This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. What I started as a fun hobby has become one of the top-rated newsletters in the data engineering industry. We are planning many exciting product lines to trial and launch in 2025.
Large language models (LLMs) are transforming how we extract value from this data by running tasks from categorization to summarization and more. While AI has proved that real-time conversations in natural language are possible with LLMs, extracting insights from millions of unstructured data records using these LLMs can be a game changer.
Summary Stripe is a company that relies on data to power their products and business. In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform.
As we approach 2025, data teams find themselves at a pivotal juncture. The rapid evolution of technology and the increasing demand for data-driven insights have placed immense pressure on these teams. The future of data teams depends on their ability to adapt to new challenges and seize emerging opportunities.
dbt is the standard for creating governed, trustworthy datasets on top of your structured data. We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. What is MCP? Why does this matter?
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Key takeaways: New Data Integrity Suite innovations include AI-powered data quality, and new data observability, lineage, location intelligence, and enrichment capabilities. What’s the state of your data integrity journey today? The Suite’s solution AI-powered match and merge, and metadata-driven automation.
Discover 50+ Azure Data Factory interview questions and answers for all experience levels. A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 A report by ResearchAndMarkets projects the global data integration market size to grow from USD 12.24 billion in 2020 to USD 24.84
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. Go to dataengineeringpodcast.com/materialize today to get 2 weeks free!
The challenges around memory, data size, and runtime are exciting to read. Sampling is an obvious strategy for data size, but the layered approach and dynamic inclusion of dependencies are some key techniques I learned with the case study. This count helps to ensure data consistency when deleting and compacting segments.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ?
As we approach 2025, data teams find themselves at a pivotal juncture. The rapid evolution of technology and the increasing demand for data-driven insights have placed immense pressure on these teams. The future of data teams depends on their ability to adapt to new challenges and seize emerging opportunities.
Today, data engineers are constantly dealing with a flood of information and the challenge of turning it into something useful. The journey from raw data to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process.
If you've got tons of data flowing through your systems, you must keep it all organized and running smoothly. It's like the ultimate solution for managing and automating big dataworkflows. Did you know 93% of seasoned Airflow users are willing to recommend this powerful data orchestration tool. Crazy, right?
Summary One of the reasons that data work is so challenging is because no single person or team owns the entire process. This introduces friction in the process of collecting, processing, and using data. In order to reduce the potential for broken pipelines some teams have started to adopt the idea of data contracts.
Summary There are extensive and valuable data sets that are available outside the bounds of your organization. Whether that data is public, paid, or scraped it requires investment and upkeep to acquire and integrate it with your systems. Atlan is the metadata hub for your data ecosystem.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Summary Building a data platform that is enjoyable and accessible for all of its end users is a substantial challenge. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Data lakes are notoriously complex. With Materialize, you can!
For data engineers, this is a monumental undertaking. Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. The only thing worse than having bad data is not knowing that you have it.
As data grows in size and complexity, so does the need for tailored data processing solutions. PySpark User Defined Functions emerge as a powerful tool in this context, offering a customizable approach to data transformation and analysis. Table of Contents What are PySpark User Defined Functions (UDFs)?
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Are you ready to step into the heart of big data projects and take control of data like a pro?
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or data warehouse table that you are working with. Atlan is the metadata hub for your data ecosystem.
Summary There is a constant tension in business data between growing siloes, and breaking them down. Even when a tool is designed to integrate information as a guard against data isolation, it can easily become a silo of its own, where you have to make a point of using it to seek out information.
Summary Data is only valuable if you use it for something, and the first step is knowing that it is available. As organizations grow and data sources proliferate it becomes difficult to keep track of everything, particularly for analysts and data scientists who are not involved with the collection and management of that information.
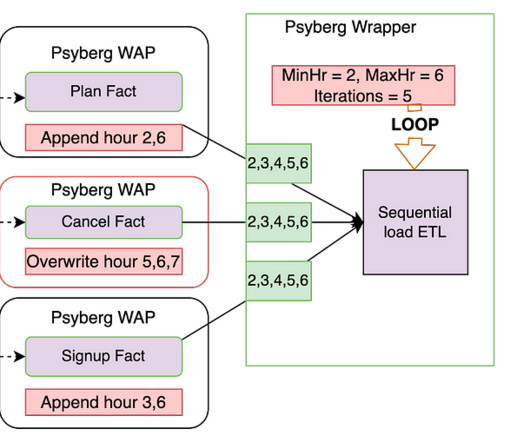
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful Data Processing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. Audit Run various quality checks on the staged data.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. RudderStack’s smart customer data pipeline is warehouse-first. How does it work?
