This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RevOps teams want to streamline processes… Read more The post Best Automation Tools In 2025 for DataPipelines, Integrations, and More appeared first on Seattle Data Guy. But automation isnt just for analytics.
Data integration is critical for organizations of all sizes and industriesand one of the leading providers of data integration tools is Talend, which offers the flagship product Talend Studio. In 2023, Talend was acquired by Qlik, combining the two companies data integration and analytics tools under one roof.
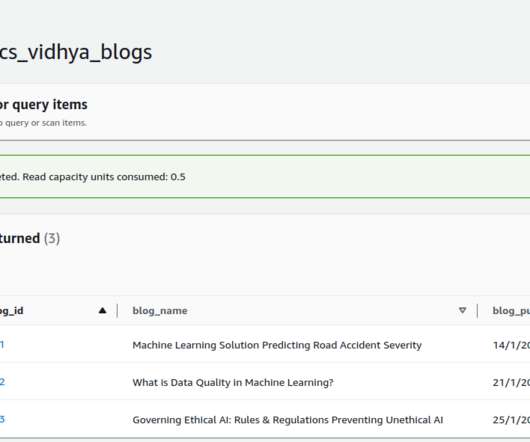
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Building efficient datapipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Introduction 2. Project demo 3. Use DuckDB 4.4.
Adding high-quality entity resolution capabilities to enterprise applications, services, data fabrics or datapipelines can be daunting and expensive. Organizations often invest millions of dollars and years of effort to achieve subpar results.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Introduction Data is fuel for the IT industry and the Data Science Project in today’s online world. IT industries rely heavily on real-time insights derived from streaming data sources. Handling and processing the streaming data is the hardest work for Data Analysis.
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
With over 30 million monthly downloads, Apache Airflow is the tool of choice for programmatically authoring, scheduling, and monitoring datapipelines. Airflow enables you to define workflows as Python code, allowing for dynamic and scalable pipelines suitable to any use case from ETL/ELT to running ML/AI operations in production.
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Introduction Testing your datapipeline 1. Data quality testing 3. Unit and contract testing Conclusion Further reading Introduction Testing datapipelines are different from testing other applications, like a website backend. End-to-end system testing 2. Monitoring and alerting 4.
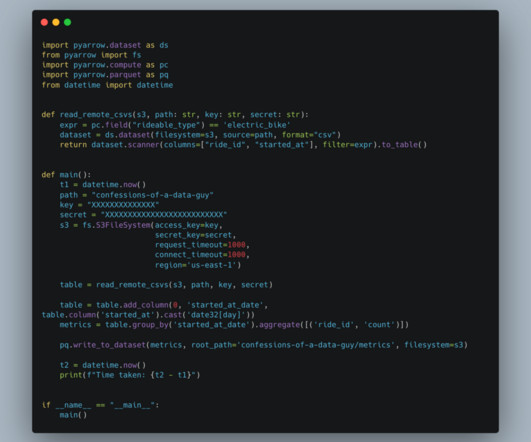
We all keep hearing about Arrow this and Arrow that … seems every new tool built today for Data Engineering seems to be at least partly based on Arrow’s in-memory format. So, […] The post PyArrow vs Polars (vs DuckDB) for DataPipelines. appeared first on Confessions of a Data Guy.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
Rust has been on my mind a lot lately, probably because of Data Engineering boredom, watching Spark clusters chug along like some medieval farm worker endlessly trudging through the muck and mire of life. appeared first on Confessions of a Data Guy. appeared first on Confessions of a Data Guy.
Building datapipelines is a very important skill that you should learn as a data engineer. A datapipeline is just a series of procedures that transport data from one location to another, frequently changing it along the way.
For production grade LLM apps, you need a robust datapipeline. This article talks about the different stages of building a Gen AI datapipeline and what is included in these stages.
Summary Datapipelines are the core of every data product, ML model, and business intelligence dashboard. The folks at Rivery distilled the seven principles of modern datapipelines that will help you stay out of trouble and be productive with your data.
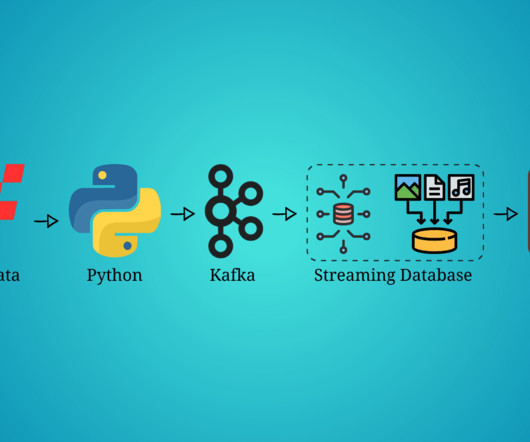
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
Run DataPipelines 2.1. Batch pipelines 3.3. Stream pipelines 3.4. Event-driven pipelines 3.5. LLM RAG pipelines 4. Introduction Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up!
