This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Data Quality Testing: A Shared Resource for Modern Data Teams In today’s AI-driven landscape, where data is king, every role in the modern data and analytics ecosystem shares one fundamental responsibility: ensuring that incorrect data never reaches business customers. Each role touches data differently.
These organizations and many more are using Hybrid Tables to simplify their data architectures and governance and security by consolidating transactional and analytical workloads onto Snowflake's single unified data platform. Roofstock, a leading investment platform for single-family rentals, is seeing these benefits firsthand. "We
The modern data stack constantly evolves, with new technologies promising to solve age-old problems like scalability, cost, and data silos. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Data Silos: Breaking down barriers between data sources.
Join Dagster and Neurospace to learn: - How to build AI pipelines with orchestration baked in - How to track data lineage for audits and traceability - Tips for designing compliant workflows under the EU AI Act Register for the technical session DuckDB: DuckLake - SQL as a Lakehouse Format DuckDB announced a new open table format, DuckLake.
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
This guide is your roadmap to building a data lake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable data lake. Traditional data storage systems like data warehouses were designed to handle structured and preprocessed data.
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Summary Data is useless if it isn’t being used, and you can’t use it if you don’t know where it is. Data catalogs were the first solution to this problem, but they are only helpful if you know what you are looking for. Data stacks are becoming more and more complex. Sifflet also offers a 2-week free trial.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
A machine learning pipeline helps automate machine learning workflows by processing and integrating data sets into a model, which can then be evaluated and delivered. The machine learning pipeline offers data scientists a way to handle data for training, orchestrate models, and monitor them in deployment.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Are you ready to step into the heart of big data projects and take control of data like a pro?
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. These are common LinkedIn requests. The article resonated with me when I read it.
Today, data engineers are constantly dealing with a flood of information and the challenge of turning it into something useful. The journey from raw data to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process.
Accessing data from the manufacturing shop floor is one of the key topics of interest with the majority of cloud platform vendors due to the pace of Industry 4.0 practices is the ability to collect and analyze vast amounts of data, allowing for improved efficiency, accuracy, and decision-making. Industry 4.0, cannot be overstated.
Register now Home Insights Data platform Article How To Use Airbyte, dbt-teradata, Dagster, and Teradata Vantage™ for Seamless Data Integration Build and orchestrate a data pipeline in Teradata Vantage using Airbyte, Dagster, and dbt. In this case, we select Sample Data (Faker). dbt-core dagster==1.7.9
The adaptability and technical superiority of such open-source big data projects make them stand out for community use. As per the surveyors, Big data (35 percent), Cloud computing (39 percent), operating systems (33 percent), and the Internet of Things (31 percent) are all expected to be impacted by open source shortly.
Becoming a successful aws data engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. million organizations that want to be data-driven choose AWS as their cloud services partner. Table of Contents Why Learn AWS for Data Engineering?
Sifflet is a platform that brings your entire data stack into focus to improve the reliability of your data assets and empower collaboration across your teams. In this episode CEO and founder Salma Bakouk shares her views on the causes and impacts of "data entropy" and how you can tame it before it leads to failures.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange.
[link] Jing Ge: Context Matters — The Vision of Data Analytics and Data Science Leveraging MCP and A2A All aspects of software engineering are rapidly being automated with various coding AI tools, as seen in the AI technology radar. Data engineering is one aspect where I see a few startups starting to disrupt.
Data is often referred to as the new oil, and just like oil requires refining to become useful fuel, data also needs a similar transformation to unlock its true value. This transformation is where data warehousing tools come into play, acting as the refining process for your data. Why Choose a Data Warehousing Tool?
Microsoft Fabric is a next-generation data platform that combines business intelligence, data warehousing, real-time analytics, and data engineering into a single integrated SaaS framework. The architecture of Microsoft Fabric is based on several essential elements that work together to simplify data processes: 1.