Summary Pandas is a powerful tool for cleaning, transforming, manipulating, or enriching data, among many other potential uses. As a result it has become a standard tool for data engineers for a wide range of applications. Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud.
Summary One of the biggest obstacles to success in delivering data products is cross-team collaboration. This introduces a barrier to communication that is difficult to overcome, particularly in teams that have not reached a significant level of maturity in their data journey.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
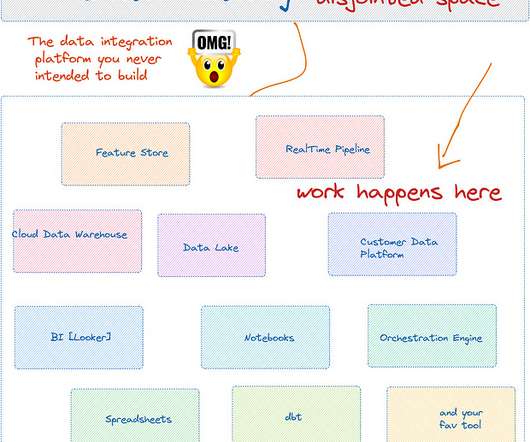
Data catalogs are the most expensive data integration systems you never intended to build. Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. How happy are you with your data catalogs?
Hadoop and Spark are the two most popular platforms for Big Data processing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Which Big Data tasks does Spark solve most effectively? How does it work? cost-effectiveness.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform raw data into actionable insights. In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis.
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps. And don’t forget to thank them for their continued support of this show!
As we reflect on 2024, the data engineering landscape has undergone significant transformations driven by technological advancements, changing business needs, and the meteoric rise of artificial intelligence. This comprehensive analysis examines the key trends and patterns that shaped data engineering practices throughout the year.
Using Artificial Intelligence (AI) in the Data Analytics process is the first step for businesses to understand AI's potential. About 48% of companies now leverage AI to effectively manage and analyze large datasets, underscoring the technology's critical role in modern data utilization strategies. from 2022 to 2030.
In the realm of big data and AI, managing and securing data assets efficiently is crucial. Databricks addresses this challenge with Unity Catalog, a comprehensive governance solution designed to streamline and secure data management across Databricks workspaces. What is Unity Catalog? Advantages of the Unity Catalog 1.
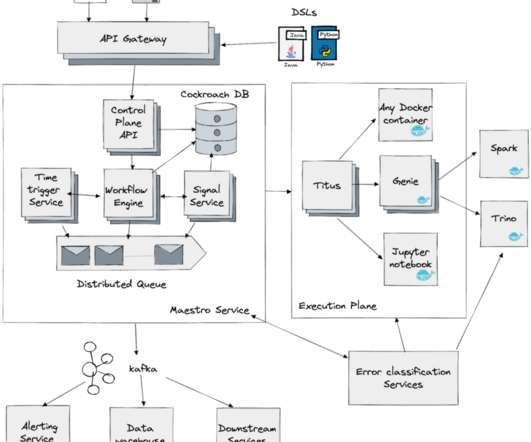
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. 2023 predictions from the panel are; Unified metadata becomes kingmaker.
In this dynamic realm of data engineering, a monumental challenge takes centre stage: efficiently managing the ever-changing tides of real-time data. Data, the lifeblood of organisations, holds the key to unlocking untapped potential and propelling businesses forward. In this blog, we will cover: What Is CDC and Its Benefits?
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. The highlights are that 59% of folks think data catalogs are sometimes helpful.
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to data ingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our data ingestion design.
We are back in our Data Engineering Weekly Radio for edition #120. We will take 2 or 3 articles from each week's Data Engineering Weekly edition and go through an in-depth analysis. We discuss an article by Colin Campbell highlighting the need for a data catalog and the market scope for data contract solutions.
Are you dealing with a scattered data environment, with complex pipelines that seem to go everywhere and nowhere at the same time? Is your data stuck in separate areas within your company, making it hard to use effectively? In other words, you need data orchestration. What Is Data Orchestration?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content