CDC Evaluation Guide Google Sheet Link: [link] CDC Evaluation Guide Github Link: [link] Change Data Capture (CDC) is a powerful technology in data engineering that allows for continuously capturing changes (inserts, updates, and deletes) made to source systems.
This means that ideally the logic in source control describes how to build the full state of the datawarehouse throughout all time periods. But how do we model this in a functional datawarehouse without mutating data? With dimension snapshots where a new partition is appended at each ETL schedule.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Cloudera has long had the capabilities of a data lakehouse, if not the label. Cloudera has been recognized in this cloud DBMS report since its inception in 2020.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content