This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Open Source Data Pipeline Tools Open-source data pipeline tools are pivotal in data engineering, offering organizations flexible and scalable solutions for managing the end-to-end dataworkflow. Pros of GoogleCloud Dataflow Seamlessly processes both stream and batch data.
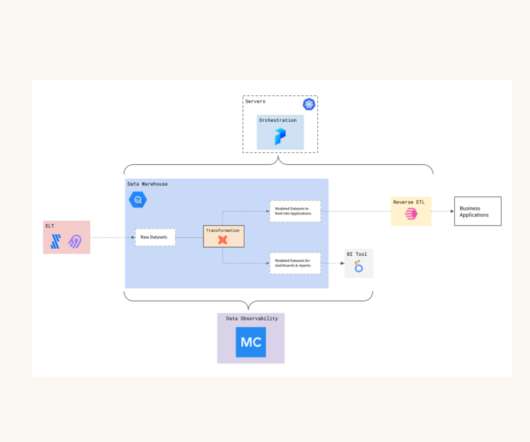
Data lakes are notoriously complex. For data engineers who battle to build and scale high quality dataworkflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
These businesses need data engineers who can use technologies for handling data quickly and effectively since they have to manage potentially profitable real-time data. Companies use cloud platforms like GoogleCloud Platform (GCP) to fulfill their objectives and satisfy their customers.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. This project builds a comprehensive ETL and analytics pipeline, from ingestion to visualization, using GoogleCloud Platform.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How can we interoperate between the data domains ? How do we govern all these data products and domains ? It will be illustrated with our technical choices and the services we are using in the GoogleCloud Platform.
It provides real multi-cloud flexibility in its operations on AWS , Azure, and GoogleCloud. Its multi-cluster shared data architecture is one of its primary features. Since all of Fabric’s tools run natively on OneLake, real-time performance without data duplication is possible in Direct Lake mode.
As more and more business apps move to the cloud, data engineering services should also change to take advantage of the benefits that come with using cloud-native tools and services. Solutions like AWS Glue , GoogleCloud Dataflow, and Azure Data Factory help businesses organize, integrate, and analyze data well.
Companies need ETL engineers to ensure data is extracted, transformed, and loaded efficiently, enabling accurate insights and decision-making. Source: LinkedIn The rise of cloud computing has further accelerated the need for cloud-native ETL tools , such as AWS Glue , Azure Data Factory , and GoogleCloud Dataflow.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
Shipyard]([link] Shipyard is an orchestration platform that helps data teams build out solid data operations from the get-go by connecting data tools and streamlining dataworkflows.
Source- Building A Serverless Pipeline using AWS CDK and Lambda ETL Data Integration From GCP Cloud Storage Bucket To BigQuery This data integration project will take you on an exciting journey, focusing on extracting, transforming, and loading raw data stored in a GoogleCloud Storage (GCS) bucket into BigQuery using Cloud Functions.
Apache Beam Apache Beam is an open-source data processing framework that allows you to build batch and stream data processing pipelines. It supports multiple execution engines, including Apache Flink and GoogleCloud Dataflow, and provides a Python SDK for ETL development.
This storage layer is the backbone of the Fabric ecosystem, offering a unified location to store all organizational data while seamlessly integrating with various Microsoft platforms, Amazon S3, and potentially GoogleCloud Platform.
Machine Learning engineers are often required to collaborate with data engineers to build dataworkflows. As a Google research scientist, one must work on cutting-edge machine intelligence and machine learning systems and generate solutions for real-world, large-scale challenges.
This blog explores the world of open source data orchestration tools, highlighting their importance in managing and automating complex dataworkflows. From Apache Airflow to GoogleCloud Composer, we’ll walk you through ten powerful tools to streamline your data processes, enhance efficiency, and scale your growing needs.
A data science pipeline represents a systematic approach to collecting, processing, analyzing, and visualizing data for informed decision-making. Data science pipelines are essential for streamlining dataworkflows, efficiently handling large volumes of data, and extracting valuable insights promptly.
