This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By the time I left in 2013, I was a data engineer. We were developing new skills, new ways of doing things, new tools, and — more often than not — turning our backs to traditional methods. We were data engineers! Data Engineering? Like data scientists, data engineers write code. We were pioneers.
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. This understanding forms the basis for effective data transformation.
Amazon Redshift is a serverless, fully managed leading datawarehouse in the market, and many organizations are migrating their legacy data to Redshift for better analytics. In this blog, we will discuss the best Redshift ETLtools that you can use to load data into Redshift.
Are you trying to better understand the plethora of ETLtools available in the market to see if any of them fits your bill? Are you a Snowflake customer (or planning on becoming one) looking to extract and load data from a variety of sources? If any of the above questions apply to you, then […]
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. then you are on the right page.
Once your datawarehouse is built out, the vast majority of your data will have come from other SaaS tools, internal databases, or customer data platforms (CDPs). Spreadsheets are the Swiss army knife of data processing. Does it have a consistent format? How frequently will it change?
Tableau is a robust Business Intelligence tool that helps users visualize data simply and elegantly. Tableau has helped numerous organizations understand their customer data better through their Visual Analytics platform.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Did you know that data is now an essential component of modern business operations? With companies increasingly relying on data-driven insights to make informed decisions, there has never been a greater need for skilled specialists who can manage and evaluate vast amounts of data.
Summary Applications of data have grown well beyond the venerable business intelligence dashboards that organizations have relied on for decades. Given this increased level of importance it has become necessary for everyone in the business to treat data as a product in the same way that software applications have driven the early 2000s.
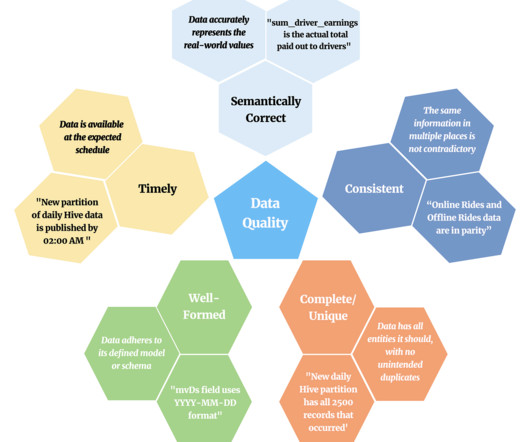
High-quality data is necessary for the success of every data-driven company. It is now the norm for tech companies to have a well-developed data platform. This makes it easy for engineers to generate, transform, store, and analyze data at the petabyte scale. What and Where is Data Quality?
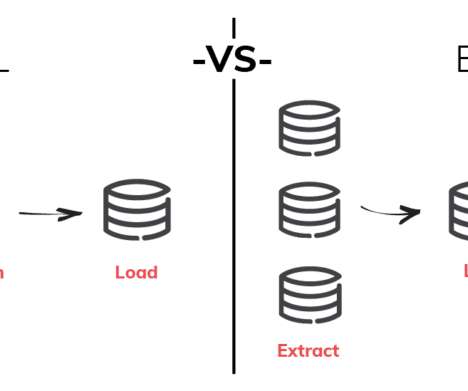
ETL stands for Extract, Transform, and Load. ETL is a process of transferring data from various sources to target destinations/datawarehouses and performing transformations in between to make data analysis ready. Managing data is a tedious task if done manually and leads to no guarantee of accuracy.
Explaining the difference, especially when they both work with something intangible such as data , is difficult. If you’re an executive who has a hard time understanding the underlying processes of data science and get confused with terminology, keep reading. Data science vs data engineering.
AWS Glue is a serverless ETL solution that helps organizations move data into enterprise-class datawarehouses. It provides close integration with other AWS services, which appeals to businesses already invested significantly in AWS.
