

Modern Data Engineering with MAGE: Empowering Efficient Data Processing
Analytics Vidhya
JUNE 20, 2023
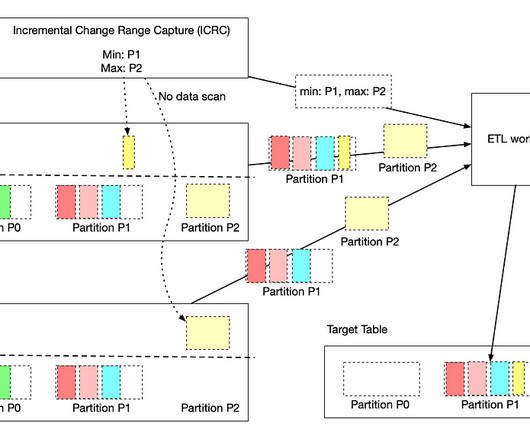
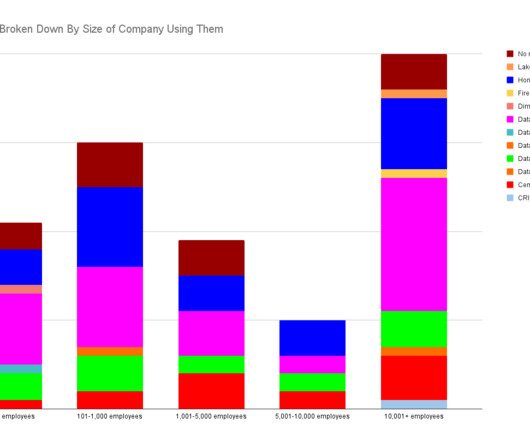
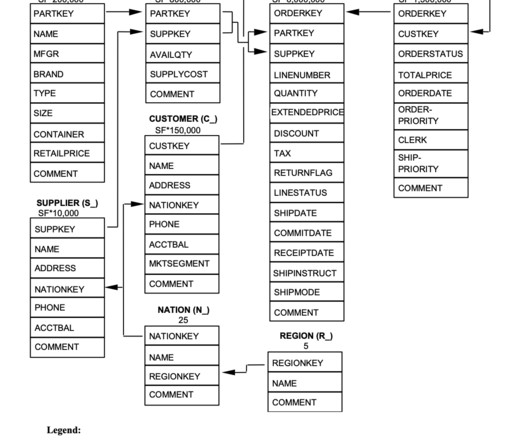
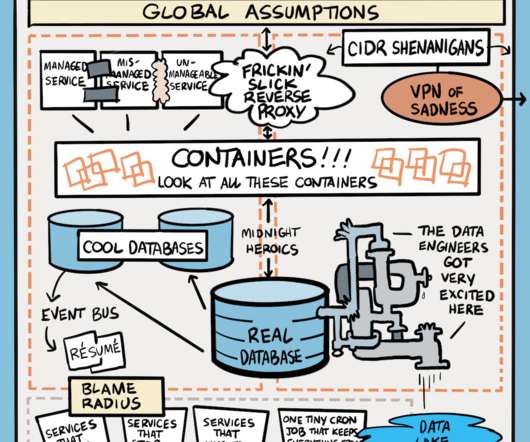
Introduction In today’s data-driven world, organizations across industries are dealing with massive volumes of data, complex pipelines, and the need for efficient data processing.









































Let's personalize your content