This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. As data volumes grow and AI automation expands, cost efficiency in processing with LLMs depends on both system architecture and model flexibility.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
The system leverages a combination of an event-based storage model in its TimeSeries Abstraction and continuous background aggregation to calculate counts across millions of counters efficiently. link] Grab: Metasense V2 - Enhancing, improving, and productionisation of LLM-powered data governance. Boyter on Bloom Filters and SQLite.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. You can observe your pipelines with built in metadata search and column level lineage.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. What are the other systems that feed into and rely on the Trino/Iceberg service? What are the other systems that feed into and rely on the Trino/Iceberg service?
Instead of driving innovation, data engineers often find themselves bogged down with maintenance tasks. On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Tool sprawl is another hurdle that data teams must overcome.
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. Imagine a library with millions of books but no catalog system to organize them.
Instead of driving innovation, data engineers often find themselves bogged down with maintenance tasks. On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Tool sprawl is another hurdle that data teams must overcome.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. It's good to know about Dapr and restate.dev.
Summary There are extensive and valuable data sets that are available outside the bounds of your organization. Whether that data is public, paid, or scraped it requires investment and upkeep to acquire and integrate it with your systems. Atlan is the metadata hub for your data ecosystem.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. What is the level of native support/compatibiliity that you see for JSON-LD in datasystems?
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your dataworkflows. Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or data warehouse table that you are working with. Atlan is the metadata hub for your data ecosystem. Data lineage and metadatasystems are a hot topic right now.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. What are the contributing factors that lead to fragmentation of visibility for dataworkflows at different stages?
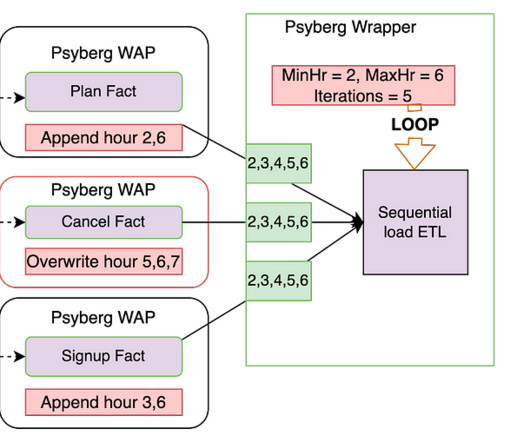
Input : List of source tables and required processing mode Output : Psyberg identifies new events that have occurred since the last high watermark (HWM) and records them in the session metadata table. The session metadata table can then be read to determine the pipeline input. Audit Run various quality checks on the staged data.
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps. How does security factor into the design of robust DataOps systems?
In this episode Prukalpa Sankar shares her experiences across multiple attempts at building a system that brings everyone onto the same page, ultimately bringing her to found Atlan. What portions of the dataworkflow is Atlan responsible for? What components of the data stack might Atlan replace?
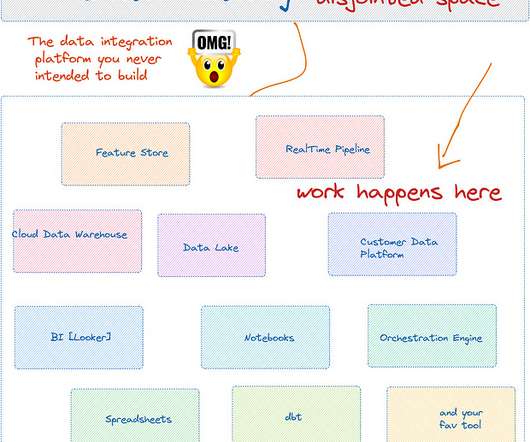
Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. It makes rolling out the data catalogs.
You don’t need to archive or clean data before loading. The system automatically replicates information to prevent data loss in the case of a node failure. It doesn’t belong to the master-slave paradigm, being responsible for loading data into the cluster, describing how the data must be processed, and retrieving the output.
Change Data Capture (CDC) is a powerful technique that revolutionises data engineering by capturing and applying incremental changes to databases or data sources. It bridges gaps in data ecosystems, ensuring consistency and synchronisation across systems.
