This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
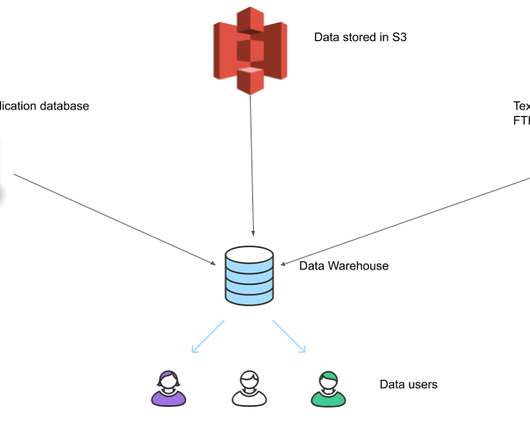
Intro A very common use case in data engineering is to build a ETLsystem for a datawarehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)
Summary The precursor to widespread adoption of cloud datawarehouses was the creation of customer data platforms. Acting as a centralized repository of information about how your customers interact with your organization they drove a wave of analytics about how to improve products based on actual usage data.
Summary Reverse ETL is a product category that evolved from the landscape of customer data platforms with a number of companies offering their own implementation of it. With simple pricing, fast networking, object storage, and worldwide data centers, you’ve got everything you need to run a bulletproof data platform.
In today’s data-driven business world, organizations are looking for more efficient ways to leverage data from a variety of sources. For example, businesses often need to evaluate their performance based on large volumes of customer and sales data that might be stored in a variety of locations and formats.
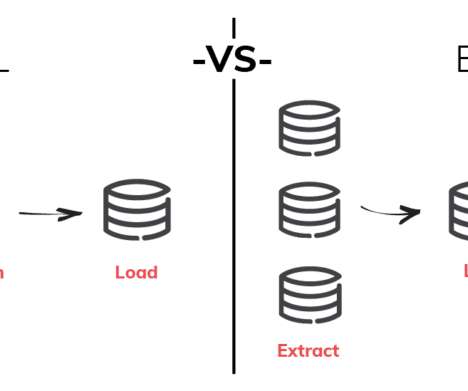
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
Today, organizations are adopting modern ETL tools and approaches to gain as many insights as possible from their data. However, to ensure the accuracy and reliability of such insights, effective ETL testing needs to be performed. So what is an ETL tester’s responsibility? Validate data sources.
Treating batch and streaming as separate pipelines for separate use cases drives up complexity, cost, and ultimately deters data teams from solving business problems that truly require data streaming architectures. Stream processors, storage layers, message brokers, and databases make up the basic components of this architecture.
Hadoop’s significance in data warehousing is progressing rapidly as a transitory platform for extract, transform, and load (ETL) processing. Mention about ETL and eyes glaze over Hadoop as a logical platform for data preparation and transformation as it allows them to manage huge volume, variety, and velocity of data flawlessly.
The contemporary world experiences a huge growth in cloud implementations, consequently leading to a rise in demand for data engineers and IT professionals who are well-equipped with a wide range of application and process expertise. Data Engineer certification will aid in scaling up you knowledge and learning of data engineering.
Data is one of the most valuable assets in most modern organizations. In today’s world, data comes from diverse sources, in different types and formats, and at varying speeds. Those systems are ill-suited to keep pace with businesses that need to ingest and analyze data in real time.
If you are into Data Science or Big Data, you must be familiar with an ETL pipeline. This guide provides definitions, a step-by-step tutorial, and a few best practices to help you understand ETL pipelines and how they differ from data pipelines. How do we transform this data to get valuable insights from it?
Data observability, an organization’s ability to fully understand the health and quality of the data in their systems, has become one of the hottest technologies in modern data engineering. Table of Contents Core Data Observability Use Cases 1. Reduce The Amount Of Data Incidents 2. Validate Data 17.
Data observability, an organization’s ability to fully understand the health and quality of the data in their systems, has become one of the hottest technologies in modern data engineering. Table of Contents Core Data Observability Use Cases 1. Reduce the amount of data incidents 2. Validate data 17.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content