This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud datawarehouse to Snowflake and some of the benefits they saw.
Data transformations are the engine room of modern data operations — powering innovations in AI, analytics and applications. As the core building blocks of any effective data strategy, these transformations are crucial for constructing robust and scalable data pipelines. This puts data engineers in a critical position.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. As part of this announcement, Snowflake is also announcing private preview support of a new end-to-end data migration experience for Amazon Redshift.
Migrating from a traditional datawarehouse to a cloud data platform is often complex, resource-intensive and costly. As part of this announcement, Snowflake is also announcing private preview support of a new end-to-end data migration experience for Amazon Redshift.
As organizations consolidate analytics workloads to Databricks, they often need to adapt traditional datawarehouse techniques. This series explores how to implement dimensional modelingspecifically, star
Dimensional modeling is a time-tested approach to building analytics-ready datawarehouses. While many organizations are shifting to modern platforms like Databricks, these foundational techniques still
When it comes to generating useful and meaningful insights for business, data is extremely powerful and essential—but only when handled properly. However, only a small percentage of corporate data is analyzed and stored efficiently. Microsoft offers Azure SQLDataWarehouse, a cloud-based data warehousing solution.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
Introduction Data is the new oil in this century. The database is the major element of a data science project. So, we are […] The post How to Normalize Relational Databases With SQL Code? So, we are […] The post How to Normalize Relational Databases With SQL Code? appeared first on Analytics Vidhya.
The Data News are here to stay, the format might vary during the year, but here we are for another year. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables. HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. Not really digest.
Wouldn’t it be great to build a datawarehouse on top of affordable storage and scattered files? SSDs and fast storage are expensive, but storing data in a data lake on S3 or R2 is significantly cheaper, allowing you to save a greater amount of essential data. That’s where databases shine, right?
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Are you looking to choose the best cloud datawarehouse for your next big data project? This blog presents a detailed comparison of two of the very famous cloud warehouses - Redshift vs. BigQuery - to help you pick the right solution for your data warehousing needs. billion by 2028 from $21.18
Are you looking for datawarehouse interview questions and answers to prepare for your upcoming interviews? This guide lists top interview questions on the datawarehouse to help you ace your next job interview. The data warehousing market was worth $21.18 What are the different types of datawarehouses?
By 2028, the size of the global market for data warehousing is likely to reach $51.18 The volume of enterprise data generated, including structured data, sensor data, network logs, video and audio feeds, and other unstructured data, is expanding exponentially as businesses diversify their client bases and adopt new technologies.
The demand for skilled data engineers who can build, maintain, and optimize large data infrastructures does not seem to slow down any sooner. At the heart of these data engineering skills lies SQL that helps data engineers manage and manipulate large amounts of data. of data engineer job postings on Indeed?
This results in the generation of so much data daily. This generated data is stored in the database and will maintain it. SQL is a structured query language used to read and write these databases. Introduction In today’s world, technology has increased tremendously, and many people are using the internet.
We’re excited to introduce Lakebridge, a free migration tool that simplifies and accelerates enterprise datawarehouse (EDW) migrations to Databricks SQL. Modernizing from legacy, siloed
The worldwide data warehousing market is expected to be worth more than $30 billion by 2025. Data warehousing and analytics will play a significant role in a company’s future growth and profitability. Table of Contents What is Data Warehousing? Why DataWarehouse Projects Fail? So let's get started!
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable.
The success or failure of a datawarehouse project depends on the time taken to identify the right technology. You are likely to be aware of the two pioneers in datawarehouse technologies, Snowflake and Google BigQuery , if you are a big data developer or simply a business owner who takes big data seriously.
Summary Data transformation is a key activity for all of the organizational roles that interact with data. Because of its importance and outsized impact on what is possible for downstream data consumers it is critical that everyone is able to collaborate seamlessly. Can you describe what SQLMesh is and the story behind it?
With yato you give a folder with SQL queries and it guesses the DAG and runs the queries in the right order. Saying mainly that " Sora is a tool to extend creativity " Last point Mira has been mocked and criticised online because as a CTO she wasn't able to say on which public / licensed data Sora has been trained on.
dbt Core is an open-source framework that helps you organise datawarehouseSQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data! REGISTER Ready to get started?
Think of your datawarehouse like a well-organized library. Thats where datawarehouse schemas come in. A datawarehouse schema is a blueprint for how your data is structured and linkedusually with fact tables (for measurable data) and dimension tables (for descriptive attributes). Total chaos.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Data lakes are notoriously complex. Join in with the event for the global data community, Data Council Austin.
SQL2Fabric Mirroring is a new fully managed service offered by Striim to mirror on premise SQL Databases. It’s a collaborative service between Striim and Microsoft based on Fabric Open Mirroring that enables real-time data replication from on-premise SQL Server databases to Azure Fabric OneLake. Striim automates the rest.
Data is often referred to as the new oil, and just like oil requires refining to become useful fuel, data also needs a similar transformation to unlock its true value. This transformation is where data warehousing tools come into play, acting as the refining process for your data. Why Choose a Data Warehousing Tool?
Data Engineering is gradually becoming a popular career option for young enthusiasts. That's why we've created a comprehensive data engineering roadmap for 2023 to guide you through the essential skills and tools needed to become a successful data engineer. Let's dive into ProjectPro's Data Engineer Roadmap!
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. It's a sobering thought - all that data, driving no value.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Today, businesses use traditional datawarehouses to centralize massive amounts of raw data from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Table of Contents AWS Redshift DataWarehouse Architecture 1. Client Applications 2.
Three Zero-Cost Solutions That Take Hours, NotMonths A data quality certified pipeline. Source: unsplash.com In my career, data quality initiatives have usually meant big changes. Whats more, fixing the data quality issues this way often leads to new problems. Create a custom dashboard for your specific data qualityproblem.
If you are planning to make a career transition into data engineering and want to know how to become a data engineer, this is the perfect place to begin your journey. Beginners will especially find it helpful if they want to know how to become a data engineer from scratch. Table of Contents What is a Data Engineer?
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
In the thought process of making a career transition from ETL developer to data engineer job roles? Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., differ from ETL developer and the additional skills you need to transition from ETL developer to data engineer job roles.
Many enterprises have heterogeneous data platforms and technology stacks across different business units or data domains. For decades, they have been struggling with scale, speed, and correctness required to derive timely, meaningful, and actionable insights from vast and diverse big data environments.
Data modeling is a crucial skill for every big data professional, but it can be challenging to master. So, if you are preparing for a data modelling interview, you have landed on the right page. We have compiled the top 50 data modelling interview questions and answers from beginner to advanced levels. billion by 2028.
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the data engineering industry. The blog narrates a few examples of Pipe Syntax in comparison with the SQL queries.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























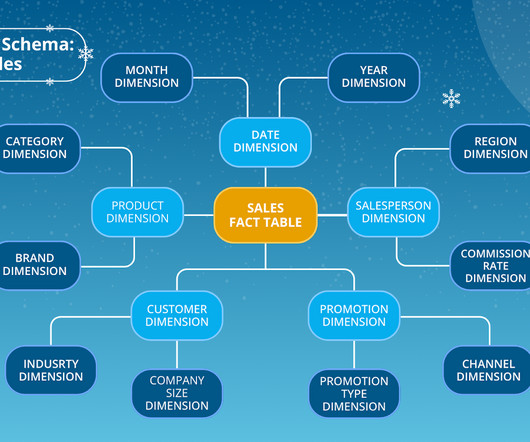



















Let's personalize your content