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
We are excited to announce the availability of datapipelines replication, which is now in public preview. In the event of an outage, this powerful new capability lets you easily replicate and failover your entire data ingestion and transformations pipelines in Snowflake with minimal downtime.
In today’s data-driven world, developer productivity is essential for organizations to build effective and reliable products, accelerate time to value, and fuel ongoing innovation. This allows your applications to handle large data sets and complex workflows efficiently.
Have you ever wondered at a high level what it’s like to build production-level datapipelines on Databricks? The post Building Databricks DataPipelines 101 appeared first on Confessions of a Data Guy. What does it look like, what tools do you use?
API Data extraction = GET-ting data from a server 3.1. GET data 3.1.1. GET data for a specific entity 3. HTTP is a protocol commonly used for websites 2.1.1. Request: Ask the Internet exactly what you want 2.1.2. Response is what you get from the server 3.
The rise of AI, for example, will depend on the collaboration between data and development. We’re increasingly seeing software engineering workloads that are deeply intertwined with a strong data foundation. This means faster development and happier data teams. Let’s dive deeper into what we announced.
In this fast-paced digital era, multiple sources like IoT devices, social media platforms, and financial systems generate the data continuously and in real-time. Every business wants to analyze these data in real-time to be ahead in the competitive game. It has the ability to […]
You know, for all the hoards of content, books, and videos produced in the “Data Space” over the last few years, famous or others, it seems I find there are volumes of information on the pieces and parts of working in Data. appeared first on Confessions of a Data Guy.
Data consumers, such as data analysts, and business users, care mostly about the production of data assets. On the other hand, data engineers have historically focused on modeling the dependencies between tasks (instead of data assets) with an orchestrator tool. How can we reconcile both worlds?
Saying mainly that " Sora is a tool to extend creativity " Last point Mira has been mocked and criticised online because as a CTO she wasn't able to say on which public / licensed data Sora has been trained on. Pandera, a data validation library for dataframes, now supports Polars.
Meroxa was created to enable teams of all sizes to deliver real-time data applications. In this episode DeVaris Brown discusses the types of applications that are possible when teams don't have to manage the complex infrastructure necessary to support continuous data flows. Can you describe what Meroxa is and the story behind it?
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. That’s where real-time data, and stream processing can help. We’ll answer the question, “What are datapipelines?”
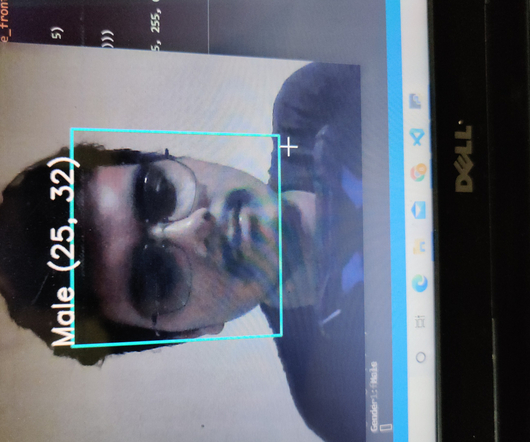
In a data-driven world, behind-the-scenes heroes like data engineers play a crucial role in ensuring smooth data flow. A data engineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines.
We are proud to announce two new analyst reports recognizing Databricks in the data engineering and data streaming space: IDC MarketScape: Worldwide Analytic.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Data lakes are notoriously complex. Join in with the event for the global data community, Data Council Austin.
Data transformations as functions lead to maintainable code 3. Track pipeline progress (logging, Observer) with objects 3.3. Use objects to store configurations of data systems (e.g., Class lets you define reusable code and pipeline patterns 4.1. Class lets you define reusable code and pipeline patterns 4.1.
Introduction Apache Airflow is a crucial component in data orchestration and is known for its capability to handle intricate workflows and automate datapipelines. Many organizations have chosen it due to its flexibility and strong scheduling capabilities.
Is your business incapacitated due to slow and unreliable datapipelines in today’s hyper-competitive environment? Datapipelines are the backbone that guarantees real-time access to critical information for informed and quicker decisions. The datapipeline market is set to grow from USD 6.81
Introduction If you’ve been in the data space long enough, you would have come across really long SQL scripts that someone had written years ago. Split your CTAs/Subquery into separate functions (or models if using dbt) 2.3. Unit test your functions for maintainability and evolution of logic 3. Conclusion 4. Required reading 1.
Here’s where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024—plus a few predictions of my own. 2025 data engineering trends incoming. Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and data engineers (Barr) 8. Table of Contents 1.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content