Experience with Cloud Platforms and Tools Cloud platforms like AWS , GoogleCloud, and Azure offer robust environments for deploying and scaling ML models. Understanding cloud services such as AWS SageMaker, Google AI Platform, or Azure Machine Learning can significantly enhance your ability to manage ML workflows.
Piperr.io — Pre-built data pipelines across enterprise stakeholders, from IT to analytics, tech, data science and LoBs. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs dataworkflows. Genie — Distributed big data orchestration service by Netflix. Azure DevOps.
This makes Python a natural fit for ETL workflows across both fast-moving startups and large-scale enterprise data teams. Here’s why building ETL pipelines with Python is a no-brainer - Python makes it easy to write and maintain complex ETL dataworkflows.
This growth is due to the increasing adoption of cloud-based data integration solutions such as Azure Data Factory. If you have heard about cloud computing , you would have heard about Microsoft Azure as one of the leading cloud service providers in the world, along with AWS and GoogleCloud.
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale data processing, storage, and movement. They make dataworkflows more resilient and easier to manage when things inevitably go sideways. Common solutions include AWS S3 , Azure Data Lake , and GoogleCloud Storage.
By harnessing the power of Ascend and Snowflake, data teams can now ingest any data from any location, and in just minutes begin releasing entirely new data products. “We’re here to help our customers focus on the data transformation that produces real value, not just busywork.
Let’s take a look at 11 other data orchestration tools challenging Airflow’s seat at the table. But even as the modern data stack continues to evolve, Airflow maintains its title as a perennial data orchestration favorite—and for good reason. First things first—what’s Airflow?
This integration ensures that data governance is cohesive and consistent across all aspects of the dataworkflow. Unity Catalog vs. Other Data Catalog Tools: A Simple Comparison 1. Integration: Unity Catalog works easily with Databricks and ideal for those using Databricks for data & AI.
Disadvantages of a data lake are: Can easily become a data swamp data has no versioning Same data with incompatible schemas is a problem without versioning Has no metadata associated It is difficult to join the dataData warehouse stores processed data, mostly structured data.
Here’s how Prefect , Series B startup and creator of the popular data orchestration tool, harnessed the power of data observability to preserve headcount, improve data quality and reduce time to detection and resolution for data incidents. This left Dylan’s team with a gap to fill.
Apache Spark – Labeled as a unified analytics engine for large scale data processing, many leverage this open source solution for streaming use cases, often in conjunction with Databricks. Data orchestration Airflow : Airflow is the most common data orchestrator used by data teams.
Machine Learning engineers are often required to collaborate with data engineers to build dataworkflows. As a Google research scientist, one must work on cutting-edge machine intelligence and machine learning systems and generate solutions for real-world, large-scale challenges.
Strong understanding of cloud computing principles, data warehousing concepts, and best practices. If you’re on the lookout for Azure data engineer job options, you are pacing in the right direction.
In his current role as Senior Director of Product Management at Google, he focuses on BigQuery, Cloud Dataflow, Cloud DataProc, Cloud DataPrep, Cloud PubSub, and Cloud Composer.
Accessible via a unified API, these new features enhance search relevance and are available on Elastic Cloud. The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization.
This is a config driven tool that is made by HashiCorp and is supported by over 1000+ providers such as: AWS Azure GoogleCloud Oracle Alibaba Okta Kubernetes As you can see, there’s support for all the major cloud providers and various other auxiliary tooling that enterprises frequently leverage.
Airflow enables organizations to orchestrate and automate complex dataworkflows, making it a crucial tool for building data pipelines in data engineering and data science projects. Learning this powerful tool is a journey that can open doors to efficient dataworkflows and orchestration.
DevOps tasks — for example, creating scheduled backups and restoring data from them. Airflow is especially useful for orchestrating Big Dataworkflows. Airflow is not a data processing tool by itself but rather an instrument to manage multiple components of data processing. When Airflow won’t work.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content