
How I Optimized Large-Scale Data Ingestion
databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.

databricks
SEPTEMBER 6, 2024
Explore being a PM intern at a technical powerhouse like Databricks, learning how to advance data ingestion tools to drive efficiency.

Hevo
JUNE 20, 2024
As data collection within organizations proliferates rapidly, developers are automating data movement through Data Ingestion techniques. However, implementing complex Data Ingestion techniques can be tedious and time-consuming for developers.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Monte Carlo
MAY 28, 2024
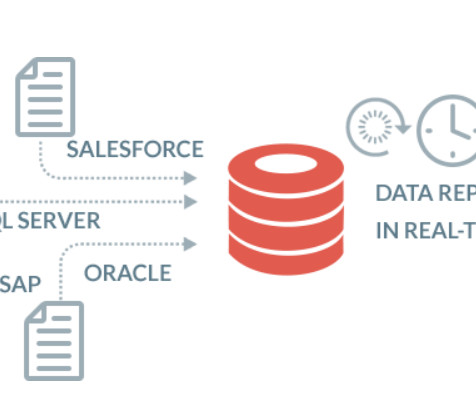
A data ingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process.
Hevo
APRIL 26, 2024
Managing vast data volumes is a necessity for organizations in the current data-driven economy. To accommodate lengthy processes on such data, companies turn toward Data Pipelines which tend to automate the work of extracting data, transforming it and storing it in the desired location.
Cloudyard
JUNE 6, 2023
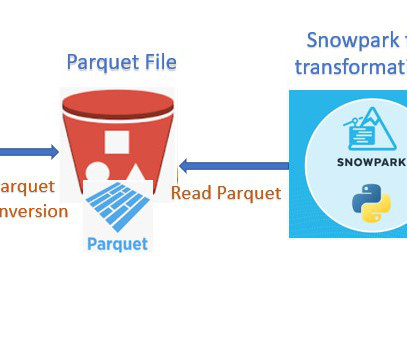
Parquet, columnar storage file format saves both time and space when it comes to big data processing. COPY the data from external stage to Snowflake table created in previous step. Read the data from the table and filtered only Active status records in dataframe. Load the dataframe into Snowflake in the new table.

Snowflake
JANUARY 26, 2023
Accessing data from the manufacturing shop floor is one of the key topics of interest with the majority of cloud platform vendors due to the pace of Industry 4.0 practices is the ability to collect and analyze vast amounts of data, allowing for improved efficiency, accuracy, and decision-making. Industry 4.0, cannot be overstated.

Hevo
MARCH 28, 2023
As businesses continue to generate and collect large amounts of data, the need for automated data ingestion becomes increasingly critical. The process of ingesting and processing vast amounts of information can be overwhelming.

Expert insights. Personalized for you.




































Let's personalize your content