It discusses the RAG architecture, outlining key stages like dataingestion , data retrieval, chunking , embedding generation , and querying. With step-by-step examples, you'll learn to integrate data from text files and PDFs while leveraging embeddings for precision.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Explore what is Apache Iceberg, what makes it different, and why it’s quickly becoming the new standard for data lake analytics. Data lakes were born from a vision to democratize data, enabling more people, tools, and applications to access a wider range of data. Metadata Layer 3. Workarounds became the norm.
By the time I left in 2013, I was a data engineer. We were data engineers! Data Engineering? Data science as a discipline was going through its adolescence of self-affirming and defining itself. At the same time, data engineering was the slightly younger sibling, but it was going through something similar.
By incorporating external data, it ensures better accuracy and relevance. A RAG and LLM architecture enhances the performance of LLMs like GPT or Llama2 , by integrating external data retrieval to produce more accurate and context-aware responses. These vectors are stored in a vector database for quick retrieval.
Did you know over 5140 businesses worldwide started using AWS Glue as a big data tool in 2023? With the rapid growth of data in the industry, businesses often deal with several challenges when handling complex processes such as data integration and analytics.
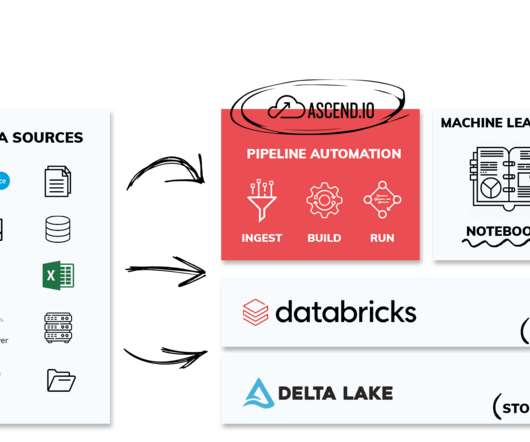
We hope the real-time demonstrations of Ascend automating data pipelines were a real treat—a long with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below). With this approach, we’re able to augment our uniquely beautiful and intuitive visualization of data pipelines.
Summary The best way to make sure that you don’t leak sensitive data is to never have it in the first place. The team at Skyflow decided that the second best way is to build a storage system dedicated to securely managing your sensitive information and making it easy to integrate with your applications and data systems.
Looking for an efficient tool for streamlining and automating your data processing workflows? Let's consider an example of a data processing pipeline that involves ingestingdata from various sources, cleaning it, and then performing analysis. Apache Airflow DAGs are your one-stop solution!
This blog post provides an overview of the top 10 data engineering tools for building a robust data architecture to support smooth business operations. Table of Contents What are Data Engineering Tools? Dice Tech Jobs report 2020 indicates Data Engineering is one of the highest in-demand jobs worldwide.
Cloud computing is the future, given that the data being produced and processed is increasing exponentially. As per the March 2022 report by statista.com, the volume for global data creation is likely to grow to more than 180 zettabytes over the next five years, whereas it was 64.2 Is AWS Athena a Good Choice for your Big Data Project?
Snowflake provides a strong data foundation anchored on unified data, optimal TCO and universal governance. The Snowflake platform eliminates silos to enable any architectural pattern, while supporting all data types and workloads. These capabilities can even be extended to Iceberg tables created by other engines.
Experience Enterprise-Grade Apache Airflow Astro augments Airflow with enterprise-grade features to enhance productivity, meet scalability and availability demands across your data pipelines, and more. Hudi seems to be a de facto choice for CDC data lake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! “Data analytics is the future, and the future is NOW!
Learn data engineering, all the references ( credits ) This is a special edition of the Data News. But right now I'm in holidays finishing a hiking week in Corsica 🥾 So I wrote this special edition about: how to learn data engineering in 2024. The idea is to create a living reference about Data Engineering.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. For example, we have a service that stores a movie entity’s metadata or a service that stores metadata about images. Allows to annotate any entity.
In the thought process of making a career transition from ETL developer to data engineer job roles? Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., differ from ETL developer and the additional skills you need to transition from ETL developer to data engineer job roles.
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content