This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
[link] Netflix: Netflix’s Distributed Counter Abstraction Netflix writes about scalable Distributed Counter abstractions for accurately counting events across its global services with millisecond latency. Due to the platform's diverse user base and workloads, Canva faced challenges maintaining visibility into Snowflake usage and costs.
The challenges around memory, data size, and runtime are exciting to read. Sampling is an obvious strategy for data size, but the layered approach and dynamic inclusion of dependencies are some key techniques I learned with the case study. Passes include app-brain-date networking, birds of a feature, post-event parties, etc.
These tools can be called by LLM systems to learn about your data and metadata. Remember, as with any AI workflows, to make sure that you are taking appropriate caution in terms of giving these access to production systems and data. For AI agent workflows : Autonomously run dbt processes in response to events.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. Data As Code is a very strong choice : we do not want any UI because it is an heritage of the ETL period. ” He/She is managing triggers, he/she needs to check conditions (event type ?
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. What is the level of native support/compatibiliity that you see for JSON-LD in data systems?
Developing event-driven pipelines is going to be a lot easier - Meet Functions! Data lakes are notoriously complex. Memphis Logo]([link] Developing event-driven pipelines is going to be a lot easier - Meet Functions! Developing event-driven pipelines is going to be a lot easier - Meet Functions!
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
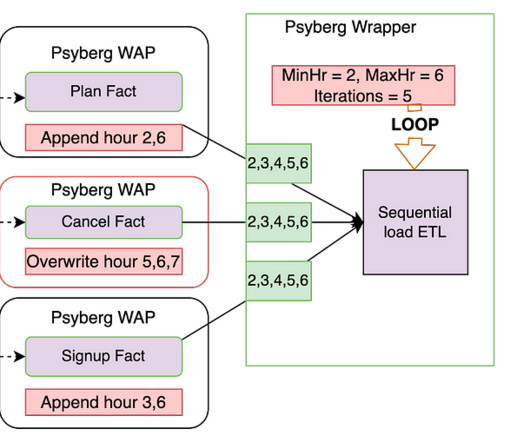
Psyberg Initialization The workflow starts with the Psyberg initialization (init) step. Input : List of source tables and required processing mode Output : Psyberg identifies new events that have occurred since the last high watermark (HWM) and records them in the session metadata table.
Finding the data that you need is tricky, and Amundsen will help you solve that problem. And as your data grows in volume and complexity, there are foundational principles that you can follow to keep dataworkflows streamlined. Finding the data that you need is tricky, and Amundsen will help you solve that problem.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. You can observe your pipelines with built in metadata search and column level lineage.
It builds your customer data warehouse and your identity graph on your data warehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. Their SDKs and plugins make event streaming easy, and their integrations with cloud applications like Salesforce and ZenDesk help you go beyond event streaming.
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps.
Moreover, it facilitates the implementation of microservices architectures and event-driven systems, automating reactions to data changes without manual intervention. In real-time data streaming and event-driven architectures, CDC captures data changes to trigger actions or workflows.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Among solutions facilitation data management are. Apache Hadoop ecosystem.
It uses the dbt Cloud Metadata API to surface metadata from dbt right in Hex, letting you quickly get the context you need on things like data freshness without juggling multiple apps and browser tabs. Modeling behavioral data with Snowplow and dbt (coming up on 10/27). Hex just launched an integration with dbt!
For example, if a credit card was used in the United States and shortly afterward the same card was used in Spain to withdraw the same amount, these two events in isolation could appear legitimate. However, in the context of time and geography, these two events point to a pattern of fraud.
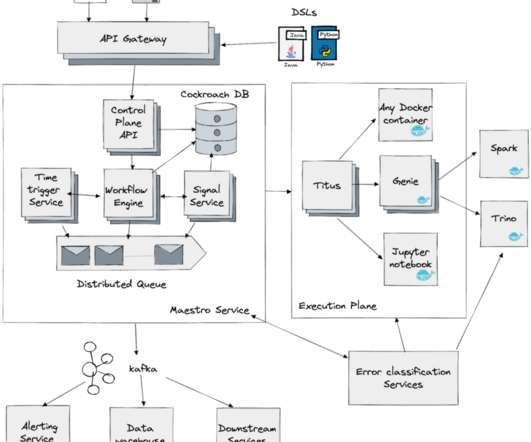
With the high growth of workflows in the past few years?—?increasing increasing at > 100% a year, the need for a scalable dataworkflow orchestrator has become paramount for Netflix’s business needs. A workflow instance is an execution of a workflow, similarly, an execution of a step is called a step instance.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The author walked through various strategies, from sync to async job submission and batch job submission strategy.
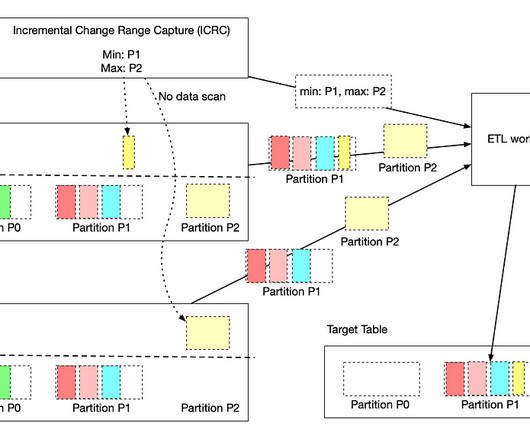
This enables auto propagation of backfill data in multi-stage pipelines. Netflix Maestro Maestro is the Netflix dataworkflow orchestration platform built to meet the current and future needs of Netflix. As we know, an iceberg table contains a list of snapshots with a set of metadatadata.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. This contrasts with data pipeline orchestration , which adopts a narrower focus, centering on the construction, operation, and management of data pipelines.
Disadvantages of a data lake are: Can easily become a data swamp data has no versioning Same data with incompatible schemas is a problem without versioning Has no metadata associated It is difficult to join the dataData warehouse stores processed data, mostly structured data.
Here’s how Gartner officially defines the category of data observability tools: “Data observability tools are software applications that enable organizations to understand the state and health of their data, data pipelines, data landscapes, data infrastructures, and the financial operational cost of the data across distributed environments.
Moreover, over 20 percent of surveyed companies were found to be utilizing 1,000 or more data sources to provide data to analytics systems. These sources commonly include databases, SaaS products, and event streams. Databases store key information that powers a company’s product, such as user data and product data.
You can extract data efficiently and once gathered, you can transform this data using built-in or custom transformations, and then load it into your desired destination. The orchestration capabilities take the chore out of large-scale data operation management across your entire organization.
Here’s how Prefect , Series B startup and creator of the popular data orchestration tool, harnessed the power of data observability to preserve headcount, improve data quality and reduce time to detection and resolution for data incidents. But Monte Carlo doesn’t stop at the “most important” tables.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. Analysis of logs, metrics, and security events. Real-time behavior modeling with ML.
Airbyte – An open source platform that easily allows you to sync data from applications. Data streaming ingestion solutions include: Apache Kafka – Confluent is the vendor that supports Kafka, the open source event streaming platform to handle streaming analytics and data ingestion.
DevOps tasks — for example, creating scheduled backups and restoring data from them. Airflow is especially useful for orchestrating Big Dataworkflows. Airflow is not a data processing tool by itself but rather an instrument to manage multiple components of data processing. Metadata database. Since the 2.0
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content