This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. What are its limitations and how do the Hadoop ecosystem address them? What is Hadoop.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
Data lakes are notoriously complex. For data engineers who battle to build and scale high quality dataworkflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
With widespread enterprise adoption, learning Hadoop is gaining traction as it can lead to lucrative career opportunities. There are several hurdles and pitfalls students and professionals come across while learning Hadoop. How much Java is required to learn Hadoop? How much Java is required to learn Hadoop?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
How do the current set of tools contribute to the fragmentation of dataworkflows? What advice do you have for data engineers to help with addressing complexity in the data organization and the problems that it contributes to? How do the current set of tools contribute to the fragmentation of dataworkflows?
One of the ways to reason about progress in any domain is to look at what was the primary bottleneck of further progress (data adoption for decision making) at different points in time. Over the past couple of months, we’ve seen the resurgence of “benchmark wars” between major data warehousing platforms.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, dataworkflows, data pipelines, and the ETL (Extract, Transform, Load) process. Hadoop Platform Hadoop is an open-source software library created by the Apache Software Foundation.
LTIMindtree’s PolarSled Accelerator helps migrate existing legacy systems, such as SAP, Teradata and Hadoop, to Snowflake. Additional processing capability with SQL, as well as Snowflake capabilities like Stored Procedures, Snowpark , and Streams and Tasks, help streamline operations.
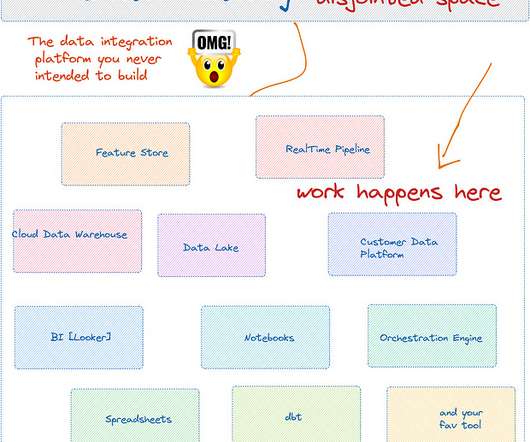
Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. How happy are you with your data catalogs?
Airflow — An open-source platform to programmatically author, schedule, and monitor data pipelines. Apache Oozie — An open-source workflow scheduler system to manage Apache Hadoop jobs. DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively.
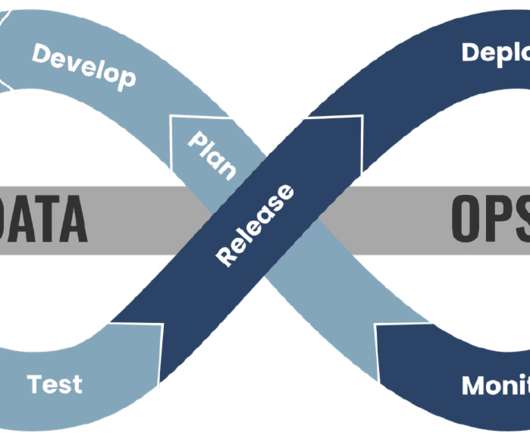
Data Orchestration Data orchestration refers to the coordination and management of dataworkflows, from data ingestion to data processing and analysis. DataOps tools should offer powerful data orchestration capabilities, allowing organizations to build, schedule, and monitor dataworkflows with ease.
The “legacy” table formats The data landscape has evolved so quickly that table formats pioneered within the last 25 years are already achieving “legacy” status. It was designed to support high-volume data exchange and compatibility across different system versions, which is essential for streaming architectures such as Apache Kafka.
Data orchestration involves managing the scheduling and execution of dataworkflows. As for this part, Apache Airflow is a popular open-source platform choice used for data orchestration across the entire data pipeline. A simplified diagram shows the major components of Airbnb’s data infrastructure stack.
Data Aggregation Working with a sample of big data allows you to investigate real-time data processing, big data project design, and data flow. Learn how to aggregate real-time data using several big data tools like Kafka, Zookeeper, Spark, HBase, and Hadoop.
Users can also leverage it for generating interactive visualizations over data. It also comes with lots of automation techniques that qualify users to eliminate manual dataworkflows. It can analyze data in real-time and can perform cluster management. It is much faster than other analytic workload tools like Hadoop.
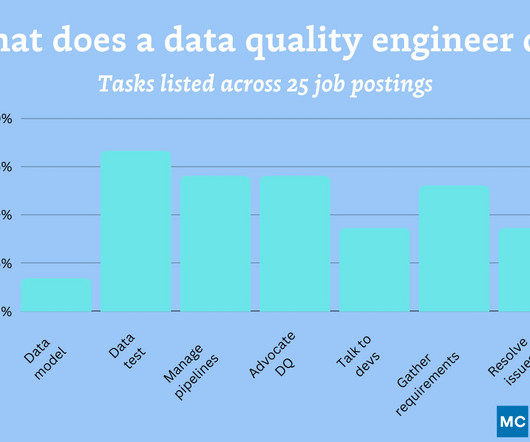
Data quality engineers also need to have experience operating in cloud environments and using many of the modern data stack tools that are utilized in building and maintaining data pipelines. 78% of job postings referenced at least part of their environment was in a modern data warehouse, lake, or lakehouse.
But even as the modern data stack continues to evolve, Airflow maintains its title as a perennial data orchestration favorite—and for good reason. Luigi’s strength lies in its ability to stitch together a variety of seemingly disparate tasks, be it a Hadoop job, a Hive query, or even a local data dump.
Why Should You Get an Azure Data Engineer Certification? Becoming an Azure data engineer allows you to seamlessly blend the roles of a data analyst and a data scientist. One of the pivotal responsibilities is managing dataworkflows and pipelines, a core aspect of a data engineer's role.
Role Level: Intermediate Responsibilities Design and develop big data solutions using Azure services like Azure HDInsight, Azure Databricks, and Azure Data Lake Storage. Implement data ingestion, processing, and analysis pipelines for large-scale data sets.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. Accessible via a unified API, these new features enhance search relevance and are available on Elastic Cloud.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
This includes knowledge of data structures (such as stack, queue, tree, etc.), A Machine Learning professional needs to have a solid grasp on at least one programming language such as Python, C/C++, R, Java, Spark, Hadoop, etc. Machine Learning engineers are often required to collaborate with data engineers to build dataworkflows.
phData Cloud Foundation is dedicated to machine learning and data analytics, with prebuilt stacks for a range of analytical tools, including AWS EMR, Airflow, AWS Redshift, AWS DMS, Snowflake, Databricks, Cloudera Hadoop, and more. This helps drive requirements and determines the right validation at the right time for the data.
The era of Big Data was characterised by Hadoop, HDFS, distributed computing (Spark), above the JVM. That's why big data technologies got swooshed by the modern data stack when it arrived on the market—excepting Spark. We need to store, process and visualise data, everything else is just marketing.
DevOps tasks — for example, creating scheduled backups and restoring data from them. Airflow is especially useful for orchestrating Big Dataworkflows. Airflow is not a data processing tool by itself but rather an instrument to manage multiple components of data processing. When Airflow won’t work.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content