This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of data storage to store and manage their data effectively.
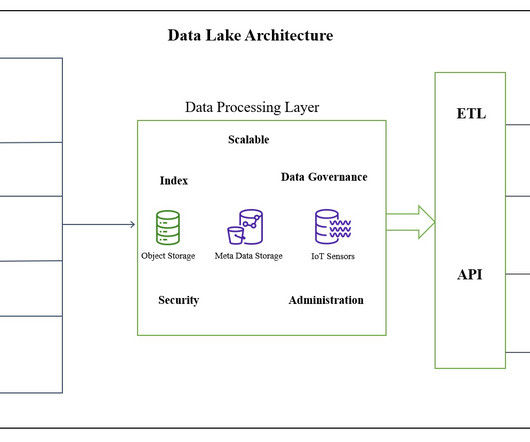
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Summary Batch vs. streaming is a long running debate in the world of data integration and transformation. In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time datalake without all of the headache.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Summary Monitoring and auditing IT systems for security events requires the ability to quickly analyze massive volumes of unstructured log data. Cliff Crosland co-founded Scanner to provide fast querying of high scale log data for security auditing. SIEM) A query engine is useless without data to analyze.
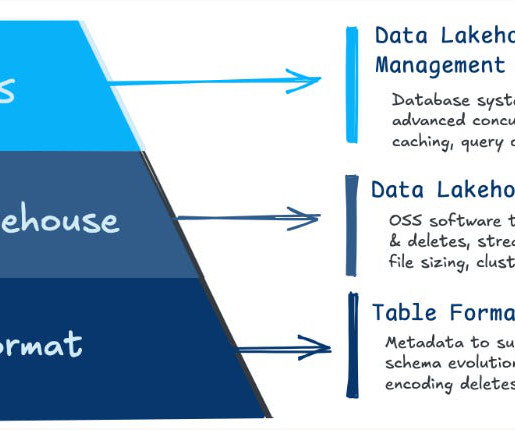
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a Data Warehouse? Asked yourself what components and features would that include.
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a Data Warehouse? Asked yourself what components and features would that include.
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Introduction Datalakes and data warehouses DatalakeData warehouse Criteria to choose lake and warehouse tools Conclusion Further reading References Introduction With the data ecosystem growing fast, new terms are coming up every week.
By Reseun McClendon Today, your enterprise must effectively collect, store, and integrate data from disparate sources to both provide operational and analytical benefits. Whether its helping increase revenue by finding new customers or reducing costs, all of it starts with data.
Digital tools and technologies help organizations generate large amounts of data daily, requiring efficient governance and management. This is where the AWS datalake comes in. With the AWS datalake, organizations and businesses can store, analyze, and process structured and unstructured data of any size.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. Join in with the event for the global data community, Data Council Austin.
Summary Datalake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis.
A few months ago, I uploaded a video where I discussed data warehouses, datalakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning.
Meroxa was created to enable teams of all sizes to deliver real-time data applications. In this episode DeVaris Brown discusses the types of applications that are possible when teams don't have to manage the complex infrastructure necessary to support continuous data flows. Can you describe what Meroxa is and the story behind it?
Advanced AI will open up new attack vectors and also deliver new tools for protecting an organizations data. But the underlying challenge is the sheer quantity of data that overworked cybersecurity teams face as they try to answer basic questions such as, Are we under attack?
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
Datalake structure 5. Loading user purchase data into the data warehouse 5.2 Loading classified movie review data into the data warehouse 5.3 Introduction 2. Objective 3. Prerequisite 4.2 AWS Infrastructure costs 4.3 Code walkthrough 5.1 Generating user behavior metric 5.4. Checking results 6.
Data Access API over DataLake Tables Without the Complexity Build a robust GraphQL API service on top of your S3 datalake files with DuckDB and Go Photo by Joshua Sortino on Unsplash 1. This data might be primarily used for internal reporting, but might also be valuable for other services in our organization.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud data warehouse to Snowflake and some of the benefits they saw. million in cost savings annually.
Summary Data transformation is a key activity for all of the organizational roles that interact with data. Because of its importance and outsized impact on what is possible for downstream data consumers it is critical that everyone is able to collaborate seamlessly. Can you describe what SQLMesh is and the story behind it?
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Datalakes are notoriously complex.
We thank Vishnu Vettrivel, Founder, and Alex Thomas, Principal Data Scientist, for their contributions. This is a collaborative post from Databricks and wisecube.ai.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
Together with a dozen experts and leaders at Snowflake, I have done exactly that, and today we debut the result: the “ Snowflake Data + AI Predictions 2024 ” report. When you’re running a large language model, you need observability into how the model may change as it ingests new data. The next evolution in data is making it AI ready.
What if your datalake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data. represented a significant leap forward in data lakehouse technology. Exploring Apache Hudi 1.0:
Photo by Tiger Lily Data warehouses and datalakes play a crucial role for many businesses. It gives businesses access to the data from all of their various systems. As well as often integrating data so that end-users can answer business critical questions.
Ready to boost your Hadoop DataLake security on GCP? Our latest blog dives into enabling security for Uber’s modernized batch datalake on Google Cloud Storage!
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Summary Stripe is a company that relies on data to power their products and business. In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
Summary A core differentiator of Dagster in the ecosystem of data orchestration is their focus on software defined assets as a means of building declarative workflows. Datalakes are notoriously complex. Your first 30 days are free! Want to see Starburst in action? What problems are you trying to solve with Dagster+?
Summary Building a data platform is a substrantial engineering endeavor. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management This episode is supported by Code Comments, an original podcast from Red Hat. Datalakes are notoriously complex.
A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. Want to see Starburst in action?
Summary Maintaining a single source of truth for your data is the biggest challenge in data engineering. Different roles and tasks in the business need their own ways to access and analyze the data in the organization. Dagster offers a new approach to building and running data platforms and data pipelines.
Summary Data lakehouse architectures are gaining popularity due to the flexibility and cost effectiveness that they offer. The link that bridges the gap between datalake and warehouse capabilities is the catalog. Datalakes are notoriously complex. Your first 30 days are free! Want to see Starburst in action?
Summary Data lakehouse architectures have been gaining significant adoption. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. What are the benefits of embedding Copilot into the data engine?
Petr shares his journey from being an engineer to founding Synq, emphasizing the importance of treating data systems with the same rigor as engineering systems. He discusses the challenges and solutions in data reliability, including the need for transparency and ownership in data systems. Want to see Starburst in action?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content