This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional datalakes, enter the world of Databricks Delta Lake now. Delta Lake is a game-changer for big data.
This guide is your roadmap to building a datalake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable datalake. Traditional data storage systems like data warehouses were designed to handle structured and preprocessed data.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
Together with a dozen experts and leaders at Snowflake, I have done exactly that, and today we debut the result: the “ Snowflake Data + AI Predictions 2024 ” report. When you’re running a large language model, you need observability into how the model may change as it ingests new data. The next evolution in data is making it AI ready.
It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Here’s a closer look.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
The open data lakehouse is quickly becoming the standard architecture for unified multifunction analytics on large volumes of data. It combines the flexibility and scalability of datalake storage with the data analytics, data governance, and data management functionality of the data warehouse.
Summary Stripe is a company that relies on data to power their products and business. In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
Do ETL and data integration activities seem complex to you? Read this blog to understand everything about AWS Glue that makes it one of the most popular data integration solutions in the industry. Did you know the global big data market will likely reach $268.4 Businesses are leveraging big data now more than ever.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. However, there is a fundamental challenge standing in the way of being successful: data.
Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse big data environments.
In that time there have been a number of generational shifts in how data engineering is done. Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Materialize]([link] Looking for the simplest way to get the freshest data possible to your teams?
Summary Cloud data warehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used. We feel your pain.
Summary Building a data platform that is enjoyable and accessible for all of its end users is a substantial challenge. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Datalakes are notoriously complex.
Explore what is Apache Iceberg, what makes it different, and why it’s quickly becoming the new standard for datalake analytics. Datalakes were born from a vision to democratize data, enabling more people, tools, and applications to access a wider range of data. Metadata Layer 3.
Summary Machine learning has become a meaningful target for data applications, bringing with it an increase in the complexity of orchestrating the entire data flow. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
Thousands of customers have worked with Snowflake to cost-effectively build a secure data foundation as they look to solve a growing variety of business problems with more data. Increasingly customers are looking to expand that powerful foundation to a broader set of data across their enterprise. Why use Iceberg Tables?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ?
Data engineering is the foundation for data science and analytics by integrating in-depth knowledge of data technology, reliable data governance and security, and a solid grasp of data processing. Data engineers need to meet various requirements to build data pipelines.
Summary One of the reasons that data work is so challenging is because no single person or team owns the entire process. This introduces friction in the process of collecting, processing, and using data. In order to reduce the potential for broken pipelines some teams have started to adopt the idea of data contracts.
Try Astro Free → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. The results? will shape the future of DataOps.
In an effort to better understand where data governance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend. With that, let’s get into the governance trends for data leaders! Want to Save This Guide for Later?
In data systems one of the core architectural exercises is data modeling, which can have significant impacts on what is and is not possible for downstream use cases. By incorporating column-level lineage in the data modeling process it encourages a more robust and well-informed design.
"Data and analytics are already shaking up multiple industries, and the effects will only become more pronounced as adoption reaches critical mass.” ” said the McKinsey Global Institute (MGI) in its executive overview of last month's report: "The Age of Analytics: Competing in a Data-Driven World."
The adaptability and technical superiority of such open-source big data projects make them stand out for community use. As per the surveyors, Big data (35 percent), Cloud computing (39 percent), operating systems (33 percent), and the Internet of Things (31 percent) are all expected to be impacted by open source shortly.
Microsoft Fabric is a next-generation data platform that combines business intelligence, data warehousing, real-time analytics, and data engineering into a single integrated SaaS framework. The architecture of Microsoft Fabric is based on several essential elements that work together to simplify data processes: 1.
Fluss is a compelling new project in the realm of real-time data processing. Architecture Difference The first difference is the Data Model. In contrast, Fluss adopts a Lakehouse-native design with structured tables, explicit schemas, and support for all kinds of data types; it directly mirrors the Lakehouse paradigm.
Data is central to modern business and society. Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly.
Apache Iceberg’s ecosystem of diverse adopters, contributors and commercial support continues to grow, establishing itself as the industry standard table format for an open data lakehouse architecture. Snowflake’s support for Iceberg Tables is now in public preview, helping customers build and integrate Snowflake into their lake architecture.
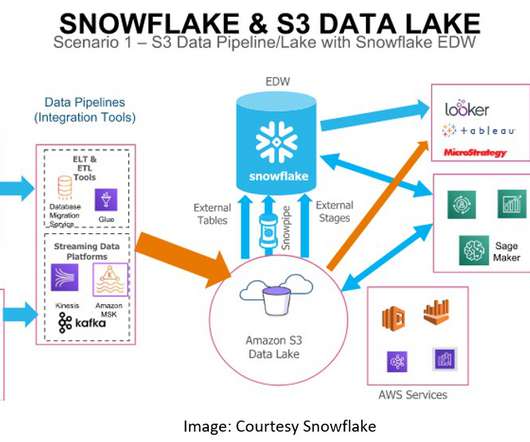
Read Time: 4 Minute, 23 Second During this post we will discuss how AWS S3 service and Snowflake integration can be used as DataLake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake DataLake capabilities. Create S3 bucket to hold the tables data.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. As these assistants evolve, they signal a future where scalable, low-latency data pipelines become essential for seamless, intelligent user experiences.
Becoming a successful aws data engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. million organizations that want to be data-driven choose AWS as their cloud services partner. Table of Contents Why Learn AWS for Data Engineering?
Sifflet is a platform that brings your entire data stack into focus to improve the reliability of your data assets and empower collaboration across your teams. In this episode CEO and founder Salma Bakouk shares her views on the causes and impacts of "data entropy" and how you can tame it before it leads to failures.
Summary Making effective use of data requires proper context around the information that is being used. Rehgan Avon co-founded AlignAI to help address this challenge through a more purposeful platform designed to collect and distribute the knowledge of how and why data is used in a business. Missing data? Stale dashboards?
Get ready for your Netflix Data Engineer interview in 2024 with this comprehensive guide. It's your go-to resource for practical tips and a curated list of frequently asked Netflix Data Engineer Interview Questions and Answers. That's where the role of Netflix Data Engineers comes in. petabytes of data. Interested?
Summary Data governance is a practice that requires a high degree of flexibility and collaboration at the organizational and technical levels. The growing prominence of cloud and hybrid environments in data management adds additional stress to an already complex endeavor.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content