This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. And to create significant technology and team efficiencies, organizations need to consider opportunities to integrate LLM pipelines with existing structured dataworkflows.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg?
Canva writes about its custom solution using dbt and metadata capturing to attribute costs, monitor performance, and enable data-driven decision-making, significantly enhancing its Snowflake environment management. link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure.
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. Data As Code is a very strong choice : we do not want any UI because it is an heritage of the ETL period. What you have to code is this workflow ! We want to have our hands free and be totally devoted to devops principles.
These tools can be called by LLM systems to learn about your data and metadata. Remember, as with any AI workflows, to make sure that you are taking appropriate caution in terms of giving these access to production systems and data. What is the best workflow for the current iteration of the MCP server?
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your dataworkflows. Atlan is the metadata hub for your data ecosystem. Missing data? Missing data?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
Data Engineering Weekly readers get 15% discount by registering the following link, [link] Gustavo Akashi: Building data pipelines effortlessly with a DAG Builder for Apache Airflow Every code-first dataworkflow grew into a UI-based or Yaml-based workflow.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. Linked data technologies provide a means of tightly coupling metadata with raw information.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. Once we know what to query for a specific table, we create a task for each partition that executes a job in Dataswarm (our data pipeline system).
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. The only thing worse than having bad data is not knowing that you have it. Atlan is the metadata hub for your data ecosystem.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. What are the contributing factors that lead to fragmentation of visibility for dataworkflows at different stages?
Data lakes are notoriously complex. For data engineers who battle to build and scale high quality dataworkflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
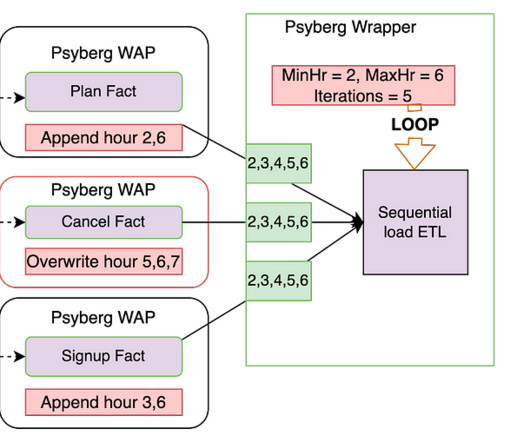
Input : List of source tables and required processing mode Output : Psyberg identifies new events that have occurred since the last high watermark (HWM) and records them in the session metadata table. The session metadata table can then be read to determine the pipeline input. Audit Run various quality checks on the staged data.
Finding the data that you need is tricky, and Amundsen will help you solve that problem. And as your data grows in volume and complexity, there are foundational principles that you can follow to keep dataworkflows streamlined. Finding the data that you need is tricky, and Amundsen will help you solve that problem.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. You can observe your pipelines with built in metadata search and column level lineage.
Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadata management , to be precise.
You can observe your pipelines with built in metadata search and column level lineage. Finally, if you have existing workflows in AbInitio, Informatica or other ETL formats that you want to move to the cloud, you can import them automatically into Prophecy making them run productively on Spark.
What portions of the dataworkflow is Atlan responsible for? What components of the data stack might Atlan replace? How would you characterize Atlan’s position in the current data ecosystem? What makes Atlan stand out from other systems for data cataloguing, metadata management, or data governance?
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Among solutions facilitation data management are. Apache Hadoop ecosystem.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
It facilitates data synchronisation, replication, real-time analytics, and event-driven processing, empowering data-driven decision-making and operational efficiency. These additional columns store metadata like timestamps, user IDs, and change types, ensuring granular change tracking and auditability.
The Unity Catalog is Databricks governance solution which integrates with Databricks workspaces and provides a centralized platform for managing metadata, data access, and security. Improved Data Discovery The tagging and documentation features in Unity Catalog facilitate better data discovery.
At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files. Table formats incorporate aspects like columns, rows, data types, and relationships, but can also include information about the structure of the data itself.
