This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of data storage to store and manage their data effectively.
Data storage has been evolving, from databases to datawarehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud datawarehouse to Snowflake and some of the benefits they saw.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Introduction Datalakes and datawarehousesDatalakeDatawarehouse Criteria to choose lake and warehouse tools Conclusion Further reading References Introduction With the data ecosystem growing fast, new terms are coming up every week.
By Reseun McClendon Today, your enterprise must effectively collect, store, and integrate data from disparate sources to both provide operational and analytical benefits. Whether its helping increase revenue by finding new customers or reducing costs, all of it starts with data.
A few months ago, I uploaded a video where I discussed datawarehouses, datalakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Datalake structure 5. Loading user purchase data into the datawarehouse 5.2 Loading classified movie review data into the datawarehouse 5.3 Introduction 2. Objective 3. Prerequisite 4.2 AWS Infrastructure costs 4.3 Code walkthrough 5.1 Generating user behavior metric 5.4. Checking results 6.
Summary Batch vs. streaming is a long running debate in the world of data integration and transformation. In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time datalake without all of the headache.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Datalakes are notoriously complex. Join in with the event for the global data community, Data Council Austin.
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a DataWarehouse? Asked yourself what components and features would that include.
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a DataWarehouse? Asked yourself what components and features would that include.
Summary Datalake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis.
NetSpring is a warehouse-native product analytics service that allows you to gain powerful insights into your customers and their needs by combining your event streams with the rest of your business data. Visit: dataengineeringpodcast.com/data-council today! Don't miss out on their only event this year!
Summary Data transformation is a key activity for all of the organizational roles that interact with data. Because of its importance and outsized impact on what is possible for downstream data consumers it is critical that everyone is able to collaborate seamlessly. Can you describe what SQLMesh is and the story behind it?
Photo by Tiger Lily Datawarehouses and datalakes play a crucial role for many businesses. It gives businesses access to the data from all of their various systems. As well as often integrating data so that end-users can answer business critical questions.
Summary There is a lot of attention on the database market and cloud datawarehouses. While they provide a measure of convenience, they also require you to sacrifice a certain amount of control over your data. Firebolt is the fastest cloud datawarehouse. Visit dataengineeringpodcast.com/firebolt to get started.
Together with a dozen experts and leaders at Snowflake, I have done exactly that, and today we debut the result: the “ Snowflake Data + AI Predictions 2024 ” report. When you’re running a large language model, you need observability into how the model may change as it ingests new data. The next evolution in data is making it AI ready.
Summary Datawarehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
Summary Datalakes offer a great deal of flexibility and the potential for reduced cost for your analytics, but they also introduce a great deal of complexity. In order to bring the DBA into the new era of data management the team at Upsolver added a SQL interface to their datalake platform.
Data is central to modern business and society. Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly.
Summary One of the perennial challenges posed by datalakes is how to keep them up to date as new data is collected. In this episode Ori Rafael shares his experiences from Upsolver and building scalable stream processing for integrating and analyzing data, and what the tradeoffs are when coming from a batch oriented mindset.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
Cloud datawarehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. The results demonstrate superior price performance of Cloudera DataWarehouse on the full set of 99 queries from the TPC-DS benchmark. Introduction. higher cost.
A substantial amount of the data that is being managed in these systems is related to customers and their interactions with an organization. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex. Want to see Starburst in action?
Summary The customer data platform is a category of services that was developed early in the evolution of the current era of cloud services for data processing. Now that the datawarehouse has taken center stage a new approach of composable customer data platforms is emerging.
Summary Designing a data platform is a complex and iterative undertaking which requires accounting for many conflicting needs. Designing a platform that relies on a datalake as its central architectural tenet adds additional layers of difficulty. Missing data? Struggling with broken pipelines? Stale dashboards?
Getting data out of source systems and into a datawarehouse or datalake is one of the first steps in making it usable by analysts and data scientists. The question is how will your team do that?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Summary Building a data team is hard in any circumstance, but at a startup it can be even more challenging. The requirements are fluid, you probably don't have a lot of existing data talent to manage the hiring and onboarding, and there is a need to move fast. What are the concepts that the new hire needs to know?
Anyone who’s been roaming around the forest of Data Engineering has probably run into many of the newish tools that have been growing rapidly around the concepts of DataWarehouses, DataLakes, and Lake Houses … the merging of the old relational database functionality with TB and PB level cloud-based file storage systems.
Summary The predominant pattern for data integration in the cloud has become extract, load, and then transform or ELT. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
In that time there have been a number of generational shifts in how data engineering is done. Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Materialize]([link] Looking for the simplest way to get the freshest data possible to your teams?
In this episode the host Tobias Macey shares his reflections on recent experiences where the abstractions leaked and some observances on how to deal with that situation in a data platform architecture. What do you have planned for the future of your data platform? When is ELT the wrong choice?
Summary Cloud datawarehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used. We feel your pain.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Notably, the process includes an RL step to create a specialized reasoning model (R1-Zero) capable of excelling in reasoning tasks without labeled SFT data, highlighting advancements in training methodologies for AI models. It employs a two-tower model approach to learn query and item embeddings from user engagement data.
Summary A significant portion of the time spent by data engineering teams is on managing the workflows and operations of their pipelines. Agile Data Engine is a platform designed to handle the infrastructure side of the DataOps equation, as well as providing the insights that you need to manage the human side of the workflow.
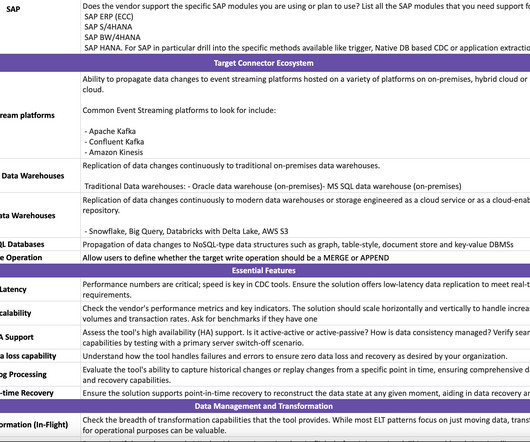
TL;DR Aswin and I are thrilled to announce the release of the first version of our comprehensive guide for evaluating Change Data Capture. Why CDC is More Relevant in Unified Data Architecture As we advance into the Gen AI era, Change Data Capture (CDC) systems are emerging as crucial components of the ever-evolving data architecture.
Summary With all of the messaging about treating data as a product it is becoming difficult to know what that even means. Vishal Singh is the head of products at Starburst which means that he has to spend all of his time thinking and talking about the details of product thinking and its application to data.
Currently, data management is a continually developing field that requires careful consideration when deciding which solution should be implemented to store, process, and analyze data effectively. There are two forms that are frequently selected: datawarehouse vs datalake.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content