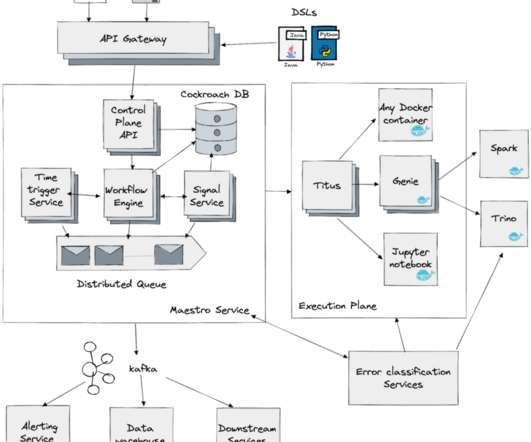
Due to its popularity, the number of workflows managed by the system has grown exponentially. The scheduler on-call has to closely monitor the system during non-business hours. As the usage increased, we had to vertically scale the system to keep up and were approaching AWS instance type limits.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Figure 1 shows how we use Bulldozer to move data at Netflix.
At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files. Table formats incorporate aspects like columns, rows, data types, and relationships, but can also include information about the structure of the data itself.
Editor’s Note: The current state of the Data Catalog The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. The current state of these systems is inherently passive systems.
Is your data stuck in separate areas within your company, making it hard to use effectively? Here’s the deal: for data to truly drive your business forward, you need a reliable and scalable system to keep it moving without hiccups. In other words, you need data orchestration. So, why is data orchestration a big deal?
It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. Data Sources Data sources are the backbone of any DataOps architecture.
DataOps tools should provide a comprehensive data cataloging solution that allows organizations to create a centralized repository of their data assets, complete with metadata, data lineage information, and data samples. This allows it to be easily integrated with other services and systems.
[link] Data Engineering Weekly Data Catalog - A Broken Promise Data catalogs are the most expensive data integration systems you never intended to build.
The multiple databases will be queried, then passed through the transformation server to transform the data to comply with the business rule then the transformed the data is stored in a data store. This is also used for legacy systems. This means that your data store has to have capabilities of transforming the data.
This is accomplished by continuously monitoring, tracking, alerting, analyzing and troubleshooting dataworkflows to reduce problems and prevent data errors or system downtime.” Our perspective: Gartner does a good job covering what’s being monitored and the workflows associated with data observability tools.
For example, a global media company struggled because they were juggling different tools like Fivetran for bringing in data, dbt for transforming it, Airflow for coordinating everything, Monte Carlo for monitoring and scanning for troubled data, and Hightouch for getting data out to other systems.
Follow Mico on LinkedIn 3) Chad Sanderson Chief Operator at Data Quality Camp Chad has extensive experience in data from hyper-growth startups to established tech supergiants to small businesses just dipping their toes into ecommerce. Seth has experience in leading corporate wide strategies across complex corporate organizations.
The Azure Data Engineer Certification test evaluates one's capacity for organizing and putting into practice data processing, security, and storage, as well as their capacity for keeping track of and maximizing data processing and storage. Why Should You Get an Azure Data Engineer Certification?
Here’s how Prefect , Series B startup and creator of the popular data orchestration tool, harnessed the power of data observability to preserve headcount, improve data quality and reduce time to detection and resolution for data incidents. But Monte Carlo doesn’t stop at the “most important” tables.
From those home-made beginnings as Compass, Elasticsearch has matured into one of the leading enterprise search engines, standing among the top 10 most popular database management systems globally according to the Stack Overflow 2023 Developer Survey. But like any technology, it has its share of pros and cons.
One of the key elements of Azure Data Factory that permits data integration between various network environments is Integration Runtime. It offers the infrastructure needed to transfer data safely between cloud and on-site data storage.
Theoretically, data and analytics should be the backbones of decision-making in business. Like mitochondria power a cell, data powers a business. Today, there are no intelligent systems that deliver data at the pace, and with the impact, leaders need to power the business. But for most companies, that’s not the reality.
Theoretically, data and analytics should be the backbones of decision-making in business. Like mitochondria power a cell, data powers a business. Today, there are no intelligent systems that deliver data at the pace, and with the impact, leaders need to power the business. But for most companies, that’s not the reality.
What is data pipeline architecture? Data pipeline architecture is the process of designing how data is surfaced from its source system to the consumption layer. Data orchestration Airflow : Airflow is the most common data orchestrator used by data teams. Now Go Build Some Data Pipelines!
Data pipeline observability means having robust monitoring, logging, and alerting across all pipeline components. Metadata is the foundation of observability, providing essential insights into data pipeline health, execution status, dependencies, and performance metrics. Did yesterdays data load complete successfully?
DevOps tasks — for example, creating scheduled backups and restoring data from them. Airflow is especially useful for orchestrating Big Dataworkflows. Airflow is not a data processing tool by itself but rather an instrument to manage multiple components of data processing. Metadata database. Since the 2.0
Automated Data Classification and Governance LLMs are reshaping governance practices. Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content