Netflix Scheduler is built on top of Meson which is a general purpose workflow orchestration and scheduling framework to execute and manage the lifecycle of the dataworkflow. Bulldozer makes data warehouse tables more accessible to different microservices and reduces each individual team’s burden to build their own solutions.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The author walked through various strategies, from sync to async job submission and batch job submission strategy.
It uses the dbt Cloud Metadata API to surface metadata from dbt right in Hex, letting you quickly get the context you need on things like data freshness without juggling multiple apps and browser tabs. Hex just launched an integration with dbt! Get started here. Things to Watch ? What's missing? Spreadsheets?
Editor’s Note: The current state of the Data Catalog The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. We saw in the Data Catalog poll how far it has to go to be helpful and active within a dataworkflow.
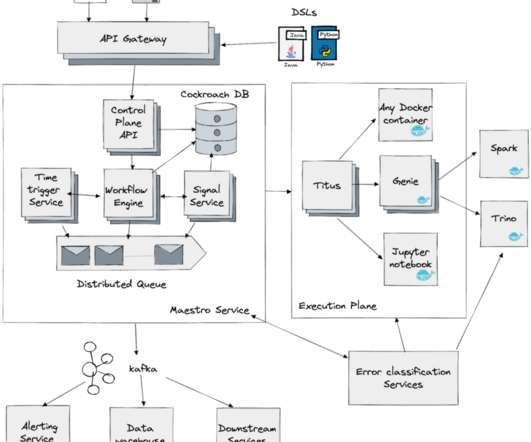
This enables auto propagation of backfill data in multi-stage pipelines. Netflix Maestro Maestro is the Netflix dataworkflow orchestration platform built to meet the current and future needs of Netflix. As we know, an iceberg table contains a list of snapshots with a set of metadatadata.
Cloudera provides a unified platform with multiple data apps and tools, big data management, hybrid cloud deployment flexibility, admin tools for platform provisioning and control, and a shared data experience for centralized security, governance, and metadata management. 3. Expansion beyond core data management.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. So, why is data orchestration a big deal? It automates and optimizes data processes, reducing manual effort and the likelihood of errors.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
DataOps tools should provide a comprehensive data cataloging solution that allows organizations to create a centralized repository of their data assets, complete with metadata, data lineage information, and data samples.
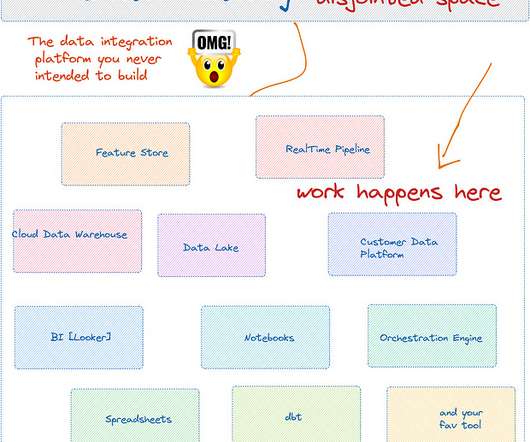
[link] Data Engineering Weekly Data Catalog - A Broken Promise Data catalogs are the most expensive data integration systems you never intended to build.
With the high growth of workflows in the past few years?—?increasing increasing at > 100% a year, the need for a scalable dataworkflow orchestrator has become paramount for Netflix’s business needs. A workflow instance is an execution of a workflow, similarly, an execution of a step is called a step instance.
AI-powered Monitor Recommendations that leverage the power of data profiling to suggest appropriate monitors based on rich metadata and historic patterns — greatly simplifying the process of discovering, defining, and deploying field-specific monitors.
Disadvantages of a data lake are: Can easily become a data swamp data has no versioning Same data with incompatible schemas is a problem without versioning Has no metadata associated It is difficult to join the dataData warehouse stores processed data, mostly structured data.
The governance aspect is perhaps even more important and businesses need to be able to understand where the data comes from. Data lineage, personally identifiable information or PPI and metadata all fall under a broad data governance banner which is critically important in terms of what needs to be protected and mapped out.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content