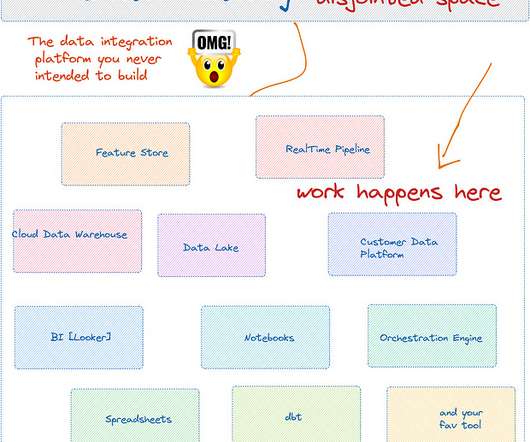
Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern data workflow, not just adding “modern” in its prefix. How happy are you with your data catalogs?
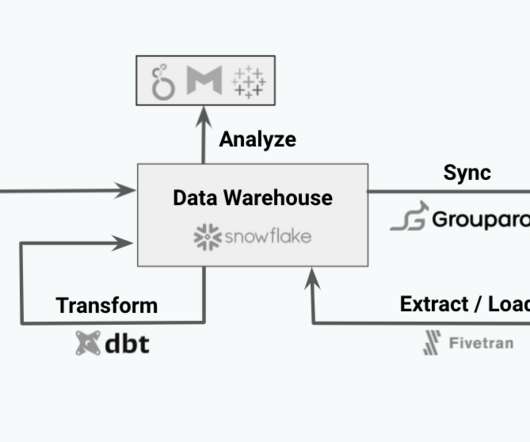
The last three years have seen a remarkable change in data infrastructure. ETL changed towards ELT. Now, data teams are embracing a new approach: reverse ETL. Cloud datawarehouses, such as Snowflake and BigQuery, have made it simpler than ever to combine all of your data into one location.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: data pipeline and ETL. Fast forward to the present day, and we now have data pipelines. However, they are not just an upgraded version of ETL. The data sources themselves are not built to perform analytics.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
ETL is a critical component of success for most data engineering teams, and with teams harnessing it with the power of AWS, the stakes are higher than ever. Data Engineers and Data Scientists require efficient methods for managing large databases, which is why centralized datawarehouses are in high demand.
In today’s data-driven business world, organizations are looking for more efficient ways to leverage data from a variety of sources. For example, businesses often need to evaluate their performance based on large volumes of customer and sales data that might be stored in a variety of locations and formats.
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
Event data for tracking a user’s journey has always been important to product analytics—but we’re now seeing changes in how businesses work with and manage their data, including event data. Next-gen product analytics is now warehouse-native, an architectural approach that allows for the separation of code and data.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. Thus, almost every organization has access to large volumes of rich data and needs “experts” who can generate insights from this rich data.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
In the world of data management, ETL (Extract, Transform, Load) tools play a crucial role in ensuring data is efficiently integrated, transformed, and loaded into datawarehouses. The right ETLtools can significantly streamline […]
Operational analytics is the process of creating data pipelines and datasets to support business teams such as sales, marketing, and customer support. Data analysts and data engineers are responsible for building and maintaining data infrastructure to support many different teams at companies.
ETL developers play a vital role in designing, implementing, and maintaining the processes that help organizations extract valuable business insights from data. What is an ETL Developer? The purpose of ETL is to provide a centralized, consistent view of the data used for reporting and analysis.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Modern platforms like Redshift , Snowflake , and BigQuery have elevated the datawarehouse model.
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
The State of Customer Data The Modern Data Stack is all about making powerful marketing and sales decisions and performing impactful business analytics from a single source of truth. Customer Data Integration makes this possible. In fact, only 34% of marketing teams feel satisfied with their customer data solutions 1.
Businesses are increasingly depending on cloud platforms to manage and analyze their data in today's data-driven environment. Two of the most well-known cloud service providers, Amazon Web Services (AWS) and Microsoft Azure, provide reliable data engineering solutions. Azure Data Factory, Databricks, etc.
Interested in becoming a data engineer? The need for data experts in the U.S. job market is expected to grow by 22% in this decade, and according to LinkedIn’s 2020 report , a data engineer is listed as the 8th fastest growing job today. But what is data engineering exactly and what does a data engineer do?
