This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of data storage to store and manage their data effectively.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
Together with a dozen experts and leaders at Snowflake, I have done exactly that, and today we debut the result: the “ Snowflake Data + AI Predictions 2024 ” report. When you’re running a large language model, you need observability into how the model may change as it ingests new data. The next evolution in data is making it AI ready.
Summary Datawarehouses have gone through many transformations, from standard relational databases on powerful hardware, to column oriented storage engines, to the current generation of cloud-native analytical engines. If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen.
Summary Datawarehouse technology has been around for decades and has gone through several generational shifts in that time. The current trends in data warehousing are oriented around cloud native architectures that take advantage of dynamic scaling and the separation of compute and storage.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform.
A datawarehouse is a centralized system that stores, integrates, and analyzes large volumes of structureddata from various sources. It is predicted that more than 200 zettabytes of data will be stored in the global cloud by 2025.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a data lake vs. datawarehouse.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are datawarehouse and big data. Data warehousing offers several advantages.
Data is central to modern business and society. Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly.
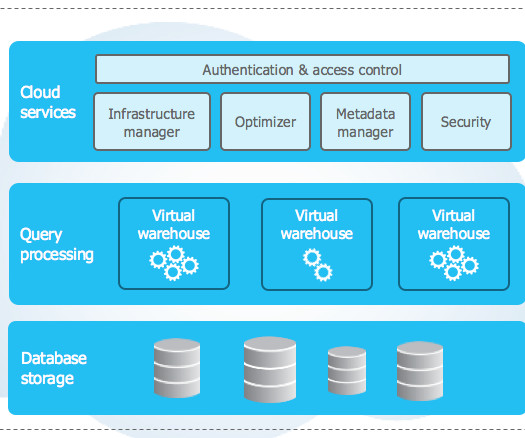
Snowflake DataWarehouse delivers essential infrastructure for handling a Data Lake, and DataWarehouse needs. It can store semi-structured and structureddata in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer. Demand for AI data engineers has grown rapidly in data-driven organizations.
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
The terms “ DataWarehouse ” and “ Data Lake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataWarehouse? .
The modern data stack constantly evolves, with new technologies promising to solve age-old problems like scalability, cost, and data silos. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Data Silos: Breaking down barriers between data sources.
Summary Designing the structure for your datawarehouse is a complex and challenging process. As businesses deal with a growing number of sources and types of information that they need to integrate, they need a data modeling strategy that provides them with flexibility and speed.
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
link] QuantumBlack: Solving data quality for gen AI applications Unstructured data processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructured data is a top question for every organization.
Modern companies are ingesting, storing, transforming, and leveraging more data to drive more decision-making than ever before. Data teams need to balance the need for robust, powerful data platforms with increasing scrutiny on costs. But, the options for data storage are evolving quickly. Let’s dive in.
My personal take on justifying the existence of Data Mesh A senior stakeholder at one my projects mentioned that they wanted to decentralise their data platform architecture and democratise data across the organisation. When I heard the words ‘decentralised data architecture’, I was left utterly confused at first!
Over the past year, data contracts have taken the data world by storm as a novel approach to ensuring data quality at scale in production services. In the last couple of posts , I’ve focused on implementing data contracts in production services. Where to start implementing data contracts?
The real disruption lies with data + AI. In other words, when organizations combine their first-party data with LLMs to unlock unique insights, automate processes, or accelerate specialized workflows. We saw this with software and application observability; data and data observability; and soon data + AI and data + AI observability.
Data pipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Most importantly, these pipelines enable your team to transform data into actionable insights, demonstrating tangible business value.
Summary Working with unstructured data has typically been a motivation for a data lake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable. No more scripts, just SQL.
The challenges Matthew and his team are facing are mainly about access to a multitude of data sets, of various types and sources, with ease and ad-hoc, and their ability to deliver data-driven and confident outcomes. . Most of their research data is unstructured and has a lot of variety. Challenges Ahead.
Introduction Data Engineer is responsible for managing the flow of data to be used to make better business decisions. A solid understanding of relational databases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively. In 2022, data engineering will hold a share of 29.8%
Hadoop is the most talked about innovation in the IT industry that has shaken the entire data centre infrastructure at many organizations. As the appetite for Hadoop and related big data technologies grows at an exponential rate, it is not out to spell the death of data warehousing. Data warehousing as a technology is evolving.
The desire to save every bit and byte of data for future use, to make data-driven decisions is the key to staying ahead in the competitive world of business operations. For the same cost, organizations can now store 50 times as much data as in a Hadoop data lake than in a datawarehouse.
In today’s competitive era, data is a catalyst fueling businesses to grow faster. As data volumes increase, fetching insights from this data comes with its challenges. Sure, you can use lakes and marts to dump any data, but ultimately, deriving business insights requires structureddata with a faster querying experience.
By leveraging an organization’s proprietary data, GenAI models can produce highly relevant and customized outputs that align with the business’s specific needs and objectives. Structureddata is highly organized and formatted in a way that makes it easily searchable in databases and datawarehouses.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Today’s data tool challenges. By enabling their event analysts to monitor and analyze events in real time, as well as directly in their data visualization tool, and also rate and give feedback to the system interactively, they increased their data to insight productivity by a factor of 10. .
In an evolving data landscape, the explosion of new tooling solutions—from cloud-based transforms to data observability —has made the question of “build versus buy” increasingly important for data leaders. Data storage and compute are very much the foundation of your data platform. Let’s jump in!
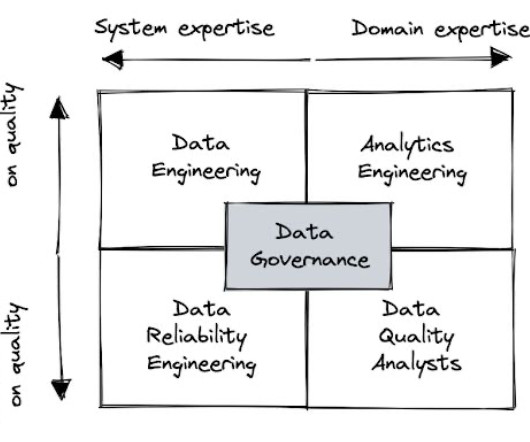
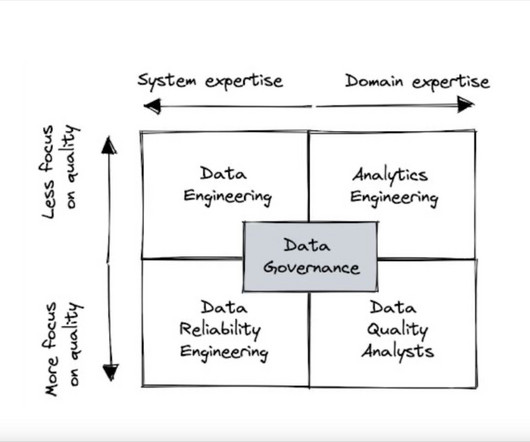
We examine which team structures are the best suited for efficiently improving data quality. Sure, data quality is everyones’ problem. Some organizations will attempt to diffuse the responsibility widely across data stewards, data owners, data engineering and governance committees, each owning a fraction of the data value chain.
Sure, data quality is everyones’ problem. But who is responsible for data quality? Some organizations will attempt to diffuse the responsibility widely across data stewards, data owners, data engineering and governance committees, each owning a fraction of the data value chain.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a data management ecosystem?
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a data management ecosystem?
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a data management ecosystem?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content