Data science has become one of the most trending fields today. Data engineering is one of them. According to AnalytixLabs , the data science market is expected to be worth USD 230.80 This demonstrates the increasing need for Microsoft Certified Data Engineers. That’s where data engineers are on the go.
Organizations collect and leverage data on an ever-expanding basis to inform business intelligence and optimize practices. Data allows businesses to gain a greater understanding of their suppliers, customers, and internal processes. What is Data Integrity? This is distinct from factors such as data quality.
Since the inception of the cloud, there has been a massive push to store any and all data. Cloud datawarehouses solve these problems. Belonging to the category of OLAP (online analytical processing) databases, popular datawarehouses like Snowflake, Redshift and Big Query can query one billion rows in less than a minute.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides data pipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Sign up free to test out the tool today. 2 I agree; permission is a mess.
Whether you are a data engineer, BI engineer, data analyst, or an ETL developer, understanding various ETL use cases and applications can help you make the most of your data by unleashing the power and capabilities of ETL in your organization. You have probably heard the saying, "data is the new oil".
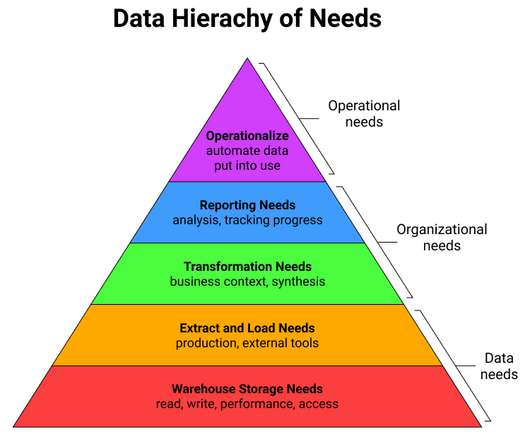
Data stack pyramid I have talked to hundreds of companies investing in their data infrastructure. With the explosion of interest in improved data stacks, companies have been working their way up through these stages. Over the last few years, tools like Snowflake and BigQuery have become the go-to solution in this space.
Learn how we build data lake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. Apache Kafka is an open-source, distributed streaming platform for messaging, storing, processing, and integrating large data volumes in real time. What is Kafka?
The ETLdata integration process has been around for decades and is an integral part of data analytics today. In this article, we’ll look at what goes on in the ETL process and some modern variations that are better suited to our modern, data-driven society. What is ETL?
At the heart of data engineering lies the ETL process—a necessary, if sometimes tedious, set of operations to move data across pipelines for production. Extraction ChatGPT ETL prompts can be used to help write scripts to extract data from different sources, including: Databases I have a SQL database with a table named employees.
To drive deeper business insights and greater revenues, organizations — whether they are big or small — need quality data. But more often than not data is scattered across a myriad of disparate platforms, databases, and file systems. The bad news is, integrating data can become a tedious task, especially when done manually.
The field of data engineering has been growing at a breakneck pace. Keeping up with the latest developments can feel like a full-time job—so we’re always grateful when seasoned leaders share their perspectives on which trends in data engineering actually matter. Plus, he was one of the first data engineers at Facebook and Airbnb.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






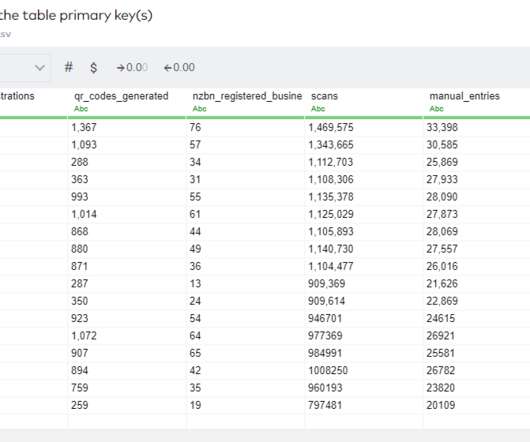






































Let's personalize your content